
การเปรียบเทียบเทคนิคการสุ่มตัวอย่างเพื่อการจำแนกข้อมูลที่ไม่สมดุล
Article Sidebar
Main Article Content
บทคัดย่อ
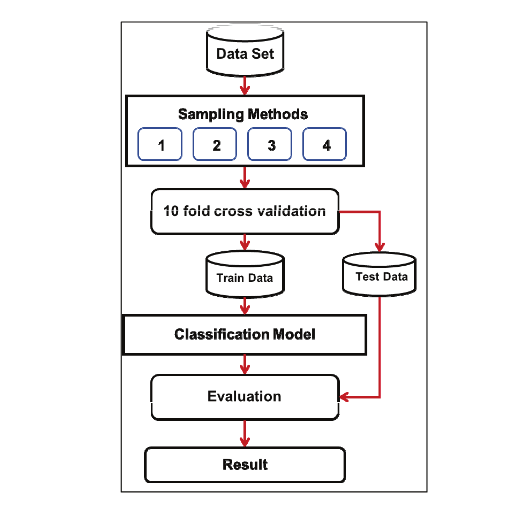
งานวิจัยนี้มีวัตถุประสงค์เพื่อเพิ่มประสิทธิภาพการจำแนกข้อมูลที่ไม่สมดุลด้วยวิธีสุ่มตัวอย่าง ในงานวิจัยได้ทำการทดลองกับข้อมูลจำนวน 12 ชุดข้อมูล ใช้เทคนิคการสุ่มเพิ่มตัวอย่างส่วนน้อย เทคนิคการสุ่มลดตัวอย่างส่วนมาก และเทคนิคการสุ่มตัวอย่างซ้ำสำหรับการปรับปรุงข้อมูลที่ไม่สมดุล ใช้เทคนิคต้นไม้ตัดสินใจ, CART, Random Forest, Support Vector Machine, และ Artificial Neural Network ร่วมกับเทคนิครวมกลุ่ม Adaboost และ Bagging เพื่อสร้างแบบจำลองสำหรับจำแนกข้อมูล ใช้วิธี 10 fold cross validation เพื่อวัดประสิทธิภาพของแบบจำลอง วัดค่าประสิทธิภาพด้วยค่าความแม่นยำ (Accuracy) ค่าความเที่ยงตรง (Precision) ค่าความระลึก (Recall) และค่าเอฟ (F-measure) ผลการวิจัยพบว่าเทคนิคการสุ่มตัวอย่างซ้ำสามารถปรับปรุงข้อมูลที่ไม่สมดุลได้ดีกว่าเทคนิคการสุ่มเพิ่มตัวอย่างส่วนน้อย และแบบจำลอง RF, A+RF และ B+RF มีค่าประสิทธิภาพโดยรวมที่ดี
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
ผู้แต่งจะต้องกรอกข้อมูลเพื่อโอนลิขสิทธิ์ (copyright) ให้กับวารสารวิทยาการสารสนเทศและเทคโนโลยีประยุกต์ ก่อนเผยแพร่บทความ โดยดูรายละเอียดเพิ่มเติมได้ที่ https://ph01.tci-thaijo.org/index.php/jait/copyrightlicense




References
เดช ธรรมศิริและพยุง มีสัจ. (2554). การเรียนรู้แบบรวมกลุ่มด้วยโครงข่ายประสาทเทียมเอดาบูท สำหรับการจำแนกข้อมูล. วารสารเทคโนโลยีสารสนเทศ, 7(14), 7-12.
บรรจบ ดลกุล, จารี ทองคำ และวาทินี สุขมาก. (2557). การสร้างแบบจำลองเพื่อพยากรณ์การเกิดแผลที่เท้าของผู้ป่วยโรคเบาหวานโดยใช้เทคนิคเหมืองข้อมูล. วารสารวิทยาศาสตร์และเทคโนโลยี มหาวิทยาลัยมหาสารคาม, 33(6), 703-710.
ปณต ทรงวัฒนศิริ. (2553). เทคนิคการสุ่มเพิ่มตัวอย่างข้างน้อยสังเคราะห์และเทคนิคการสุ่มลดตัวอย่างข้างมากสำหรับปัญหาความไม่สมดุลระหว่างกลุ่ม. (ปริญญาโท), จุฬาลงกรณ์มหาวิทยาลัย.
