
Automated Question Answering for Thai Visa Services using GPT-4: System Architecture, Custom Dataset, and Performance Evaluation
Article Sidebar
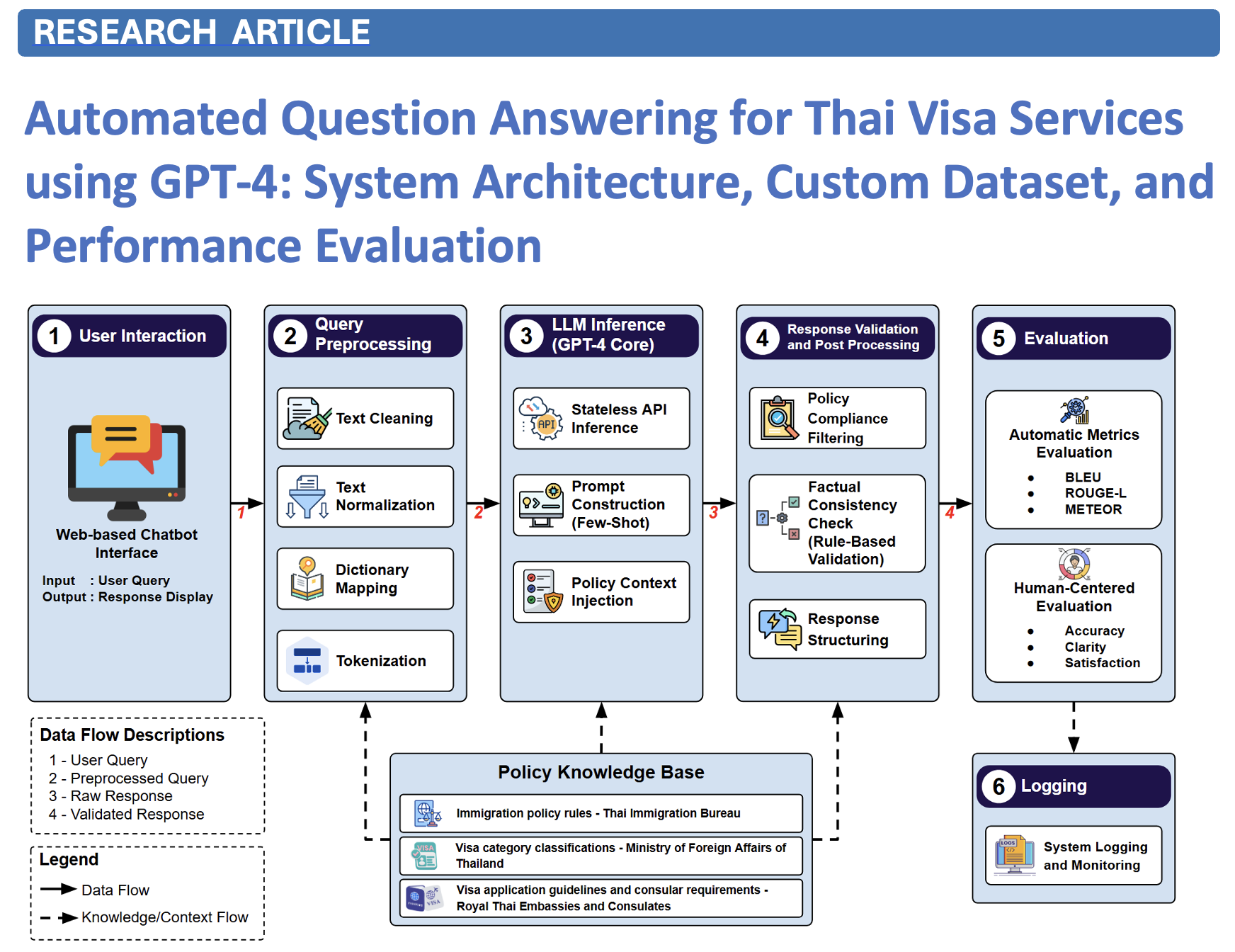
Main Article Content
Abstract
Thailand’s immigration system includes various visa types, such as Tourist (TR), Business (Non-Immigrant B), Education (Non-Immigrant ED), ED Plus, Media (Non-Immigrant M), Official (Non-Immigrant F), Dependent/Spouse (Non-Immigrant O), SMART, Transit, Long-Term Resident (LTR), Retirement (O-A), and Long-Stay Retirement (O-X), each governed by distinct and frequently updated policies. This complexity causes confusion and difficulties for foreign nationals in understanding required documents, eligibility criteria, and policy changes, as shown by a survey involving 75 respondents in Bangkok. Without scalable and accurate solutions, these challenges can reduce service efficiency and public trust. To address this, the study employs GPT-4, a Large Language Model (LLM), optimized with prompt engineering and few-shot learning to automatically answer visa-related questions with accurate, clear, and policy-compliant responses. A simulated dataset of 1,600 question-answer pairs was created from official Thai immigration policies. GPT-4’s performance was systematically evaluated using automatic metrics (BLEU, ROUGE-L, METEOR) and human assessments of accuracy, clarity, and user satisfaction, providing a robust methodological basis for evaluating its effectiveness in public service. Results show strong performance across most categories, with the highest BLEU scores observed in Tourist (0.82), Business (0.81), and Long-Term Resident (LTR) (0.78) visa-related queries. Corresponding peak ROUGE-L scores were 0.86 for Tourist, 0.84 for Business, and 0.81 for Long-Term Resident (LTR) visas, while METEOR scores peaked at 0.79 (Tourist), 0.78 (Business), and 0.76 (Long-Term Resident (LTR)). The system achieved an overall BLEU score of 0.75, ROUGE-L of 0.79, and METEOR of 0.73. Human evaluators rated GPT-4's responses with an average score of 4.5 for accuracy, 4.6 for language clarity, and 4.4 for user satisfaction (on a 5-point scale). A Pearson correlation of 0.78 between BLEU and human-rated accuracy indicates high alignment between automated and human evaluation. These results highlight GPT-4's potential in enhancing public-facing services such as immigration services by providing accurate, clear, and policy-aligned responses. Future work will focus on multilingual support, real-time policy updates, and deployment in live service environments.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
