
Approximate String Matching Algorithm using Single Inverted Lists
Article Sidebar
Main Article Content
Abstract
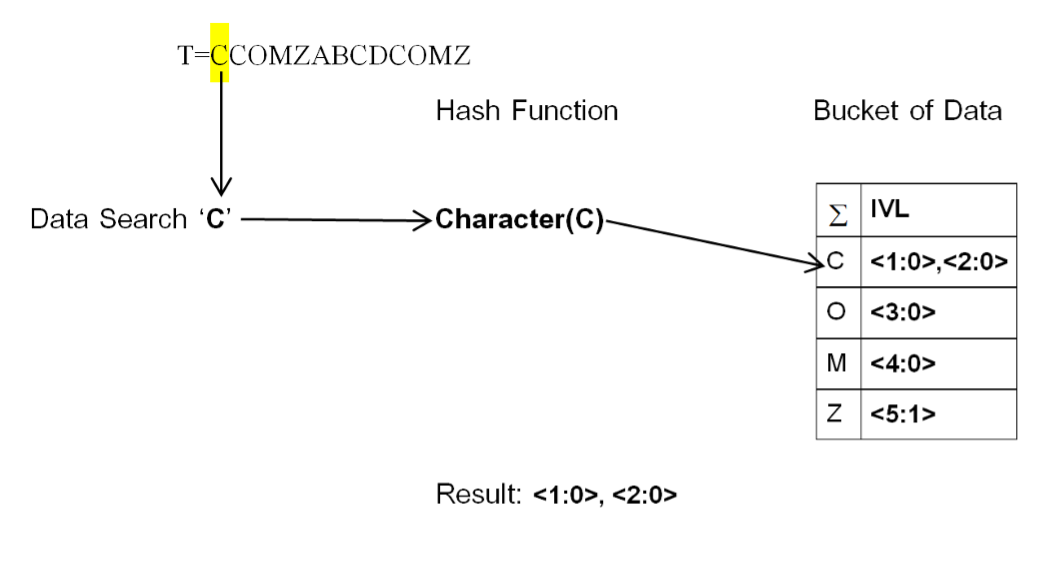
Approximate string matching is a fundamental technique in data retrieval that allows for typo errors or misspellings. It is widely applied in databases, search engines, and various applications or online services. To enhance the speed and accuracy of data retrieval, the development of new algorithms remains a significant challenge in computer science research. This paper introduces a novel data structure for approximate search, called the Single Inverted List, which supports a configurable level of error tolerance. Based on this structure, a new approximate string matching algorithm is developed. Theoretical analysis shows that the proposed structure can be constructed with time complexity proportional to the length of the pattern string and requires storage space equal to the sum of the pattern length and the number of distinct characters. The proposed algorithm achieves search performance with time complexity proportional to the product of the text length and the pattern length, while also supporting error-tolerant matching. Experimental results demonstrate that the proposed structure consumes the least memory compared to well-known existing algorithms, and the developed algorithm performs approximate searches efficiently, nearly as fast as the fastest existing methods, while maintaining linear-time performance.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
All authors need to complete copyright transfer to Journal of Applied Informatics and Technology prior to publication. For more details click this link: https://ph01.tci-thaijo.org/index.php/jait/copyrightlicense




References
Abraham, D., & Raj, N. S. (2014). Approximate string matching algorithm for phishing detection. 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), 2285–2290. https://doi.org/10.1109/icacci.2014.6968578
Boguszewski, A., Szymański, J., & Draszawka, K. (2016). Towards increasing F-measure of approximate string matching in O(1) complexity. Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), 8, 527–532. https://doi.org/10.15439/2016f311
Dondi, R., Mauri, G., & Zoppis, I. (2022). On the complexity of approximately matching a string to a directed graph. Information and Computation, 288, 104748. https://doi.org/10.1016/j.ic.2021.104748
Faro, S., & Scafiti, S. (2022). A weak approach to suffix automata simulation for exact and approximate string matching. Theoretical Computer Science, 933, 88–103. https://doi.org/10.1016/j.tcs.2022.08.028
Gusfield, D. (1997). Algorithms on strings, trees, and sequences: Computer science and computational biology. Cambridge University Press.
Karp, R. M., & Rabin, M. O. (1987). Efficient randomized pattern-matching algorithms. IBM Journal of Research and Development, 31(2), 249–260. https://doi.org/10.1147/rd.312.0249
Khan, M. G., Halim, Z., & Baig, A. R. (2023). An efficient approach for faster matching of approximate patterns in graphs. Knowledge-Based Systems, 276, 110770. https://doi.org/10.1016/j.knosys.2023.110770
Khancome, C., & Boonjing, V. (2010). Inverted Lists String Matching Algorithms. International Journal of Computer Theory and Engineering, 352–357. https://doi.org/10.7763/ijcte.2010.v2.166
Levenshtein, V. (1965). Binary codes capable of correcting spurious insertions and deletions of ones. Problems of Information Transmission, 1(1), 8-17.
Levenshtein, V. I. (1966) Binary codes of correcting deletions, insertions, and reversals. Soviet Physics-Doklady, 10(8), 707-710.
Navarro, G., & Raffinot, M. (2002). Flexible pattern matching in strings: Practical on-line search algorithms for texts and biological sequences. Cambridge University Press.
Needleman, S. B., & Wunsch, C. D. (1970). A general method applicable to the search for similarities in the amino acid sequence of two proteins. Journal of Molecular Biology, 48(3), 443–453. https://doi.org/10.1016/0022-2836(70)90057-4
Smith, T. F., & Waterman, M. S. (1981). Identification of common molecular subsequences. Journal of Molecular Biology, 147(1), 195–197. https://doi.org/10.1016/0022-2836(81)90087-5
Uhlig, F., Struppek, L., Hintersdorf, D., Göbel, T., Baier, H., & Kersting, K. (2023). Combining AI and AM – Improving approximate matching through transformer networks. Forensic Science International: Digital Investigation, 45, 301570
