
Development of a Fake Voice Detection Model of Public Figures to Mitigate Disinformation in a Cyber Domain
Article Sidebar
Main Article Content
Abstract
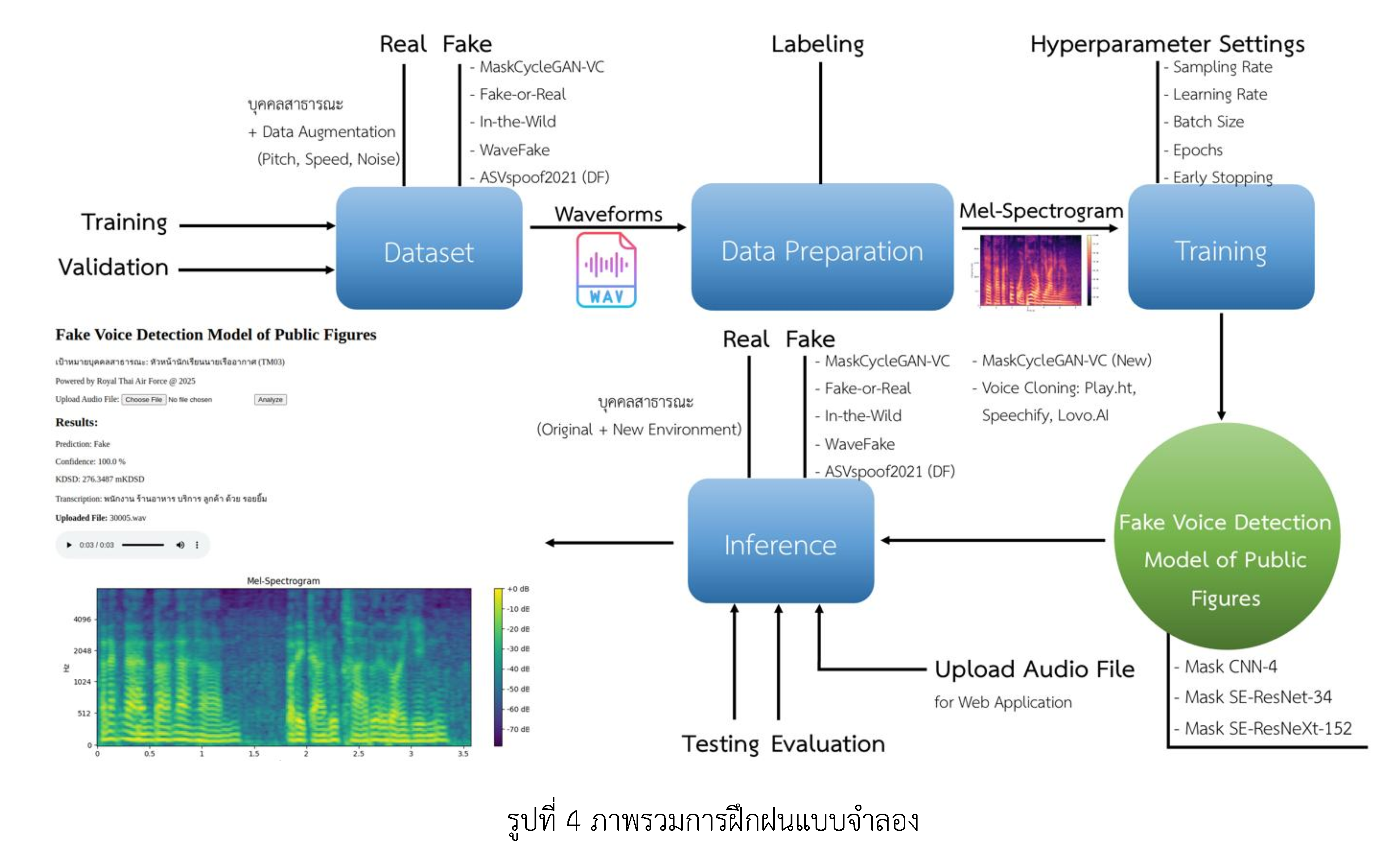
This research aims to 1) investigate approaches for detecting voice spoofing using artificial intelligence (AI), 2) develop an effective model for identifying synthetic voices of public figures, and 3) propose an application framework for defensive cyber operations. The research process included preparing a speech dataset covering multiple spoofing technologies such as Voice Conversion, Voice Cloning, and Text-to-Speech synthesis, with Mel-spectrograms employed for feature extraction. Three deep architectures, Mask CNN-4, Mask SE-ResNet-34, and Mask SE-ResNeXt-152, originally derived from image recognition models, were further extended and customized to build specialized models for distinguishing between genuine and synthetic voices of public figures. Experimental results with testing and evaluation sets, including previously unseen data, showed that all models achieved accurate classification, with Mask SE-ResNeXt-152 yielding the highest performance at 98.33% accuracy under optimized parameters. Furthermore, the model was deployed in a web-based application that presents predictions, confidence scores, Kernel Deep Speech Distance (KDSD), and transcription outputs to support decision-making in cyber defense operations. Real-world testing using the NKRAFA Thai dataset confirmed that the model outperformed human listeners in identifying voice spoofing, reducing the misclassification rates of false acceptance and false rejection from 56% and 41% respectively to zero. These findings demonstrate the strong potential of the proposed model to mitigate disinformation threats in the cyber domain.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
กฤติภูมิ ผลาจันทร์, สุพศิน วงศ์ลาภสุวรรณ, ธนพล รุ่มนุ่ม, สัจจาภรณ์ ไวจรรยา และ ณัฐโชติ พรหมฤทธิ์. (2566). การจำแนกเสียงคนจริงและเสียงสังเคราะห์ปัญญาประดิษฐ์ด้วยโครงข่ายประสาทเทียมแบบคอนโวลูชัน. วารสารวิทยาศาสตร์ มข. 51(2): 170 - 179. doi: 10.14456/kkuscij.2023.15.