All authors need to complete copyright transfer to Journal of Applied Informatics and Technology prior to publication. For more details click this link: https://ph01.tci-thaijo.org/index.php/jait/copyrightlicense
References
Bahrami, M., Mansoorizadeh, M., and Khotanlou, H. (2023). Few-shot learning with prompting methods. In Proceedings of the 6th International Conference on Pattern Recognition and Image Analysis, pages 1–5, Qom, Iran. DOI: 10.1109/IPRIA59240.2023.10147172.
Barber, S. and Sciortino, R. (2024). Thailand migration report 2024. Technical report, United Nations Network on Migration in Thailand, Bangkok, Thailand. Accessed: 2025-03-18, https://thailand.un.org/en/285915-thailand-migration-report-2024.
Barman, K. G., Lohse, S., and de Regt, H. W. (2025). Reinforcement learning from human feedback in LLMs: Whose culture, whose values, whose perspectives? Philosophy & Technology, 38(35):1–26. DOI: 10.1007/s13347-025-00861-0.
Betrand, C. U., Ekwealor, O. U., and Onyema, C. J. (2023). Artificial intelligence chatbot advisory system. International Journal of Intelligent Information Systems, 12(1):1–9. DOI: 10.11648/j.ijiis.20231201.11.
Bollmann, M., Petran, F., and Dipper, S. (2011). Rule-based normalization of historical texts. In Proceedings of the Workshop on Language Technologies for Digital Humanities and Cultural Heritage, pages 34–42, Hissar, Bulgaria. https://aclanthology.org/W11-4106/.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. (2020). Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pages 1877–1901, Vancouver, Canada. https://dl.acm.org/doi/abs/10.5555/3495724.3495883.
Chowdhury, M. S. R., Khan, N. H., Singha, D., Ahmed, T., Chowdhury, F. H., and Sarkar, M. I. (2024). Streamlining global visa processing and document verification: A self-sovereign identity system for secure and efficient visa processing using hyperledger
indy. In Proceedings of the 2nd International Conference on Information and Communication Technology, pages 120–124, Dhaka, Bangladesh. DOI: 10.1109/ICICT64387.2024.10839648.
Citarella, A. A., Barbella, M., Ciobanu, M. G., Di Marco, F., De Biasi, L., and Tortora, G. (2025). Assessing the effectiveness of ROUGE as unbiased metric in extractive vs. abstractive summarization techniques. Journal of Computational Science, 87:102571. DOI: 10.1016/j.jocs.2025.102571.
Dai, W., Cheng, Y., Aldino, A. A., Tsai, Y.-S., Gaˇsevi´c, D., and Chen, G. (2025). Evaluating the capability of large language models in characterising relational feedback: A comparative analysis of prompting strategies. Computers and Education: Artificial Intelligence, 8:100427. DOI: 10.1016/j.caeai.2025.100427.
