
Comparison of Sampling Techniques for Imbalanced Data Classification
Article Sidebar
Main Article Content
Abstract
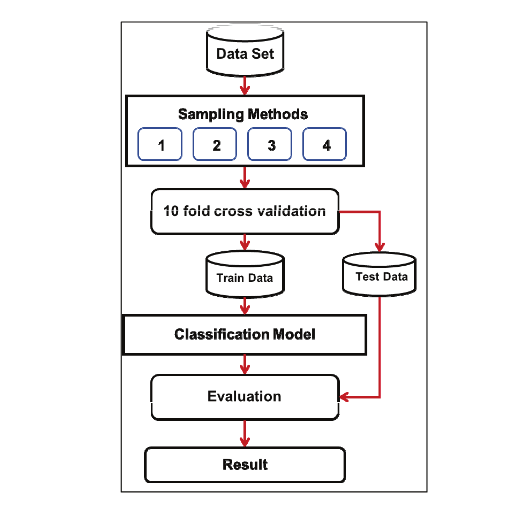
Imbalanced data is a problem in the machine learning process for data classification, which results in low classification efficiency. It has also been found that random sampling techniques are used in several ways for solving low performance problems due to data imbalances. This research aims to compare sampling techniques for imbalanced data classification. The research was conducted on three data sets, which are Synthetic minority over-sampling technique, under-sampling technique and resample techniques for Imbalanced data preprocessing. Decision Tree, cart, random forest, support vector machine and artificial neural network algorithms are ensembled with adaboost and bagging algorithms to create models for data classification. Ten-fold cross validation was used to measure model performance. Performance was measured with precision, recall and f-measure. The results showed that resample techniques could improve the imbalanced data better than synthetic minority over-sampling technique. In addition, it was found that the random forest model, the adaboost ensemble with random forest model and the bagging ensemble with random forest model were efficient for data classification in this research.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
All authors need to complete copyright transfer to Journal of Applied Informatics and Technology prior to publication. For more details click this link: https://ph01.tci-thaijo.org/index.php/jait/copyrightlicense




References
เดช ธรรมศิริและพยุง มีสัจ. (2554). การเรียนรู้แบบรวมกลุ่มด้วยโครงข่ายประสาทเทียมเอดาบูท สำหรับการจำแนกข้อมูล. วารสารเทคโนโลยีสารสนเทศ, 7(14), 7-12.
บรรจบ ดลกุล, จารี ทองคำ และวาทินี สุขมาก. (2557). การสร้างแบบจำลองเพื่อพยากรณ์การเกิดแผลที่เท้าของผู้ป่วยโรคเบาหวานโดยใช้เทคนิคเหมืองข้อมูล. วารสารวิทยาศาสตร์และเทคโนโลยี มหาวิทยาลัยมหาสารคาม, 33(6), 703-710.
ปณต ทรงวัฒนศิริ. (2553). เทคนิคการสุ่มเพิ่มตัวอย่างข้างน้อยสังเคราะห์และเทคนิคการสุ่มลดตัวอย่างข้างมากสำหรับปัญหาความไม่สมดุลระหว่างกลุ่ม. (ปริญญาโท), จุฬาลงกรณ์มหาวิทยาลัย.
ภรัณยา ปาลวิสุทธิ์. (2559). การเพิ่มประสิทธิภาพเทคนิคต้นไม้ตัดสินใจบนชุดข้อมูลที่ไม่สมดุลโดยวิธีการสุ่มเพิ่มตัวอย่างกลุ่มน้อยสำหรับข้อมูลการเป็นโรคติดอินเทอร์เน็ต. วารสารเทคโนโลยีสารสนเทศ, 12(1), 54-63.
ภาสพิชญ์ ชูใจ. (2557). การเรียนรู้ร่วมกันสำหรับปัญหาการจำแนกข้อมูลไม่สมดุล. มหาวิทยาลัยเทคโนโลยีสุรนารี.
