
Comparative Analysis of Transformer-Based Models for Extracting Skills from Information Technology Job Posting using Named Entity Recognition
Article Sidebar
Main Article Content
Abstract
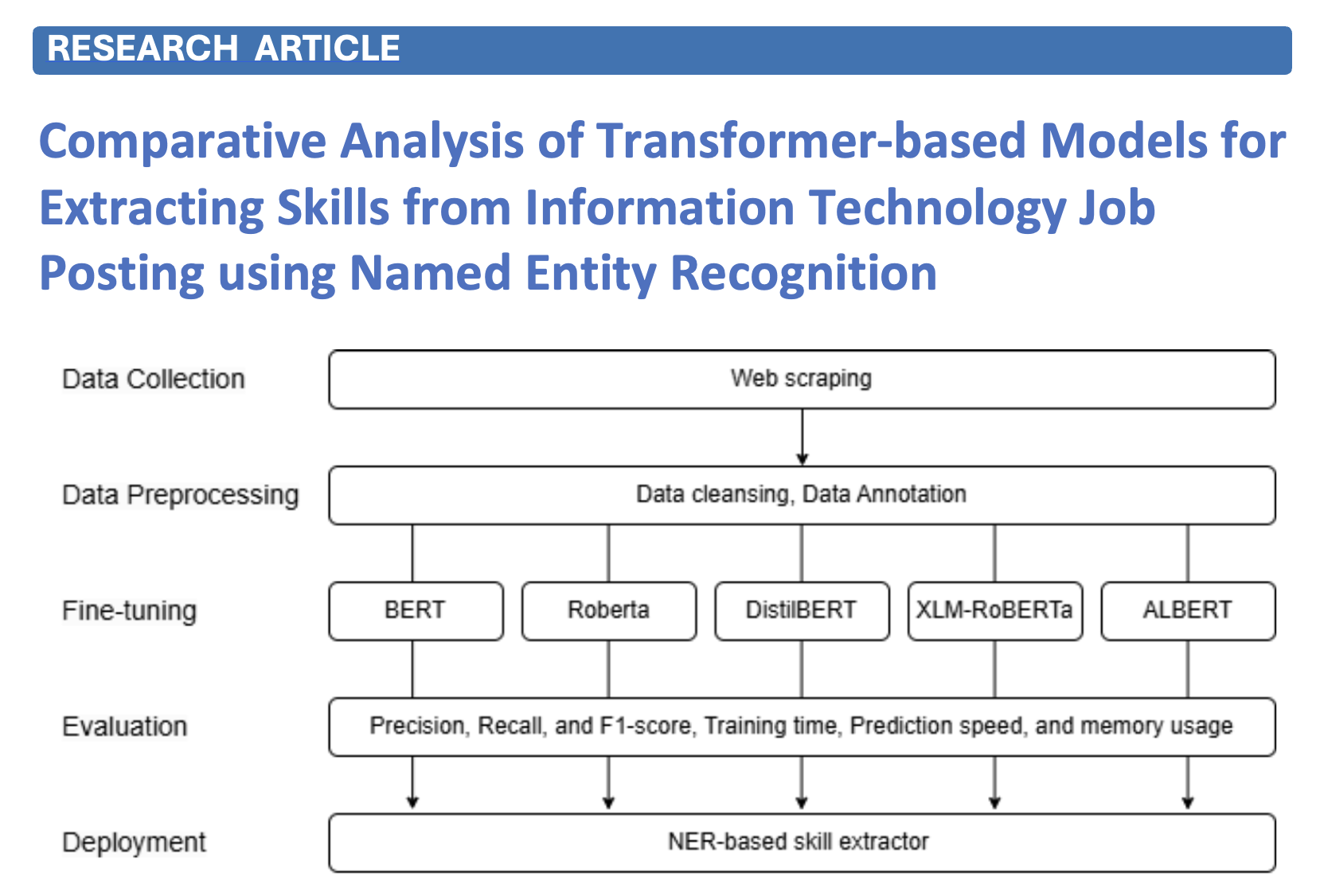
Skill extraction from job postings is critical for labor market analytics and curriculum design, yet it remains challenging due to unstructured text and diverse terminology. This study conducts a comparative evaluation of five Transformer-based Named Entity Recognition (NER) models—BERT, RoBERTa, DistilBERT, ALBERT, and XLM-RoBERTa—using a curated bilingual dataset of information technology job postings annotated with hard and soft skill entities. The methodology involved standardized preprocessing, BIO tagging, and a 70/15/15 train-validation-test split, with model fine-tuning carried out using optimized hyperparameters. Evaluation metrics included precision, recall, and F1-score, alongside computational efficiency measures such as training time, inference speed, and memory usage. Experimental results indicate that BERT achieved the highest F1-score (0.90–0.91), while DistilBERT delivered a favorable balance between accuracy and efficiency, and ALBERT offered moderate performance with reduced resource demands. In contrast, RoBERTa and XLM-RoBERTa underperformed in this domain-specific context. The contributions of this work include establishing a systematic benchmark for Transformer-based NER in IT skill extraction, providing insights into the trade-offs between accuracy and efficiency, and demonstrating practical implications for human resource analytics and curriculum mapping. These findings advance the understanding of model suitability for domain-specific and bilingual skill extraction tasks and lay the foundation for future cross-lingual and cross-domain applications.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
All authors need to complete copyright transfer to Journal of Applied Informatics and Technology prior to publication. For more details click this link: https://ph01.tci-thaijo.org/index.php/jait/copyrightlicense
References