Dongbo, M., Miniaoui, S., Fen, L., Althubiti, S. A., and Alsenani, T. R. (2023). Intelligent chatbot interaction system capable for sentimental analysis using hybrid machine learning algorithms. Information Processing & Management, 60(5):103440. DOI: 10.1016/j.ipm.2023.103440.
Gadag, A. and Sagar, B. M. (2016). Paraphrase generator using dictionary lookup for Kannada language. In Proceedings of the 2nd International Conference on Next Generation Computing Technologies, pages 164–168, Dehradun, India. DOI:
1109/NGCT.2016.7877408.
Gao, S., Gao, L., Li, Q., and Xu, J. (2023). Application of large language model in intelligent Q&A of digital government. In Proceedings of the 2nd International Conference on Networks, Communications and Information Technology, pages 24–27, New York, USA. DOI: 10.1145/3605801.3605806.
Gupta, A., Rastogi, A., Malhotra, H., and Rangarajan, K. (2024). Comparative evaluation of large language models for translating radiology reports into Hindi. Indian Journal of Radiology and Imaging, 35(1):88–96. DOI: 10.1055/s-0044-1789618.
Jiang, S., Xie, X., Tang, R., Wang, X., Sun, K., Li, G., Xu, Z., Xue, P., Li, Z., and Fu, X. (2025). ARGUS: Retrieval-augmented QA system for government services. Electronics, 14(12):2445. DOI: 10.3390/electronics14122445.
Konduru, K. K., Natalia, F., Sudirman, S., and AlJumeily, D. (2024). Evaluating few-shot prompting approach using GPT4 in comparison to BERT-variant language models in biomedical named entity recognition. In Proceedings of the 17th International
Conference on Development in eSystem Engineering, pages 340–345, Khorfakkan, United Arab Emirates. DOI: 10.1109/DeSE63988.2024.10911889.
Lai, J., Gan, W., Wu, J., Qi, Z., and Yu, P. S. (2024). Large language models in law: A survey. AI Open, 5:181–196. DOI: 10.1016/j.aiopen.2024.09.002.
Liu, B., Zhu, Z., Ai, Q., Liu, Y., and Wu, Y. (2024a). LeDQA: A chinese legal case document-based question answering dataset. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 5385–5389, Boise, United States. DOI: 10.1145/3627673.3679154.
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., and Zhu, C. (2023). G-EVAL: NLG evaluation using GPT-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore. DOI: 10.18653/v1/2023.emnlp-main.153.
Liu, Y., Meng, R., Bhat, M. M., Joty, S., Xiong, C., Zhou, Y., and Yavuz, S. (2024b). Modeling uncertainty and using post-fusion as fallback improves retrieval augmented generation with LLMs. In Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024), pages 69–82. ACM. DOI: 10.18653/v1/2024.knowllm-1.7.
Lu, Y., Xie, H., Zhang, J., Jin, Y., Feng, Y., and Gong, Y. (2023). Fractal theory based stratified sampling for quality assessment of remote-sensing-derived geospatial data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 16:7100–7111. DOI: 10.1109/JSTARS.2023.3287347.
Mahbub, T., Dghaym, D., Shankarnarayanan, A., Syed, T., Shapsough, S., and Zualkernan, I. (2024). Can GPT-4 aid in detecting ambiguities, inconsistencies, and incompleteness in requirements analysis? A comprehensive case study. IEEE Access, 12:171972–
DOI: 10.1109/ACCESS.2024.3464242.
Mahyoub, M., Wang, Y., and Khasawneh, M. T. (2025). GPT-4o in radiology: In-context learning based automatic generation of radiology impressions. Natural Language Processing Journal, 11:100145. DOI: 10.1016/j.nlp.2025.100145.
Mai, L. and Carson-Berndsen, J. (2024). Enhancing conversation smoothness in language learning chatbots: An evaluation of GPT4 for ASR error correction. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, pages 11001–11005, Seoul, South Korea. DOI: 10.1109/ICASSP48485.2024.10447641.
Naser-Karajah, E. and Arman, N. (2024). Toward automated Arabic synonyms extraction using Arabic lexical substitution. IEEE Access, 12:174455–174463. DOI: 10.1109/ACCESS.2024.3485502.
Olivato, M., Putelli, L., Arici, N., Gerevini, A. E., Lavelli, A., and Serina, I. (2024). Language models for hierarchical classification of radiology reports with attention mechanisms, BERT, and GPT-4. IEEE Access, 12:69710–69727. DOI: 10.1109/ACCESS.2024.3402066.
Onan, A. and Alhumyani, H. (2024). Knowledgeenhanced transformer graph summarization (KETGS): Integrating entity and discourse relations for advanced extractive text summarization. Mathematics, 12(23):3638. DOI: 10.3390/math12233638.