ภาสพิชญ์ ชูใจ, นิตยา เกิดประสพ และกิตติศักดิ์ เกิดประสพ. (2557). กระบวนการเตรียมข้อมูลสำหรับข้อมูลไม่สมดุลเพื่อเพิ่มประสิทธิภาพในการจำแนก. การประชุมวิชาการระดับชาติมหาวิทยาลัยเทคโนโลยีราชมงคล ครั้งที่ 6.
วีระยุทธ มายุศิริ, จารี ทองคำ และวาทินี สุขมาก. (2557). การพัฒนาแบบจำลองเพื่อการพยากรณ์การรักษาซ้ำของผู้ป่วยโรคจิตเภทโดยเทคนิคเหมืองข้อมูล. วารสารฉบับพิเศษ ประชุมวิชาการ มหาวิทยาลัยมหาสารคาม, 10, 144-153.
สมภพ ปฐมนพ, กฤษฎา ศรีแผ้ว และ เกษมสันต์, ม. ล. ก. (2555). ข้อมูลเชิงเวลากับการจำแนกประเภทผู้เป็นโรคเบาหวานในประเทศไทย. Journal of Information Science and Technology, 3(2), 14-21.
สุรพงษ์ เชี่ยวสกุลวัฒนา และสุกรี สินธุภิญโญ. (2557). การจำแนกต้นไม้ตัดสินใจสำหรับชุดข้อมูลไม่สมดุลโดยใช้น้ำหนักต่างกันบนข้อมูลสังเคราะห์. การประชุมวิชาการระดับชาติด้านคอมพิวเตอร์และเทคโนโลยีสารสนเทศ ครั้งที่ 10.
เสกสันติ จันทะมงคล, สมจิตร อาจอินทร์, งามนิจ อาจอินทร์ และวัชชพล เดชขันธ์. (2555). ระบบช่วยเหลืออัจฉริยะเพื่อการวางแผนการรักษาโรคเรื้อรังโดยใช้เหมืองข้อมูล. การประชุมวิชาการระดับชาติด้านคอมพิวเตอร์และเทคโนโลยีสารสนเทศ ครั้งที่ 8.
Breiman, L. (1996). Bagging predictors. Machine Learning, 24(2), 123-140.
Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32.
Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). Classification and Regression Trees: Taylor & Francis.
Chawla, N. V. (2005). Data Mining for Imbalanced Datasets: An Overview. In O. Maimon & L. Rokach (Eds.), Data Mining and Knowledge Discovery Handbook (pp. 853-867). Boston, MA: Springer US.
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. J. Artif. Int. Res., 16(1), 321-357.
Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20(3), 273-297.
Efron, B. (1987). Better Bootstrap Confidence Intervals. Journal of the American Statistical Association, 82(397), 171-185.
Freund, Y., & Schapire, R. E. (1997). A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. Journal of Computer and System Sciences, 55(1), 119-139.
Kohavi, R. (1995). A study of cross-validation and bootstrap for accuracy estimation and model selection. Paper presented at the Proceedings of the 14th international joint conference on Artificial intelligence - Volume 2, Montreal, Quebec, Canada.
Larose, D. T., & Larose, C. D. (2014). Neural Networks Discovering Knowledge in Data (pp. 187-208): John Wiley & Sons, Inc.
Meng, X.-H., Huang, Y.-X., Rao, D.-P., Zhang, Q., & Liu, Q. (2013). Comparison of three data mining models for predicting diabetes or prediabetes by risk factors. The Kaohsiung Journal of Medical Sciences, 29(2), 93-99.
Powers D.M.W. (2011). Evaluation : From Precision, Recall and F-measure To ROC, Informedness & Correlation Journal of Machine Learning Technologies, 2(1), pp. 37-63.
Quinlan, J. R. (1986). Induction of Decision Trees. Machine Learning., 1(1), 81-106.
Quinlan, J. R. (1993). C4.5: programs for machine learning: Morgan Kaufmann Publishers Inc.
University of Waikato. (2017). Weka Machine Learning. Retrieved from https://www.cs.waikato.ac.nz/ml/weka/
