
Detection and Correction of Homophone Errors in Thai Language using Machine Learning Techniques in Courtroom Transcriptions
Article Sidebar
Main Article Content
Abstract
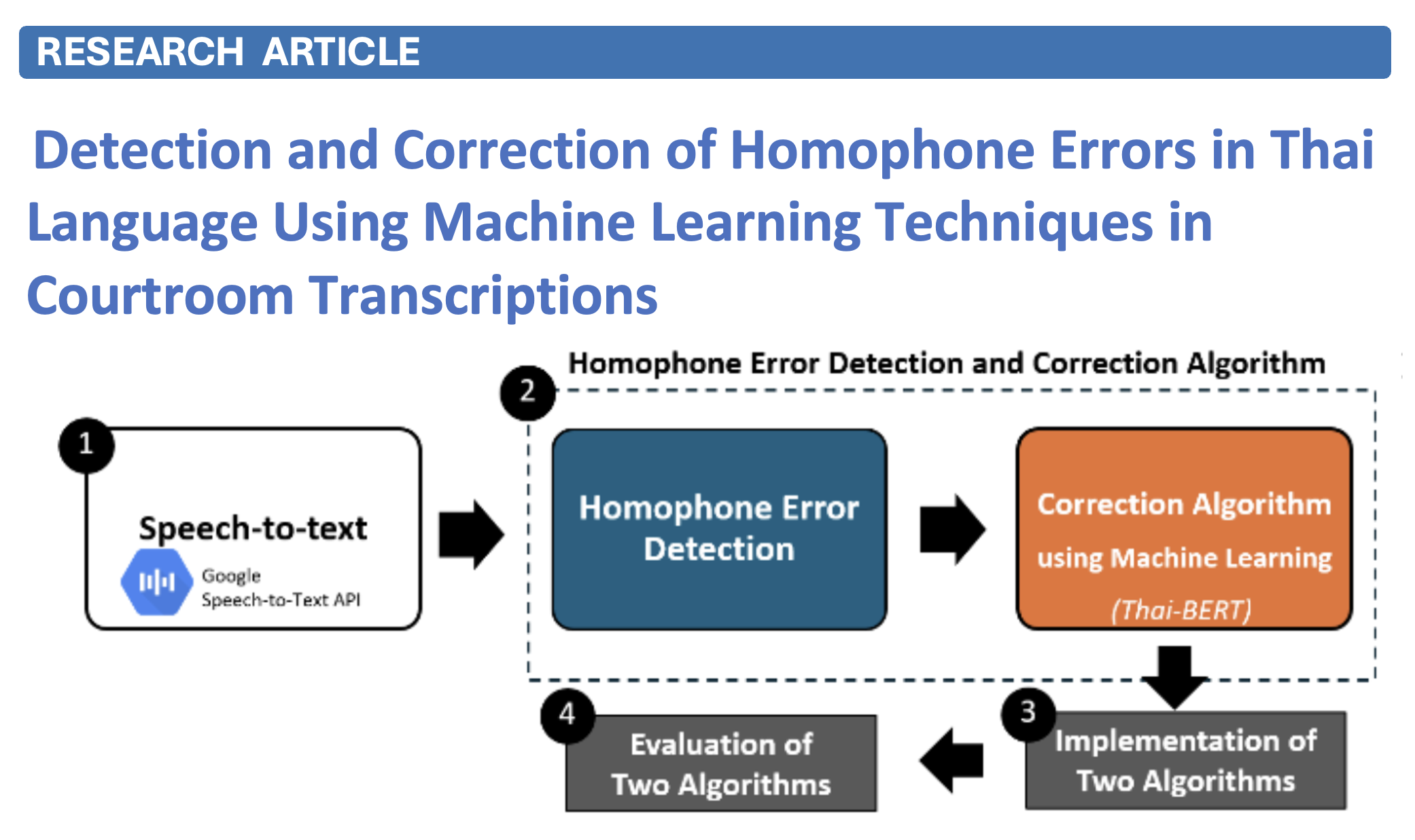
Homophone errors in Thai courtroom transcriptions pose significant challenges in ensuring accurate and reliable legal documentation. Due to the complexity of the Thai language, which includes numerous homophones and tonal variations, speech-to-text (STT) systems often struggle to distinguish between phonetically similar words in legal discourse. This study aims to enhance Thai courtroom transcription accuracy by detecting and correcting homophone errors using machine learning (ML) techniques. The research integrates Google’s Speech-to-Text API with an ML-based correction model that utilizes deep learning architectures, including Thai-BERT and Transformer-based models. The proposed approach employs contextual analysis, a domain-specific Thai Legal Term Dictionary, and post-processing algorithms to refine transcriptions. Experimental results demonstrate that the ML-enhanced system improves homophone detection and correction, increasing overall transcription accuracy from 91.10% to 93.73%, with a homophone correction rate of 71.5%. The evaluation further confirms the model’s effectiveness, achieving a precision of 89.2%, recall of 78.3%, and an F1-score of 83.3%. These findings highlight the potential of integrating machine learning into courtroom transcription workflows, offering a scalable and automated solution for improving judicial documentation. Future work will focus on expanding the dataset with a specialized Thai Legal Speech Corpus, optimizing the model’s adaptability to diverse courtroom environments, and integrating real-time transcription correction systems for enhanced legal applications.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
All authors need to complete copyright transfer to Journal of Applied Informatics and Technology prior to publication. For more details click this link: https://ph01.tci-thaijo.org/index.php/jait/copyrightlicense
References
Agrawal, P., Sharma, K., Dhage, K., Sharma, I., Rakesh, N., and Kaur, G. (2024). Speech-to-text conversion and text summarization. In Proceedings of the 2024 First International Conference on Technological Innovations and Advance Computing (TIACOMP), pages 536–541. IEEE. DOI: 10.1109/TIACOMP64125.2024.00094.
