
VhAR-Net: A Cross-Modal Representation Learning Framework for Text-Based Vehicle Retrieval
Article Sidebar
Main Article Content
Abstract
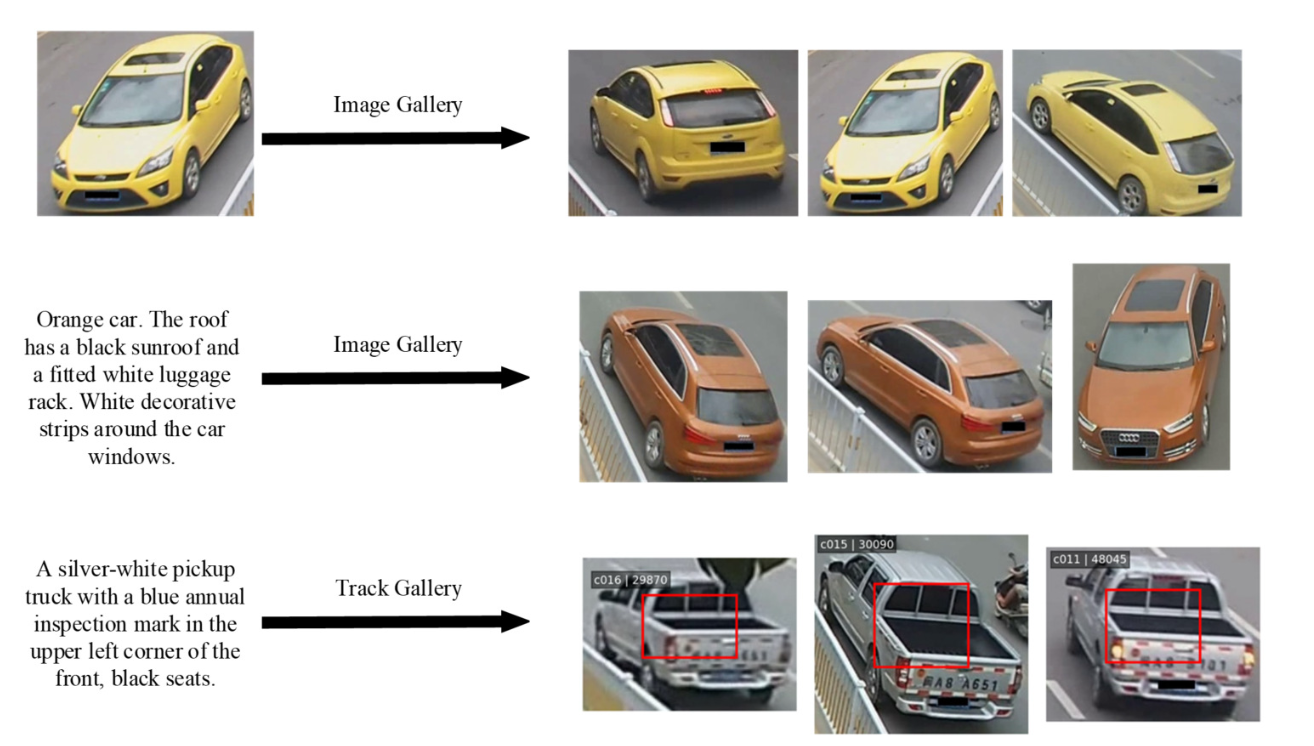
With the advancement of intelligent transportation systems and large-scale urban video surveillance technologies, vehicle image retrieval based on textual descriptions has become increasingly important. Although MCANet exhibits effectiveness in multi-scale feature alignment, significant limitations persist in accurate fine-grained semantic matching. To address this, we present VhAR-Neta modular cross-modal retrieval architecture that enables independent design and flexible combination of feature interaction mechanisms, enhancement strategies, and supervisory signals. This framework employs ResNet-50 as the visual representation extractor and BERT as the textual semantic encoder, and innovatively introduces a cross-modal attention unit that establishes explicit associations between image representations and linguistic descriptions. Concurrently, the system establishes small-object aware auxiliary supervision through binary classification tasks targeting discriminative fine-grained vocabulary, thereby directing the network toward distinctive microscopic semantic units. Empirical evaluations on the public benchmark dataset T2I-VeRi indicate that the optimal configuration achieves 75% Top-1 retrieval accuracy, with Top-10 recall covering 85% of relevant samples. After introducing the feature enhancement module and small-object supervision mechanism, the cumulative matching rate for Top-5 and Top-10 both reached 85%, demonstrating improved retrieval robustness.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
A. Amiri, A. Kaya and A. S. Keceli, “A comprehensive survey on deep-learning-based vehicle re-identification: Models, data sets and challenges,” arXiv preprint arXiv:2401.10643, 2024.
