
Multi-Speaker Thai Speech Synthesis Using Transfer Learning
Article Sidebar
Main Article Content
Abstract
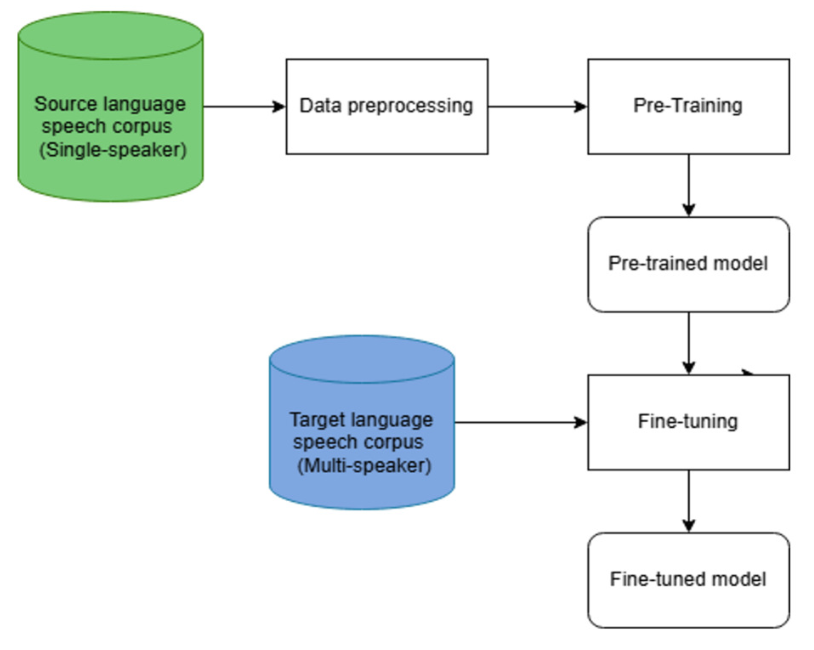
This paper investigates transfer learning for developing a multi-speaker Thai text-to-speech (TTS) system under low-resource conditions, with a focus on cross-lingual knowledge transfer from source languages with different phonological and prosodic characteristics. The model is pre-trained on speech data from Thai, Mandarin Chinese, and English, and subsequently fine-tuned using Thai speech from three target speakers, each with only 1530 minutes of data, covering both male and female speakers. Both objective and subjective evaluations consistently demonstrate that Thai pre-training achieves the best overall performance. Among the cross-lingual models, transfer learning from Mandarin Chinese outperforms transfer from English, yielding lower F0 RMSE (20.79 vs. 21.65) and higher MOS scores (3.55 vs. 3.44). In addition, speaker-dependent analysis indicates that speaker gender has a noticeable influence on synthesis quality under limited data conditions, suggesting that acoustic similarity between pre-training data and target speakers can affect the effectiveness of knowledge transfer. However, this factor is secondary to linguistic and prosodic similarity. Natural speech achieves a MOS of 4.93, while the Thai, Mandarin Chinese, and English-pre-trained models obtain MOS scores of 3.65, 3.55, and 3.44, respectively. These results highlight the importance of linguistic proximity in cross-lingual multi-speaker TTS, particularly tonal and prosodic similarity between source and target languages. Overall, the study confirms that transfer learning is an effective approach for low-resource Thai TTS and that tonal source languages provide more beneficial knowledge transfer than non-tonal, accent-based languages.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
H. Zen, A. Senior and M. Schuster, “Statistical parametric speech synthesis using deep neural networks,” 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, pp. 7962-7966, 2013.
Y. Wang et al., “Tacotron: Towards end-to-end speech synthesis,” arXiv preprint arXiv:1703.10135. 2017.
J. Shen et al., “Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions,” 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, pp. 4779-4783, 2018.
M. Lee, J. Lee and J. -H. Chang, “NonAutoregressive Fully Parallel Deep Convolutional Neural Speech Synthesis,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 1150-1159, 2022.
Y. Ren et al., “Fastspeech: Fast, robust and controllable text to speech,” in Proceedings of the 33rd International Conference on Neural Information Processing Systems, no. 285, pp. 31713180, 2019.
Y. Ren et al., “Fastspeech 2: Fast and high-quality end-to-end text to speech,” arXiv preprint arXiv:2006.04558, 2020.
M. Chen et al., “Multispeech: Multi-speaker text to speech with transformer,” arXiv preprint arXiv:2006.04664. 2020.
T. Li, X. Wang, Q. Xie, Z. Wang and L. Xie, “Cross-Speaker Emotion Disentangling and Transfer for End-to-End Speech Synthesis,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 1448-1460, 2022.
M. Adibian and H. Zeinali, “End-to-End MultiSpeaker FastSpeech2 With Hierarchical Decoder,” in IEEE Access, vol. 13, pp. 127805127814, 2025.