Akarajaradwong, P., Pothavorn, P., Chaksangchaichot, C., Tasawong, P., Nopparatbundit, T., Pratai, K., and Nutanong, S. (2025). NitiBench: Benchmarking LLM frameworks on Thai legal question answering capabilities. In Proceedings of the 2025
Conference on Empirical Methods in Natural Language Processing, pages 34304–34327, Suzhou, China. Association for Computational Linguistics. DOI: 10.18653/v1/2025.emnlp-main.1739.
Ali, A. and Renals, S. (2018). Word error rate estimation for speech recognition: e-WER. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 20–24, Melbourne, Australia. Association for Computational Linguistics. DOI: 10.18653/v1/P18-2004.
Burt, J. S. and Jared, D. (2016). The role of lexical expertise in reading homophones. Quarterly Journal of Experimental Psychology, 69(7):1302–1321. DOI: 10.1080/17470218.2015.1062528.
Garneau, N. and Bolduc, O. (2024). The state of commercial automatic French legal speech recognition systems and their impact on court reporters. arXiv preprint arXiv:2408.11940.
Hämäläinen, M., Patpong, P., Alnajjar, K., Partanen, N., and Rueter, J. (2021). Detecting depression in Thai blog posts: A dataset and a baseline. In Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021), pages 20–25, Online. Association for Computational Linguistics. DOI: 10.18653/v1/2021.wnut-1.3.
Iancu, B. (2019). Evaluating Google speech-to-text API’s performance for Romanian e-learning resources. Informatica Economica, 23(1):17–25. DOI: 10.12948/issn14531305/23.1.2019.02.
Kumar, R., Gupta, M., Sharma, P., Soni, N., and Rawat, K. (2024). NLP-based text-to-speech and speech-to-text virtual assistant. In AIP Conference Proceedings, volume 3072, page 020031. AIP Publishing. DOI: 10.1063/5.0203299.
Phatthiyaphaibun, W., Chaksangchaichot, C., Limkonchotiwat, P., Chuangsuwanich, E., and Nutanong, S. (2022). Thai Wav2Vec2.0 with CommonVoice V8 for ASR. arXiv preprint arXiv:2208.04799.
Sriwirote, P., Thapiang, J., Timtong, V., and Rutherford, A. T. (2023). PhayaThaiBERT: Enhancing a pretrained Thai language model with unassimilated loanwords. arXiv preprint arXiv:2311.12475.
Suwanbandit, A., Naowarat, B., Sangpetch, O., and Chuangsuwanich, E. (2023). Thai dialect corpus and transfer-based curriculum learning investigation for dialect automatic speech recognition. In Proceedings of Interspeech 2023, pages 2958–2962. DOI: 10.21437/Interspeech.2023-1828.
Trivedi, A., Pant, N., Shah, P., Sonik, S., and Agrawal, S. (2018). Speech to text and text to speech recognition systems: A review. IOSR Journal of Computer Engineering, 20(2):36–43.
Wang, Y.-Y., Acero, A., and Chelba, C. (2003). Is word error rate a good indicator for spoken language understanding accuracy. In Proceedings of the 2003 IEEE Workshop on Automatic Speech Recognition and Understanding, pages 577–582, St. Thomas, U.S. Virgin Islands. IEEE. DOI: 10.1109/ASRU.2003.1318504.
Wiratchawa, K., Khunthong, T., and Intharah, T. (2021). LegalBERT-th: Development of legal Q&A dataset and automatic question tagging. In Proceedings of the 2021 18th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), pages 1159–1162, Chiang Mai, Thailand. IEEE. DOI: 10.1109/ECTI-CON51831.2021.9454753.