OpenAI (2023). GPT-4 technical report. Technical report, OpenAI. DOI: 10.48550/arXiv.2303.08774.
Raj, P. B. A. S., Piri, J., Eluri, S. B., and S, S. R. (2023). Work visa analysis using machine learning techniques. In Proceedings of the 3rd International Conference on Artificial Intelligence and Smart Energy, pages 616–621, Coimbatore, India. DOI: 10.1109/ICAIS56108.2023.10073837.
Roller, S. and Erk, K. (2016). PIC a different word: A simple model for lexical substitution in context. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1121–1126, San Diego,
California. DOI: 10.18653/v1/N16-1131.
Shahandashti, K. K., Sivakumar, M., Mohajer, M. M., Belle, A. B., Wang, S., and Lethbridge, T. (2024). Assessing the impact of GPT-4 turbo in generating defeaters for assurance cases. In Proceedings of the IEEE/ACM 1st International Conference on AI Foundation Models and Software Engineering, pages 52–56, Lisbon, Portugal. DOI: 10.1145/3650105.3652291.
Sharma, A., Sharma, A., and Bhattacharjee, V. (2023). Breast cancer prediction: Impact of stratified sampling approach on classifier accuracy. In Proceedings of the International Conference on Artificial Intelligence and Smart Communication, pages 1076–1078, Greater Noida, India. DOI: 10.1109/AISC56616.2023.10084954.
Shultz, T. R., Wise, J. M., and Nobandegani, A. S. (2025). Text understanding in GPT-4 versus humans. Royal Society Open Science, 12:241313. DOI: 10.1098/rsos.241313.
Sottana, A., Liang, B., Zou, K., and Yuan, Z. (2023). Evaluation metrics in the era of GPT-4: Reliably evaluating large language models on sequence to sequence tasks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8776–8788, Singapore. DOI: 10.18653/v1/2023.emnlp-main.543.
Sun, J., Zhang, Z., Wang, X., Ji, X., and Zhang, Y. (2024). Fallback prompting guides large language models for accurate responses in complex reasoning. Journal of Networking and Network Applications, 4(3):109–117. https://iecscience.org/jpapers/185.
Swain, D., Chakraborty, K., Dombe, A., Ashture, A., and Valakunde, N. (2018). Prediction of H1B visa using machine learning algorithms. In Proceedings of the International Conference on Advanced Computation and Telecommunication, pages 1–7, Bhopal,
India. DOI: 10.1109/ICACAT.2018.8933628.
Syahidi, A. A. and Kiyokawa, K. (2025). Automatic text generation in Banjar language using GPT-4 for low-resource language preservation. In Proceedings of the IEEE 7th Symposium on Computers and Informatics, pages 238–243, Kuala Lumpur, Malaysia.
DOI: 10.1109/ISCI65687.2025.11167521.
Syahidi, A. A., Kiyokawa, K., and Nuchitprasitchai, S. (2025). A fine-tuned GPT-4-based question answering system for e-government services using a custom-built dataset. In Proceedings of the IEEE 7th Symposium on Computers and Informatics, pages 232–237, Kuala Lumpur, Malaysia. DOI: 10.1109/ISCI65687.2025.11166787.
Uruj, S., Goswami, R., Shetty, S. D., Venkatesan, K., and Ramanujam, K. (2025). Comparative analysis of GPT-4 and LLaMA 3.2 integration with speech processing models for enhancing human-robot interaction and motion control in real-world applications. IEEE Access, 13:127170–127182. DOI: 10.1109/ACCESS.2025.3590592.
Vladika, J., Meisenbacher, S., and Matthes, F. (2025). Lexical substitution is not synonym substitution: On the importance of producing contextually relevant word substitutes. In Proceedings of the 17th International Conference on Agents and Artificial
Intelligence, pages 1–8, Porto, Portugal. DOI: 10.48550/arXiv.2502.04173.
Wolk, K. and Marasek, K. (2014). Enhanced bilingual evaluation understudy. Lecture Notes on Information Theory, 2(2):191–197. DOI: 10.48550/arXiv.1509.09088.
Yanbo, H. and Kongjit, C. (2020). Learning of root cause failure analysis through long-term visa application for Chinese in Thailand. In Proceedings of the Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering, pages 324–329, Pattaya, Thailand. DOI: 10.1109/ECTIDAMTNCON48261.2020.9090712.
Yekta, M. M. J. (2024). The general intelligence of GPT-4, its knowledge diffusive and societal influences, and its governance. Meta-Radiology, 2:100078. DOI: 10.1016/j.metrad.2024.100078.