E. Casanova et al., “Yourtts: Towards zeroshot multi-speaker tts and zero-shot voice conversion for everyone,” in Proceedings of the 39th International Conference on Machine Learning (PMLR), vol. 162, pp. 2709-2720, 2022.
K. Azizah and W. Jatmiko, “Transfer Learning, Style Control, and Speaker Reconstruction Loss for Zero-Shot Multilingual Multi-Speaker 365 Text-to-Speech on Low-Resource Languages,” in IEEE Access, vol. 10, pp. 5895-5911, 2022.
M. A. Hedderich, L. Lange, H. Adel, J. Str¨otgen and D. Klakow, “A survey on recent approaches for natural language processing in low-resource scenarios,” in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2545-2568, 2021.
A. R. Gladston and K. V. Pradeep, “Exploring Solutions for Text-to-Speech Synthesis of LowResource Languages,” 2023 4th International Conference on Signal Processing and Communication (ICSPC), Coimbatore, India, pp. 168-172, 2023.
K. Azizah, M. Adriani and W. Jatmiko, “Hierarchical Transfer Learning for Multilingual, MultiSpeaker, and Style Transfer DNN-Based TTS on Low-Resource Languages,” in IEEE Access, vol. 8, pp. 179798-179812, 2020.
A. Debnath, S. S. Patil, G. Nadiger and R. A. Ganesan, “Low-Resource End-to-end Sanskrit TTS using Tacotron2, WaveGlow and Transfer Learning,” 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, pp. 1-5, 2020.
S. Chomphan and T Kobayashi, “Implementation and evaluation of an HMM-based Thai speech synthesis system,” Interspeech 2007, Antwerp, Belgium, pp. 2849-2852, 2007.
T. Daengsi and P. Pornpongtechavanich, “Quality of Experience: Comparison of Synthesized Speech Naturalness Between Apple’s Siri and Google Translate Referring to Thai Language,” 2021 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, pp. 1-4, 2021.
P. Janyoi and A. Thangthai, “Investigation of an Input Sequence on Thai Neural Sequence-toSequence Speech Synthesis,” 2021 24th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), Singapore, Singapore, pp. 218-223, 2021.
A. Suwanbandit et al., “Thai-Dialect: Low Resource Thai Dialectal Speech to Text Corpora,” 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Taipei, Taiwan, pp. 1-8, 2023.
S. Arik et al., “Deep voice 2: Multispeaker neural text-to-speech,” arXiv preprint arXiv:1705.08947. 2017.
W. Ping et al., “Deep voice 3: Scaling text-to-speech with convolutional sequence learning,” arXiv preprint arXiv:1710.07654. 2017.
Y. Jia et al., “Transfer learning from speaker verification to multispeaker text-to-speech synthesis,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, pp. 4485-4495, 2018.
O. Nazir, A. Malik, S. Singh and A.-S. K. Pathan, “Multi speaker text-to-speech synthesis using generalized end-to-end loss function,” Multimedia Tools and Applications, vol. 83, pp. 64205-64222, 2024.
Y. Wang et al., “Style tokens: Unsupervised style modeling, control and transfer in end-toend speech synthesis,” in Proceedings of the 35th International Conference on Machine Learning (PMLR), Stockholm, Sweden, 2018.
L. Loots and T. Niesler, “Automatic conversion between pronunciations of different english accents,” Speech Communication, vol. 53, no. 1, pp. 75–84, 2011.
R. Liu, B. Sisman, G. Gao and H. Li, “Controllable accented text-to-speech synthesis,” arXiv preprint arXiv:2209.10804. 2022.
X. Zhou, M. Zhang, Y. Zhou, Z. Wu and H. Li, “Accented Text-to-Speech Synthesis With Limited Data,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 1699-1711, 2024.
Z. Cai, Y. Yang and M. Li, “Cross-lingual multispeaker speech synthesis with limited bilingual training data,” Computer Speech & Language, vol. 77, p. 101427, 2023.
A. La´ncucki, “Fastpitch: Parallel Text-toSpeech with Pitch Prediction,” ICASSP 2021 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, pp. 6588-6592, 2021.
J. Kong, J. Kim and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and highfidelity speech synthesis,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, no. 1428, pp. 1702217033, 2020.
C. Wutiwiwatchai, S. Saychum and A. Rugchatjaroen, “An intensive design of a Thai speech synthesis corpus,” International Symposium on Natural Language Processing (SNLP 2007), 2007.
J. Li, “Call to Arms,” LibriVox, 2012. [Online]. Available: https://librivox.org/ call-to-arms-by-xun-lu/.
K. Ito and L. Johnson, “The LJ Speech Dataset,” 2017. [Online]. Available:https:// keithito.com/LJ-Speech-Dataset/.