Adnan, K. and Akbar, R. (2019). An analytical study of information extraction from unstructured and multidimensional big data. Journal of Big Data, 6(1):91. DOI: 10.1186/s40537-019-0254-8.
Akkasi, A. (2024). Job description parsing with explainable transformer based ensemble models to extract the technical and non-technical skills. Natural Language Processing Journal, 9:100102. DOI: 10.1016/j.nlp.2024.100102.
Alonso, R., Dessì, D., Meloni, A., and Reforgiato Recupero, D. (2025). A novel approach for job matching and skill recommendation using transformers and the O*NET database. Big Data Research, 39:100509. DOI: 10.1016/j.bdr.2025.100509.
Berragan, C., Singleton, A., Calafiore, A., and Morley, J. (2023). Transformer based named entity recognition for place name extraction from unstructured text. International Journal of Geographical Information Science, 37(4):747–766. DOI: 10.1080/13658816.2022.2133125.
Fareri, S., Melluso, N., Chiarello, F., and Fantoni, G. (2021). SkillNER: Mining and mapping soft skills from any text. Expert Systems with Applications, 184:115544. DOI: 10.1016/j.eswa.2021.115544.
Gao, F., Zhang, L., Wang, W., Zhang, B., Liu, W., Zhang, J., and Xie, L. (2024). Named entity recognition for equipment fault diagnosis based on RoBERTa-wwm-ext and deep learning integration. Electronics, 13(19):3935. DOI: 10.3390/electronics13193935.
García Subies, G., Barbero Jiménez, Á., and Martínez Fernández, P. (2024). A comparative analysis of spanish clinical encoder-based models on NER and classification tasks. Journal of the American Medical Informatics Association, 31(9):2137–2146. DOI: 10.1093/jamia/ocae054.
Gavrilescu, M., Leon, F., and Minea, A.-A. (2025). Techniques for transversal skill classification and relevant keyword extraction from job advertisements. Information, 16(3):167. DOI: 10.3390/info16030167.
Gnehm, A.-S., Bühlmann, E., Buchs, H., and Clematide, S. (2022). Fine-grained extraction and classification of skill requirements in german-speaking job ads. In Proceedings of the Fifth Workshop on Natural Language Processing and Computational Social Science (NLP+CSS), pages 14–24. Association for Computational Linguistics. DOI: 10.18653/v1/2022.nlpcss-1.2.