ภรัณยา ปาลวิสุทธิ์. (2559). การเพิ่มประสิทธิภาพเทคนิคต้นไม้ตัดสินใจบนชุดข้อมูลที่ไม่สมดุลโดยวิธีการสุ่มเพิ่มตัวอย่างกลุ่มน้อยสำหรับข้อมูลการเป็นโรคติดอินเทอร์เน็ต. วารสารเทคโนโลยีสารสนเทศ, 12(1), 54-63.
ภาสพิชญ์ ชูใจ. (2557). การเรียนรู้ร่วมกันสำหรับปัญหาการจำแนกข้อมูลไม่สมดุล. มหาวิทยาลัยเทคโนโลยีสุรนารี.
ภาสพิชญ์ ชูใจ, นิตยา เกิดประสพ และกิตติศักดิ์ เกิดประสพ. (2557). กระบวนการเตรียมข้อมูลสำหรับข้อมูลไม่สมดุลเพื่อเพิ่มประสิทธิภาพในการจำแนก. การประชุมวิชาการระดับชาติมหาวิทยาลัยเทคโนโลยีราชมงคล ครั้งที่ 6.
วีระยุทธ มายุศิริ, จารี ทองคำ และวาทินี สุขมาก. (2557). การพัฒนาแบบจำลองเพื่อการพยากรณ์การรักษาซ้ำของผู้ป่วยโรคจิตเภทโดยเทคนิคเหมืองข้อมูล. วารสารฉบับพิเศษ ประชุมวิชาการ มหาวิทยาลัยมหาสารคาม, 10, 144-153.
สมภพ ปฐมนพ, กฤษฎา ศรีแผ้ว และ เกษมสันต์, ม. ล. ก. (2555). ข้อมูลเชิงเวลากับการจำแนกประเภทผู้เป็นโรคเบาหวานในประเทศไทย. Journal of Information Science and Technology, 3(2), 14-21.
สุรพงษ์ เชี่ยวสกุลวัฒนา และสุกรี สินธุภิญโญ. (2557). การจำแนกต้นไม้ตัดสินใจสำหรับชุดข้อมูลไม่สมดุลโดยใช้น้ำหนักต่างกันบนข้อมูลสังเคราะห์. การประชุมวิชาการระดับชาติด้านคอมพิวเตอร์และเทคโนโลยีสารสนเทศ ครั้งที่ 10.
เสกสันติ จันทะมงคล, สมจิตร อาจอินทร์, งามนิจ อาจอินทร์ และวัชชพล เดชขันธ์. (2555). ระบบช่วยเหลืออัจฉริยะเพื่อการวางแผนการรักษาโรคเรื้อรังโดยใช้เหมืองข้อมูล. การประชุมวิชาการระดับชาติด้านคอมพิวเตอร์และเทคโนโลยีสารสนเทศ ครั้งที่ 8.
Breiman, L. (1996). Bagging predictors. Machine Learning, 24(2), 123-140.
Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32.
Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). Classification and Regression Trees: Taylor & Francis.
Chawla, N. V. (2005). Data Mining for Imbalanced Datasets: An Overview. In O. Maimon & L. Rokach (Eds.), Data Mining and Knowledge Discovery Handbook (pp. 853-867). Boston, MA: Springer US.
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. J. Artif. Int. Res., 16(1), 321-357.
Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20(3), 273-297.
Efron, B. (1987). Better Bootstrap Confidence Intervals. Journal of the American Statistical Association, 82(397), 171-185.
Freund, Y., & Schapire, R. E. (1997). A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. Journal of Computer and System Sciences, 55(1), 119-139.
Kohavi, R. (1995). A study of cross-validation and bootstrap for accuracy estimation and model selection. Paper presented at the Proceedings of the 14th international joint conference on Artificial intelligence - Volume 2, Montreal, Quebec, Canada.
Larose, D. T., & Larose, C. D. (2014). Neural Networks Discovering Knowledge in Data (pp. 187-208): John Wiley & Sons, Inc.
Meng, X.-H., Huang, Y.-X., Rao, D.-P., Zhang, Q., & Liu, Q. (2013). Comparison of three data mining models for predicting diabetes or prediabetes by risk factors. The Kaohsiung Journal of Medical Sciences, 29(2), 93-99.
Powers D.M.W. (2011). Evaluation : From Precision, Recall and F-measure To ROC, Informedness & Correlation Journal of Machine Learning Technologies, 2(1), pp. 37-63.
Quinlan, J. R. (1986). Induction of Decision Trees. Machine Learning., 1(1), 81-106.
Quinlan, J. R. (1993). C4.5: programs for machine learning: Morgan Kaufmann Publishers Inc.
University of Waikato. (2017). Weka Machine Learning. Retrieved from https://www.cs.waikato.ac.nz/ml/weka/