
การจัดกลุ่มคะแนนสอบ ESTS ของนักศึกษาคณะวิทยาศาสตร์และเทคโนโลยี มหาวิทยาลัยราชภัฏเลย
Article Sidebar
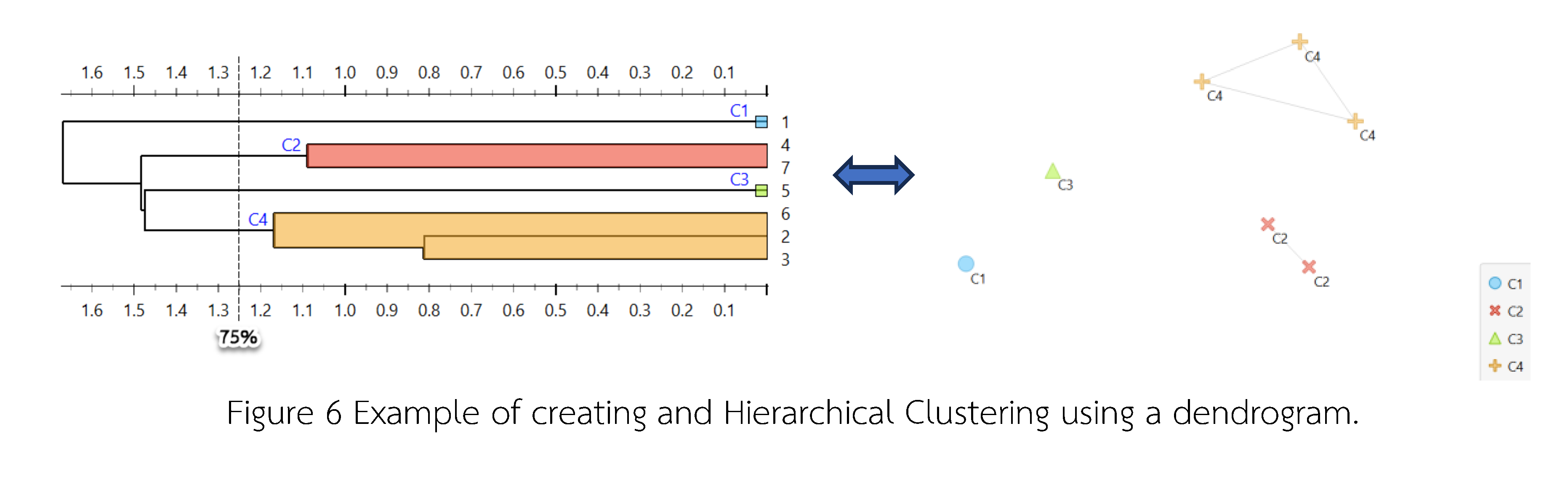
Main Article Content
บทคัดย่อ
การวิจัยครั้งนี้มีวัตถุประสงค์เพื่อพัฒนาเว็บแอปพลิเคชันสำหรับรายงานผลสอบ English for Science and Technology (ESTS) ของนักศึกษา คณะวิทยาศาสตร์และเทคโนโลยี มหาวิทยาลัยราชภัฏเลย โดยมุ่งเน้นการนำเทคโนโลยีสารสนเทศมาใช้ในการวิเคราะห์ผลสอบและจัดกลุ่มข้อมูลนักศึกษาด้วยเทคนิคการเรียนรู้แบบไม่มีผู้สอน (Unsupervised Learning) ผ่านกระบวนการจัดกลุ่มข้อมูล (Clustering) เพื่อสะท้อนภาพรวมของศักยภาพด้านภาษาอังกฤษได้อย่างมีประสิทธิภาพ ระบบดังกล่าวพัฒนาด้วยภาษา PHP ฐานข้อมูล MySQL และใช้ phpMyAdmin เป็นเครื่องมือจัดการฐานข้อมูล โดยได้นำเทคนิคการจัดกลุ่มข้อมูลด้วยอัลกอริทึม K-Means Clustering โดยทำการทดลองจำนวนกลุ่มตั้งแต่ 2 ถึง 20 กลุ่ม ใช้การสุ่มจุดศูนย์กลาง พร้อมการวัดระยะห่างด้วย Euclidean Distance และประเมินคุณภาพการจัดกลุ่มด้วยค่าดัชนี Davies-Bouldin (DBI) ผลการทดลองพบว่า การจัดกลุ่มที่ค่า K = 3 ให้ค่า DBI ต่ำที่สุดที่ 0.82 แสดงถึงประสิทธิภาพในการจำแนกกลุ่มข้อมูลได้อย่างชัดเจน ขณะเดียวกัน การเพิ่มจำนวนคลัสเตอร์ส่งผลให้ค่าเฉลี่ยระยะห่างภายในกลุ่มลดลง และค่า DBI ลดลงตาม ซึ่งบ่งชี้ถึงแนวโน้มของการจัดกลุ่มที่กะทัดรัดและมีความแตกต่างกันมากขึ้น จากการพัฒนาระบบนี้ ผู้ใช้งานสามารถเข้าถึงผลสอบในรูปแบบที่มีการจัดกลุ่มเชิงวิเคราะห์ได้สะดวก ส่งผลให้สามารถประเมินศักยภาพของนักศึกษาแต่ละกลุ่มได้อย่างครอบคลุม และสามารถนำข้อมูลไปใช้ในการวางแผนการพัฒนาทักษะภาษาอังกฤษได้อย่างเหมาะสมกับระดับความสามารถของผู้เรียน
Article Details

อนุญาตภายใต้เงื่อนไข Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
เอกสารอ้างอิง
Baadel, S., Thabtah, F. and Lu, J.(2020). A clustering approach for autistic trait classification. Informatics for Health and Social Care 45(3): 309 - 326. doi: 10.1080/17538157.2019.1687482.
Burrows, C.K., Banovich, N.E., Pavlovic, B.J., Patterson, K., Gallego Romero, I., Pritchard, J.K. and Gilad, Y. (2016). Hierarchical clustering and principal components analysis. PLOS Genetics doi: 10.1371/jo urnal.pgen.1005793.g002.