ไทยรัฐออนไลน์. (2568). แพทองธาร เผยโดนแก๊งคอลฯ ปลอมเสียงผู้นำประเทศหลอกโอนเงิน สั่ง รมว.ดีอี ตรวจสอบ. แหล่งข้อมูล: https://www.thairath.co.th/news/politic/2836244. ค้นเมื่อวันที่ 10 มีนาคม 2568.
พายัพ ศิรินาม และ ประสงค์ ปราณีตพลกรัง. (2566). การพัฒนาโมเดลการเลียนเสียงเชิงลึกในการประยุกต์ใช้งานด้านสงครามไซเบอร์. วารสารสถาบันวิชาการป้องกันประเทศ 14(1): 162 - 178.
สถาบันส่งเสริมการสอนวิทยาศาสตร์และเทคโนโลยี. (2563). รายวิชาเพิ่มเติมวิทยาศาสตร์และเทคโนโลยี ฟิสิกส์ ชั้นมัธยมศึกษาปีที่ 5 เล่มที่ 4 [ฉบับ e-book]. พิมพ์ครั้งที่ 1. กรุงเทพฯ: สถาบันส่งเสริมการสอนวิทยาศาสตร์และเทคโนโลยี. หน้า 29 - 30.
สำนักงานตำรวจแห่งชาติ. (2567). 4 รูปแบบอาชญากรรมออนไลน์ที่ต้องจับตามองในปี 2567 เมื่อ AI ถูกใช้ในด้านมืด ปลอมได้สารพัด. แหล่งข้อมูล: https://www.facebook.com/photo.php?fbid=766631268843499. ค้นเมื่อวันที่ 10 มีนาคม 2568.
อานนท์ บางเสน และ พายัพ ศิรินาม. (2568). การประยุกต์ใช้เทคโนโลยีปัญญาประดิษฐ์เชิงกำเนิดในการแปลงเสียง. วารสารวิทยาศาสตร์และเทคโนโลยีนายเรืออากาศ 21(2): 135 - 157.
Abdeldayem, M. (2021). The Fake-or-Real (FoR) Dataset (deepfake audio). Source: https://www.kaggle.com /datasets/mohammedabdeldayem/the-fake-or-real-dataset. Retrieved date 14 February 2025.
ASVspoof Consortium. (2021). ASVspoof 2021 Deepfake (DF) database. Source: https://zenodo.org/record/4835108. Retrieved date 14 February 2025.
Barbiero, P., Squillero, G. and Tonda, A. (2020). Modeling generalization in machine learning: A methodological and computational study. arXiv preprint arXiv:2006.15680.
Binkowski, M., Donahue, J., Dieleman, S., Clark, A., Elsen, E., Casagrande, N., Cobo, L. C. and Simonyan, K. (2020). High fidelity speech synthesis with adversarial networks. In: Proceedings of the International Conference on Learning Representations (ICLR 2020). ICLR, Online.
Donahue, C., McAuley, J. and Puckette, M. (2019). Adversarial audio synthesis. In: International Conference on Learning Representations (ICLR) 2019. 1-18.
Fathima, G., Kiruthika, S., Malar, M. and Nivethini, T. (2024). Deepfake Audio Detection Model Based on Mel Spectrogram Using Convolutional Neural Network. International Journal of Creative Research Thoughts (IJCRT) 12(4): 208 - 215.
Frank, J. and Schönherr, L. (2021). WaveFake: A Data Set to Facilitate Audio Deepfake Detection. In: NeurIPS Datasets and Benchmarks Track 2021. NeurIPS Foundation, Online. Source: https://openreview .net/forum?id=IO7jcf63iDI. Retrieved date 14 February 2025.
Gartner. (2025). 2025 Gartner® Market Guide for AI Trust, Risk and Security Management (AI TRiSM). Source: https://www.proofpoint.com/us/resources/analyst-reports/gartner-market-guide-ai-trism. Retrieved date 10 March 2025.
