
การเปรียบเทียบวิธีการใส่ค่าสูญหายสำหรับอนุกรมเวลาเชิงพหุ กรณีศึกษาดัชนีราคากลุ่มอุตสาหกรรมตลาดหลักทรัพย์แห่งประเทศไทย
Article Sidebar
Main Article Content
บทคัดย่อ
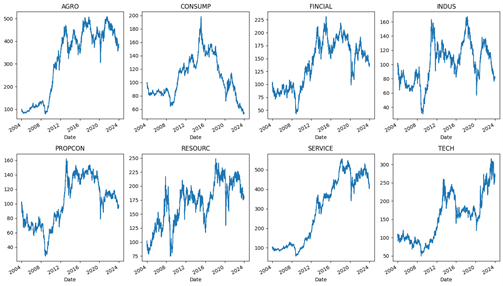
การศึกษานี้มีวัตถุประสงค์เพื่อเปรียบเทียบวิธีการใส่ค่าสูญหายสำหรับอนุกรมเวลาเชิงพหุ และประเมินผลเพื่อเลือกวิธีการใส่ค่าสูญหายที่เหมาะสมที่สุดสำหรับอนุกรมเวลาเชิงพหุ โดยใช้ข้อมูลทุติยภูมิดัชนีราคากลุ่มอุตสาหกรรมของตลาดหลักทรัพย์แห่งประเทศไทย 8 กลุ่มอุตสาหกรรม จากฐานข้อมูล SETSMART ตั้งแต่วันที่ 1 มกราคม พ.ศ. 2547 ถึง 1 มกราคม พ.ศ. 2567 รวมทั้งสิ้น 4,877 วัน ซึ่งได้มีการกำหนดรูปแบบการสูญหายออกเป็น 3 รูปแบบ ได้แก่ การสูญหายรูปแบบสุ่ม การสูญหายรูปแบบช่วงตามลำดับ และการสูญหายรูปแบบบล็อก และกำหนดสัดส่วนการสูญหายของข้อมูลที่ร้อยละ 5 10 20 30 40 และ 50 ตามลำดับ โดยจำแนกวิธีการใส่ค่าสูญหายออกเป็น 3 วิธี ได้แก่ วิธีการใส่ค่าสูญหายด้วยวิธีการเชิงสถิติ ประกอบไปด้วย ค่าเฉลี่ย ค่ามัธยฐาน ข้อมูลสุดท้ายก่อนการสูญหาย (LOCF) ข้อมูลล่าสุดหลังการสูญหาย (NOCB) และการประมาณค่าช่วงเส้นตรง (Linear Interpolation) วิธีการใส่ค่าสูญหายด้วยวิธีการเรียนรู้ของเครื่อง ประกอบไปด้วย ค่าคาดหวังสูงที่สุด (EM) การใส่ค่าสูญหายด้วยการทดแทนแบบพหุคูณด้วยสมการลูกโซ่ (MICE) เพื่อนบ้านใกล้เคียงที่สุด (KNN) และป่าสุ่ม (Random Forest) และวิธีการใส่ค่าสูญหายด้วยวิธีการเรียนรู้เชิงลึก ประกอบไปด้วย GP-VAE USGAN และ SAITS โดยผู้วิจัยเปรียบเทียบประสิทธิภาพของวิธีการใส่ค่าสูญหายด้วยค่ารากที่สองของค่าความคลาดเคลื่อนกำลังสองโดยเฉลี่ย (RMSE) ค่าความคลาดเคลื่อนสัมบูรณ์โดยเฉลี่ย (MAE) และค่าร้อยละความคลาดเคลื่อนสัมบูรณ์โดยเฉลี่ย (MAPE) ผลการศึกษาพบว่า ทุกรูปแบบการสูญหาย กรณีเมื่อสัดส่วนการสูญหายน้อยกว่าร้อยละ 50 การใส่ค่าสูญหายด้วยวิธีการเชิงสถิติโดยการประมาณค่าช่วงเส้นตรง (Linear Interpolation) จะมีประสิทธิภาพสูงที่สุด ส่วนกรณีสัดส่วนการสูญหายเท่ากับร้อยละ 50 พบว่าการใส่ค่าสูญหายด้วยวิธีการเรียนรู้ของเครื่องโดยวิธีป่าสุ่ม (Random Forest) มีประสิทธิภาพสูงที่สุด
Article Details

อนุญาตภายใต้เงื่อนไข Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
เอกสารอ้างอิง
Ahn, H., Sun, K. and Kim, K.P. (2022). Comparison of Missing Data Imputation Methods in Time Series Forecasting. Computers, Materials and Continua 70(1): 767 - 779. doi: 10.32604/cmc.2022.019369.
Almeida, A., Brás, S., Sargento, S. and Pinto, F.C. (2024). Focalize K NN: an imputation algorithm for time series datasets. Pattern Analysis and Applications 27(2): 39. doi: 10.1007/s10044-024-01262-3.
Alruhaymi, A.Z. and Kim, C.J. (2021). Why Can Multiple Imputations and How (MICE) Algorithm Work?. Open Journal of Statistics 11(5): 759 - 777. doi: 10.4236/ojs.2021.115045.
Bernstein, M.N. (2017). Random Forest. Source: https://pages.cs.wisc.edu/~matthewb/pages/notes/pdf/ ensembles/RandomForests. Retrieved date 12 September 2024.
Dong, Q., Chen, X. and Huang, B. (2024). Data Analysis in Pavement Engineering Methodologies and Applications. Cambridge: Woodhead Publishing. 181 - 196.
Du, W. (2023). PyPOTS: A Python Toolbox for Data Mining on Partially-Observed Time Series. arXiv: 2305.18911 doi: 10.48550/arXiv.2305.18811.
Du, W., Côté, D. and Liu, Y. (2023). SAITS: Self-attention-based imputation for time series. Expert Systems With Applications 219: 119619. doi: 10.1016/j.eswa.2023.119619.
Fortuin, V., Baranchuk, D., Rätsch, G. and Mandt S. (2020). GP-VAE: Deep Probabilistic Time Series Imputation. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (AISTATS) 108: 1651 - 1661.
Goldani, M. (2024). Comparative Analysis of Missing Values Imputation Methods: A Case Study in Financial Series (S&P500 and Bitcoin Value Data Sets). Iranian Journal of Finance 1(8): 47 - 70. doi: 10.61186/ijf.2024.414027.1 427.
Hua, V., Nguyen, T., Dao, M., Nguyen, H.D. and Nguyen, B.T. (2024). The impact of data imputation on air quality prediction problem. PLoS ONE 19(9): e0306303. doi: 10.1371/journal.pone.0306303.
Kotu, V. and Deshpande, B. (2019). Data Science Concepts and Practice. (2nd ed.). Cambridge: Morgan Kaufmann Publishers. 395 - 443.
Little, R. and Rubin, D. (2019). Statistical Analysis with Missing Data. (3rd ed.). Hoboken: Wiley Series in Probability and Statistics. 3 - 23.
Miao, X., Wu, Y., Wang, J., Gao, Y., Mao, X. and Yin J. (2021). Generative Semi-supervised Learning for Multivariate Time Series Imputation. Proceedings of the AAAI Conference on Artificial Intelligence 35(10): 8983 - 8991. doi: 10.1609/aaai.v35i10.17086.
Ng, S.K., Krishnan, T. and McLachlan, G.J. (2012). The EM Algorithm. In J.E. Gentle, W.K. Härdle and Y. Mori (Eds.). Handbook of Computational Statistics: Concepts and Methods. Heidelberg: Springer-Verlag. 139 - 172.
