
A Comparative Study of Statistical Models for News Classification under Imbalanced Data
Article Sidebar
Main Article Content
Abstract
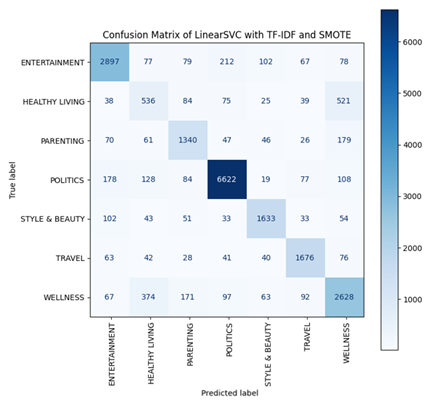
Automatic news classification is an important task in natural language processing, as it facilitates the categorisation and retrieval of information from large news sources. This research aims to compare the performance of machine learning techniques by examining the effects of feature extraction methods and imbalanced data handling. The dataset used in this study is the HuffPost News Category Dataset. Data preparation includes text cleaning, stopword removal, and the combination of news headlines with short descriptions. Features are generated using n-grams and transformed into numerical representations using Bag-of-Words (BoW) and term frequency–inverse document frequency (TF-IDF). Four algorithms are evaluated, namely Multinomial Naive Bayes, Complement Naive Bayes, logistic regression, and linear support vector classification (LinearSVC), using 5-fold cross-validation. The experimental results show that linearsvc combined with tf-idf achieves the highest performance, with an accuracy of 82.64% and an F1-score of 81.87%, while multinomial naive bayes is more suitable for BoW. In addition, the use of bigrams helps reduce ambiguity and provides richer textual context than unigrams. For imbalanced data handling, SMOTE produces better results than adasyn and undersampling, achieving an accuracy of 81.67% and an F1-score of 81.68%. In conclusion, this research provides empirical evidence that using tf-idf together with linearsvc and smote for imbalanced data is a highly effective approach for news classification. These findings can be applied to other types of text classification systems and serve as guidance for future research.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
Alqahtani, A., Ullah Khan, H., Alsubai, S., Sha, M., Almadhor, A., Iqbal, T. and Abbas, S. (2022). An efficient approach for textual data classification using deep learning. Frontiers in computational neuroscience 16: 992296. doi: 10.3389/fncom.2022.992296.
Alrashidi, B., Jamal, A. and Alkhathlan, A. (2023). Abusive Content Detection in Arabic Tweets Using Multi-Task Learning and Transformer-Based Models. Applied Sciences 13(10): 5825. doi: 10.3390/app13105825.
Chowdhury, S. and Schoen, M.P. (2020). Research Paper Classification using Supervised Machine Learning Techniques. In: 2020 Intermountain Engineering, Technology and Computing (IETC). USA: IEEE. 1 - 6. doi: 10.1109/IETC47856.2020.9249211.
Dang, N.C., Moreno-García, M.N. and De la Prieta, F. (2020). Sentiment analysis based on deep learning: A comparative study. Electronics 9(3): 483. doi: 10.3390/electronics9030483.
Devlin, J., Chang, M.W., Lee, K. and Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019). 4171 - 4186. doi: 10.18653/v1/N19-1423.
Fadli, M., Wijaya, V., Pribadi, M.R. and Widhiarso, W. (2023). Effect of TF-IDF Extraction and Application of SMOTE on Model Performance in Detecting Spam Email. In: 2023 10th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Palembang, Indonesia. 637 - 641. doi: 10.1109/EECSI59885.2023.10295851.
Gasparetto, A., Marcuzzo, M., Zangari, A. and Albarelli, A. (2022). A Survey on Text Classification Algorithms: From Text to Predictions. Information 13(2): 83. doi: 10.3390/info13020083.
Graves, L. (2018). Understanding the promise and limits of automated fact-checking (Technical report). Reuters Institute, University of Oxford. doi: 10.60625/risj-nqnx-bg89.
Kim, S.W. and Gil, J.M. (2019). Research paper classification systems based on TF-IDF and LDA schemes. Human-centric Computing and Information Sciences 9: 30. doi: 10.1186/s13673-019-0192-7.
Kuhn, M. and Johnson, K. (2013). Applied predictive modeling. New York: Springer.
Lin, T.Y., Goyal, P., Girshick, R., He, K. and Dollár, P. (2019). Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice. 2980 - 2988. doi: 10.1109/ICCV.2017.324
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L. and Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. arXiv: 1907.11692.
Marr, B. (2018). How much data do we create every day? The mind-blowing stats everyone should read. Source: https://www.forbes.com/. Retrieved date 10 July 2024.
McKinsey and Company. (2014). Five facts: How customer analytics boosts corporate performance. Source: https://www.mckinsey.com/. Retrieved date 28 August 2024.
Mihalcea, R., Corley, C. and Strapparava, C. (2006). Corpus-based and knowledge-based measures of text semantic similarity. In Proceedings of the 21st National Conference on Artificial Intelligence (AAAI-06) (pp. 775 - 780). AAAI Press.
Mikolov, T., Chen, K., Corrado, G. and Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv: 1301.3781. doi: 10.48550/arXiv.1301.3781.
Misra, R. (2022). News category dataset. arXiv: 2209.11429. doi: 10.48550/arXiv.2209.11429.
Mujahidi, M., Kına, E.R.O.L., Rustam, F., Villar, M.G., Alvarado, E.S., De La Torre Diez, I. and Ashraf, I. (2024). Data oversampling and imbalanced datasets: An investigation of performance for machine learning and feature engineering. Journal of Big Data 11(1): 87. doi: 10.1186/s40537-024-00941-x.
Pennington, J., Socher, R. and Manning, C.D. (2014). GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). doi: 10.3115/v1/D14-1162.
Rennie, J.D.M., Shih, L., Teevan, J. and Karger, D.R. (2003). Tackling the poor assumptions of naive Bayes text classifiers. In Proceedings of the 20th International Conference on Machine Learning (ICML-03). 616 - 623. AAAI Press.
Stylianou, N., Chatzakou, D., Tsikrika, T., Vrochidis, S. and Kompatsiaris, I. (2023). Domain-aligned data augmentation for low-resource and imbalanced text classification. In: 45 European Conference on Information Retrieval. Springer-Verlag.
Sun, C., Qiu, X., Xu, Y. and Huang, X. (2019). How to fine-tune BERT for text classification? In: Chinese Computational Linguistics. 194 - 206. doi: 10.48550/arXiv.1905.05583.
Veziroglu, M., Veziroglu, E. and Bucak, I.O. (2024). Performance comparison between Naive Bayes and machine learning algorithms for news classification. In: Bayesian Inference-Recent Trends. IntechOpen. doi: 10.5772/intechopen.1002778.
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R.R. and Le, Q.V. (2019). XLNet: Generalized autoregressive pretraining for language understanding. arXiv: 1906.08237. doi: 10.48550/arXiv.1906.08237.
Zhang, X., Zhao, J. and LeCun, Y. (2015). Character-level convolutional networks for text classification. In: Advances in Neural Information Processing Systems 28 doi: 10.48550/arXiv.1509.01626.