Gohil, M., Yang, H., Tumanov, A., Delimitrou, C. and Venkataraman, S. (2024). Can machine learning models generalize across cloud environments? IEEE Computer Architecture Letters 23(1): 12 - 15.
He, K., Zhang, X., Ren, S. and Sun, J. (2016). Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016). IEEE, Las Vegas, USA. 770-778. doi:10.1109/CVPR.2016.90.
Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D. and Meger, D. (2018). Deep Reinforcement Learning That Matters. In: 32nd AAAI Conference on Artificial Intelligence (AAAI 2018). AAAI Press, New Orleans, USA. 3207-3214.
Hu, J., Shen, L. and Sun, G. (2018). Squeeze-and-excitation networks. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018). IEEE, Salt Lake City, USA. 7132-7141. doi:10.1109/CVPR.2018. 00745.
HuggingFace. (2024). wav2vec2-large-xlsr-53-th. Source: https://huggingface.co/airesearch/wav2vec2-large-xlsr-53-th. Retrieved date 14 February 2025.
Jovanović, M. and Campbell, M. (2022). Generative Artificial Intelligence: Trends and Prospects. IEEE Computer Society 55(10): 107 - 112.
Kaneko, T., Kameoka, H., Tanaka, K. and Hojo, N. (2021). MaskCycleGAN-VC: Learning Non-parallel Voice Conversion with Filling in Frames. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2021). IEEE, Toronto, Canada. 5919 - 5923.
Keskar, N.S., Mudigere, D., Nocedal, J., Smelyanskiy, M., and Tang, P.T.P. (2017). On large-batch training for deep learning: Generalization gap and sharp minima. In: International Conference on Learning Representations (ICLR).
Kong, J., Kim, J. and Bae, J. (2020). HiFi-GAN: Generative adversarial network for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems 33: 17022-17033.
Kumar, K., Kumar, R., de Boissiere, T., Gestin, L., Teoh, W.Z., Sotelo, J., de Brebisson, A., Bengio, Y. and Courville, A. (2019). MelGAN: Generative adversarial networks for conditional waveform synthesis. Advances in Neural Information Processing Systems 32: 14881-14892.
Liu, X., Wang, X., Sahidullah, M., Patino, J., Delgado, H., Kinnunen, T., Todisco, M., Yamagishi, J., Evans, N., Nautsch, A. and Lee, K.A. (2023). ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31: 1 - 17.
LOVO. (2025). AI Voice Cloning & Text to Speech Online Tool. Source: https://lovo.ai. Retrieved date 14 February 2025.
Maas, A.L., Hannun, A.Y. and Ng, A.Y. (2013). Rectifier nonlinearities improve neural network acoustic models. In: 30th International Conference on Machine Learning (ICML 2013). International Machine Learning Society, Atlanta, USA. 1 - 6.
Masters, D., and Luschi, C. (2018). Revisiting small batch training for deep neural networks. arXiv preprint arXiv:1804.07612.
McFee, B., Raffel, C., Liang, D., Ellis, D. P. W., McVicar, M., Battenberg, E. and Nieto, O. (2015). librosa: Audio and music signal analysis in Python. In: 14th Python in Science Conference (SciPy 2015). SciPy, Austin, USA. 18 - 25. doi:10.25080/Majora-7b98e3ed-003.
Mohamed, A. (2022). In-the-Wild Dataset. Source: https://www.kaggle.com/datasets/abdallamohamed 312/in-the-wild-dataset. Retrieved date 14 February 2025.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M. and Duchesnay, E. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12: 2825 - 2830.
Play.ht. (2025). AI Voice Cloning & Text to Speech Online Tool. Source: https://play.ht. Retrieved date 14 February 2025.
Shashank, N., Sathvik, S., Tanmaya, R. and Nethravathi, B. (2024). Enhancing sequence learning with masking in recurrent neural networks. International Research Journal of Modernization in Engineering Technology and Science (IRJMETS) 6(1): 2238 - 2246. doi: 10.56726/IRJMETS48489.
Speechify. (2025). AI Voice Cloning & Text to Speech Online Tool. Source: https://speechify.com. Retrieved date 14 February 2025.
StickCui. (2019). PyTorch-SE-ResNet. Source: https://github.com/StickCui/PyTorch-SE-ResNet/blob/master/ model/model.py. Retrieved date 14 February 2025.
van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A. and Kavukcuoglu, K. (2016). WaveNet: A generative model for raw audio. In: 9th ISCA Speech Synthesis Workshop (SSW9). International Speech Communication Association (ISCA), Sunnyvale, California, USA. 125.
Vanacore, A., Pellegrino, M.S. and Ciardiello, A. (2024). Fair evaluation of classifier predictive performance based on binary confusion matrix. Computational Statistics 39: 363 - 383. doi: 10.1007/s00180-022-01301-9.
Yi, J., Wang, C., Tao, J., Zhang, X., Zhang, C.Y. and Zhao, Y. (2023). Audio Deepfake Detection: A Survey. arXiv preprint arXiv: 2308.14970.