Gonzalez-Gomez, L. J., Hernandez-Munoz, S. M., Borja, A., Arana-Salas, F. A., Azofeifa, J. D., Noguez, J., and Caratozzolo, P. (2025). Dynamic taxonomy generation for future skills identification using a named entity recognition and relation extraction pipeline. Frontiers in Artificial Intelligence, 8:1579998. DOI: 10.3389/frai.2025.1579998.
Kavargyris, D. C., Georgiou, K., Papaioannou, E., Petrakis, K., Mittas, N., and Angelis, L. (2025). ESCOX: A tool for skill and occupation extraction using LLMs from unstructured text. Software Impacts, 25:100772. DOI: 10.1016/j.simpa.2025.100772.
Košprdić, M., Prodanović, N., Ljajić, A., Bašaragin, B., and Milošević, N. (2024). From zero to hero: Harnessing transformers for biomedical named entity recognition in zero- and few-shot contexts. Artificial Intelligence in Medicine, 156:102970. DOI: 10.1016/j.artmed.2024.102970.
Landolsi, M. Y., Hlaoua, L., and Ben Romdhane, L. (2023). Information extraction from electronic medical documents: State of the art and future research directions. Knowledge and Information Systems, 65(2):463–516. DOI: 10.1007/s10115-022-01779-1.
Napierała, J. (2024). Enhancing taxonomy-based extraction: Leveraging information from online community platforms for digital skills demand identification in job ads. Statistical Journal of the IAOS, 40(3):591–602. DOI: 10.3233/SJI-230110.
Padmanandam, K., Sunitha, K., Jafari, B. M., Jafari, A., Zhao, M., and Pitla, N. (2024). Customized named entity recognition using Bert for the social learning management system platform courseNetworking. Journal of Computer Science, 20(1):88–95. DOI: 10.3844/jcssp.2024.88.95.
Panzaru, C. and Grama, A. (2025). Towards explicit soft skills labelling in ESCO through semantic NLP analysis. Journal for Labour Market Research, 59:18. DOI: 10.1186/s12651-025-00409-x.
Prenner, J. A. A. and Robbes, R. (2022). Making the most of small software engineering datasets with modern machine learning. IEEE Transactions on Software Engineering, 48(12):5050–5067. DOI: 10.1109/TSE.2021.3135465.
Rahhal, I., Kassou, I., and Ghogho, M. (2024). Data science for job market analysis: A survey on applications and techniques. Expert Systems with Applications, 251:124101. DOI: 10.1016/j.eswa.2024.124101.
Schislyaeva, E. R. and Saychenko, O. A. (2022). Labor market soft skills in the context of digitalization of the economy. Social Sciences, 11(3):91. DOI: 10.3390/socsci11030091.
Shishehgarkhaneh, M. B., Moehler, R. C., Fang, Y., Hijazi, A. A., and Aboutorab, H. (2024). Transformer-based named entity recognition in construction supply chain risk management in Australia. IEEE Access, 12:41829–41851. DOI: 10.1109/ACCESS.2024.3377232.
Silva Barbon, R. and Akabane, A. T. (2022). Towards transfer learning techniques—BERT, Distil-BERT, BERTimbau, and DistilBERTimbau for automatic text classification from different languages: A case study. Sensors, 22(21):8184. DOI: 10.3390/s22218184.
Tentua, M. N., Suprapto, and Afiahayati (2024). NERSkill.Id: Annotated dataset of indonesian’s skill entity recognition. Data in Brief, 53:110192. DOI: 10.1016/j.dib.2024.110192.
Ternikov, A. (2022). Soft and hard skills identification: Insights from IT job advertisements in the CIS region. PeerJ Computer Science, 8:e946. DOI: 10.7717/peerj-cs.946.
Zhang, M., van der Goot, R., Kan, M.-Y., and Plank, B. (2024). NNOSE: Nearest neighbor occupational skill extraction. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 589–608. Association for Computational Linguistics. DOI: 10.18653/v1/2024.eacl-long.35.
