
RCA on FPGAs Designed by RTL Design Methodology and Wave-Pipelined Operation
Article Sidebar
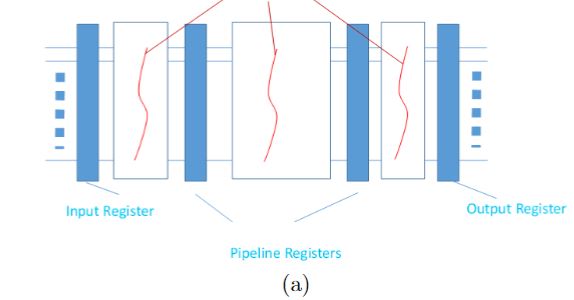
Main Article Content
Abstract
Field-programmable gate arrays (FPGAs) are used in various systems with reconfigurable functions. Conventional FPGAs have been developed using a transistor level description for minimizing routing delay. Although FPGAs developed with a register transfer level (RTL) design methodology provide various benefits to the designers of a system-on-a-chip (SoC), they have not been realized. Therefore, the authors advanced their development. They should be shown to operate with practical throughput. For this purpose, circuits on these device need to be designed and evaluated. In this paper, a ripple-carry adder (RCA) was designed and the throughput of the RCA was evaluated. The resulting throughput was applicable to network processors. Additionally, a wave-pipelined operation without changing the RCA revealed that the problem of routing delay in FPGA developed by RTL methodology was mitigated. The contributions of this paper are to clarify that a 4-bit adder can be implemented on FPGAs and their throughput can be improved by wave-pipelined operations.
Article Details
References
Y. R. Qu and V. K. Prasanna, "High-Performance and Dynamically Updatable Packet Classification Engine on FPGA," IEEE Trans. Parallel Distrib. Sys., vol. 27, no. 1, pp. 197-209. 2016.
T. Sato, S. Imaruoka and M. Fukase, "Verifying Firewall Circuits by Wave-Pipelined Operations," in. Proc. IEEE TENCON 2009, pp. WED3.P.14.1-WED3.P.14.6, 2009.
S. Redif and S. Kasap, "Novel Reconfigurable Hardware Architecture for Polynomial Matrix Multiplications," IEEE Trans. VLSI, vol. 23, no. 3, pp. 254-265, 2015.
H. Marzouqi, M. Al-Qutayri, K. Salah, D. Schinianakis, and T. Stouraitis, "A High-Speed FPGA Implementation of an RSD-Based ECC Processor," IEEE Trans. VLSI, vol. 24, no. 1, pp. 151-164, 2016.
K. Huang, R. Zhao, W. He and Y. Lian, "High-Density and High-Reliability Nonvolatile Field-Programmable Gate Array With Stacked 1D2R RRAM Array," IEEE Trans. VLSI, vol. 24, no. 1, pp. 139-150, 2016.
T. Sato, S. Chivapreecha and P. Moungnou, “A Crossbar Switch Circuit Design for Reconfigurable Wave-Pipelined Circuits,” in. Proc. WMSCI 2014, vol. II, pp. 200-205, 2014.
T. Sato, S. Chivapreecha and P. Moungnoul, “Wiring Control by RTL Design for Reconfigurable Wave-Pipelined Circuits,” in. Proc. APSIPA ASC 2014, pp. WP1-3-1-WP1-3-6, 2014.
T. Sato, S. Chivapreecha and P. Moungnoul, “Fine-Tuning of Wave-Pipelines on FPGAs Developed by the RTL Design,” in Proc. ECTI-CON 21015, pp. 1230.1-1230.6, 2015.
T. Sato, S. Chivapreecha and P. Moungnoul, “The Potential of Routes Configured with the Switch Matrix by RTL,” Applied Mechanics and Materials J., vol. 781, pp. 189-192, 2015.
W. Hong, K.-H. Baek and A. Goudelev, "Multilayer Antenna Package for IEEE 802.11ad Employing Ultralow-Cost FR4," IEEE Trans. Antennas and Propagation, vol. 60, no. 12, pp. 5932-5938, 2012.
H. Sawada; S. Takahashi and S. Kato," Disconnection Probability Improvement by Using Artificial Multi Reflectors for Millimeter-Wave Indoor Wireless Communications," IEEE Trans. Antennas and Propagation, vol. 61, no. 4, pp. 1868-1875, 2013.
A. H. Fazlollahi and J. Chen, "Copper Makes 5G Wireless Access to Indoor Possible," in Proc. 2015 IEEE Global Communications Conference (GLOBECOM), pp. 1-5, 2015.
Y. R. Qu and V. K. Prasanna, "High-Performance and Dynamically Updatable Packet Classification Engine on FPGA," IEEE Trans. Parallel and Distributed Systems, vol. 27, no. 1, pp. 197-209, 2016.
A. Kennedy and X. Wang, "Ultra-High Throughput Low-Power Packet Classification," IEEE Trans. Very Large Scale Integration (VLSI) Systems, vol. 22, no. 2, pp. 286-299, 2016.
G. Brebner and W. Jiang, "High-Speed Packet Processing using Reconfigurable Computing," IEEE Micro, vol. 34, no. 1, pp. 8-18, 2014.
T. Sato, P. Moungnoul, S. Chivapreecha and K. Higuchi, “Performance Estimates of an Embedded CPU for High-Speed Packet Processing,” in Proc. ECTI-CON 2014, pp.1298.1-1298-5, 2014.
L. Cotton, "Maximum Rate Pipelining Systems," in Proc. AFIPS Spring Joint Computer Conference, pp. 581-586, 1969.
F. Klass and M. J. Flynn, "Comparative Studies of Pipelined Circuits," Stanford University Technical Report, no. CSL-TR-93-579, 1993.
I. B. Eduardo, L. Sergio and M. M. Juan, "Some Experiments About Wave Pipelining on FPGA's," IEEE Trans. Very Large Scale Integration (VLSI) Systems, vol. 6, no. 2, pp. 232-237, 1998.
W. P. Burleson, M. Ciesielski, F. Klass, and W. Liu, "Wave-Pipelining: A Tutorial and Research Survey," IEEE Trans. Very Large Scale Integration (VLSI) Systems, vol. 6, no. 3, pp. 464-474, 1998.
Altera Inc., “Using the Internal Oscillator in Altera MAX Series,” https://www.altera.com/en_US/pdfs/literature/an/an496.pdf, 2014.