Chaimuen, O. (2015). A comparative study of the division of Thai handicraft customer data using the 2-step method SOM with K-Mean Algorithm and Hierarchical with K-Mean Algorithm. Master's thesis, Kasetsart University.
Erman, N., Korosec, A. and Suklan, J. (2015). Performance of selected agglomerative hierarchical clustering methods. Innovative Issues and Approaches in Social Sciences 8(1): 180 - 204. doi: 10.12959/issn.1 855-0541.IIASS-2015-no1-art11.
Han, J., Pei, J. and Kamber, M. (2011). Data mining: Concepts and techniques (3rd ed.). U.S.A.: Morgan Kaufmann.
Jain, A.K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters 31(8): 651 - 666. doi: 10.1016/j.patrec.2009.09.011
Köhn, H. F. and Hubert, L. (2014). Hierarchical Cluster Analysis. In Wiley StatsRef: Statistics Reference Online 1 - 13. doi: 10.1002/9781118445112.STAT02449.PUB2.
Phalitsorn, W., Ditsawan, N. and Sangpom, N. (2016). A development management information system for project and research using cluster analysis techniques: Case study Computer Engineering Division in Rajamangala University of Technology Suvarnabhumi. Suvarnabhumi Rajamangala University of Technology.
Phromma, K. (2013). Comparison of data clustering efficiency using 2-step clustering algorithm. Master's thesis, Chulalongkorn University.
Rujasiri, P. (2009). Comparison of clustering techniques for cluster analysis. Master's thesis, Kasetsart University. Bangkok. 378 - 388.
Tsai, C.F., Tsai, C.T., Hung, C.S. and Hwang, P. S. (2011). Data Mining Techniques for Identifying Students at Risk of Failing a Computer Proficiency Test Required for Graduation. Australasian Journal of Educational Technology 27(3): 481 - 498.
Yokkampol, U., Rattanalertnusorn, A. and Jaroengeratikun, U. (2018). A comparison of the efficiency of data clustering using hierarchical methods and k-means methods for mixed data with clusters and numerical data. In: 2018 National Applied Statistics and Information Technology Academic Conference. National Institute of Development Administration. ISBN(e-book): 978-974-231-999-1.
