
Clustering of ESTS Test Scores of Students in the Faculty of Science and Technology at Loei Rajabhat University
Article Sidebar
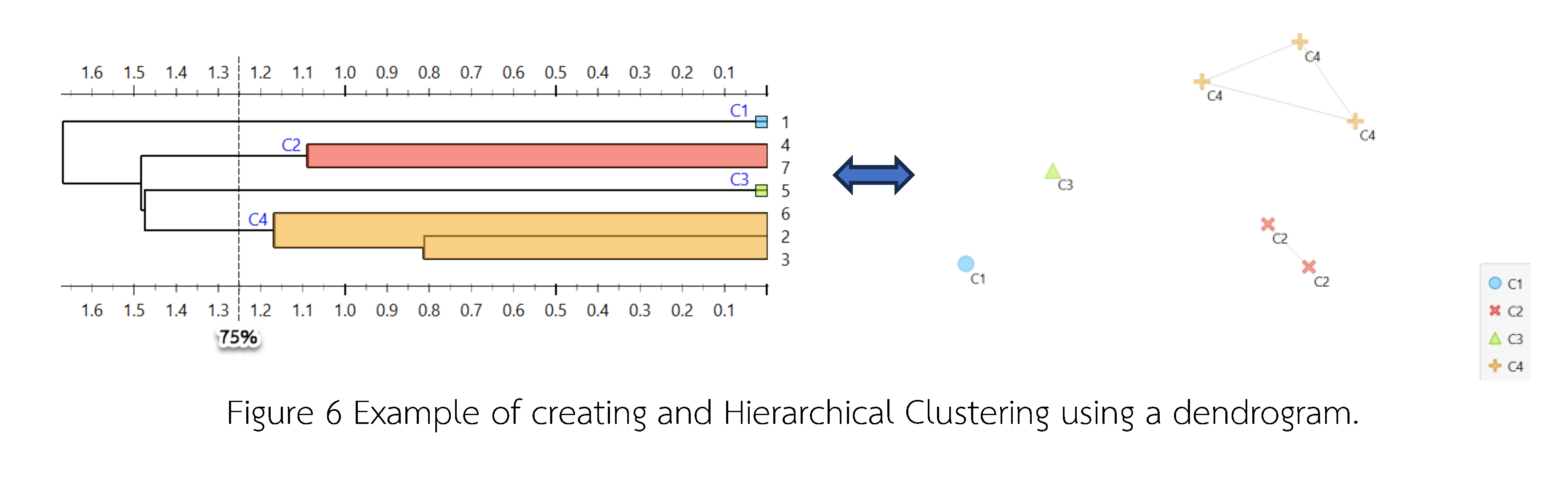
Main Article Content
Abstract
This study aims to develop a web application for reporting English for Science and Technology (ESTS) examination results of students in the Faculty of Science and Technology, Loei Rajabhat University. The focus is on applying information technology to analyze test results and group student data using unsupervised learning via clustering, in order to effectively portray students’ overall English proficiency. The system was developed in PHP with a MySQL database and managed through phpMyAdmin. K-means clustering was employed, experimenting with the number of clusters from 2 to 20, using random initialization and Euclidean distance. Clustering quality was evaluated with the Davies–Bouldin Index (DBI). The experiments show that K = 3 yielded the lowest DBI of 0.82, indicating clear cluster separation. At the same time, increasing the number of clusters reduced the average within-cluster distance and lowered the DBI, suggesting a trend toward more compact and distinct groupings. With this system, users can conveniently access analytically grouped score reports, enabling a comprehensive assessment of students’ proficiency by cluster and supporting the planning of tailored English skill development aligned with learners’ ability levels
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
Baadel, S., Thabtah, F. and Lu, J.(2020). A clustering approach for autistic trait classification. Informatics for Health and Social Care 45(3): 309 - 326. doi: 10.1080/17538157.2019.1687482.
Burrows, C.K., Banovich, N.E., Pavlovic, B.J., Patterson, K., Gallego Romero, I., Pritchard, J.K. and Gilad, Y. (2016). Hierarchical clustering and principal components analysis. PLOS Genetics doi: 10.1371/jo urnal.pgen.1005793.g002.
Chaimuen, O. (2015). A comparative study of the division of Thai handicraft customer data using the 2-step method SOM with K-Mean Algorithm and Hierarchical with K-Mean Algorithm. Master's thesis, Kasetsart University.
Erman, N., Korosec, A. and Suklan, J. (2015). Performance of selected agglomerative hierarchical clustering methods. Innovative Issues and Approaches in Social Sciences 8(1): 180 - 204. doi: 10.12959/issn.1 855-0541.IIASS-2015-no1-art11.
Han, J., Pei, J. and Kamber, M. (2011). Data mining: Concepts and techniques (3rd ed.). U.S.A.: Morgan Kaufmann.
Jain, A.K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters 31(8): 651 - 666. doi: 10.1016/j.patrec.2009.09.011
Köhn, H. F. and Hubert, L. (2014). Hierarchical Cluster Analysis. In Wiley StatsRef: Statistics Reference Online 1 - 13. doi: 10.1002/9781118445112.STAT02449.PUB2.
Phalitsorn, W., Ditsawan, N. and Sangpom, N. (2016). A development management information system for project and research using cluster analysis techniques: Case study Computer Engineering Division in Rajamangala University of Technology Suvarnabhumi. Suvarnabhumi Rajamangala University of Technology.
Phromma, K. (2013). Comparison of data clustering efficiency using 2-step clustering algorithm. Master's thesis, Chulalongkorn University.
Rujasiri, P. (2009). Comparison of clustering techniques for cluster analysis. Master's thesis, Kasetsart University. Bangkok. 378 - 388.
Tsai, C.F., Tsai, C.T., Hung, C.S. and Hwang, P. S. (2011). Data Mining Techniques for Identifying Students at Risk of Failing a Computer Proficiency Test Required for Graduation. Australasian Journal of Educational Technology 27(3): 481 - 498.
Yokkampol, U., Rattanalertnusorn, A. and Jaroengeratikun, U. (2018). A comparison of the efficiency of data clustering using hierarchical methods and k-means methods for mixed data with clusters and numerical data. In: 2018 National Applied Statistics and Information Technology Academic Conference. National Institute of Development Administration. ISBN(e-book): 978-974-231-999-1.