W. Zhan, S. Huang, Q. Fan, Y. Jin and M. L. Mingxing, “A multi-scale network with multiview correlation for vehicle re-identification,” Multimedia Systems, vol. 31, no. 3, pp. 1-16, 2025.
F. Zheng and J. Qu, “TIDCB: Text image dangerous-scene convolutional baseline,” ECTI Transactions on Computer and Information Technology (ECTI-CIT), vol. 18, no. 3, pp. 280294, 2024.
S. Saravi and E. A. Edirisinghe, “Vehicle Make and Model Recognition in CCTV footage,” 2013 18th International Conference on Digital Signal Processing (DSP), Fira, Greece, pp. 1-6, 2013.
M. Nieto, L. Unzueta, A. Cort´es, J. Barandiaran and O. Otaegui, “Real-time 3D Modeling of Vehicles in Low-cost Monocamera Systems,” in Proc. Visapp 2011 6th Int. Conf. Computer Vision Theory and Applications, Vilamoura, pp. 459-464, 2011.
K. Ramnath, S. N. Sinha, R. Szeliski and E. Hsiao, “Car make and model recognition using 3D curve alignment,” IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, pp. 285-292, 2014.
X. Liu, W. Liu, H. Ma and H. Fu, “Largescale vehicle re-identification in urban surveillance videos,” 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, pp. 1-6, 2016.
X. Liu, W. Liu, T. Mei and H. Ma, “PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance,” in IEEE Transactions on Multimedia, vol. 20, no. 3, pp. 645-658, March 2018.
H. Liu, Y. Tian, Y. Wang, L. Pang and T. Huang, “Deep Relative Distance Learning: Tell the Difference between Similar Vehicles,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 2167-2175, 2016.
A. Krizhevsky, I. Sutskever and G. Hinton, “Imagenet classification with deep convolutional neural networks,” in Proc. NIPS, Lake Tahoe: Curran Associates Inc, pp. 84-90, 2012.
C. Szegedy et al., “Going deeper with convolutions,” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, pp. 1-9, 2015.
X. Wei, “Vehicle video retrieval based on angle discrimination,” M.S. thesis, Central South University, Hunan, China, 2013.
A. Wei, “Vehicle retrieval method based on invehicle decorative features,” M.S. thesis, Southeast University, Jiangsu, China, 2016.
Y. Zhou and L. Shao, “Vehicle Re-Identification by Adversarial Bi-Directional LSTM Network,” 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, pp. 653-662, 2018.
D. Zapletal and A. Herout, “Vehicle Re287 identification for Automatic Video Traffic Surveillance,” 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, pp. 15681574, 2016.
J. Sochor, J. Spaˇnhel and A. Herout, “BoxCars: Improving Fine-Grained Recognition of Vehicles Using 3-D Bounding Boxes in Traffic Surveillance,” in IEEE Transactions on Intelligent Transportation Systems, vol. 20, no. 1, pp. 97-108, Jan. 2019.
J. Sochor, A. Herout and J. Havel, “BoxCars: 3D Boxes as CNN Input for Improved Fine-Grained Vehicle Recognition,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 30063015, 2016.
E. Yu et al., “Deep Discrete Cross-Modal Hashing with Multiple Supervision,” Neurocomputing, vol. 486, pp. 215-224, 2022.
Y. Zhu and X. Li, “Iterative Uni-modal and Cross-modal Clustered Contrastive Learning for Image-text Retrieval,” 2023 International Conference on Pattern Recognition, Machine Vision and Intelligent Algorithms (PRMVIA), Beihai, China, pp. 15-23, 2023.
M. Yuan, H. Zhang, D. Liu, L. Wang and L. Liu, “Semantic-embedding Guided Graph Network for Cross-modal Retrieval,” Journal of Visual Communication and Image Representation, vol. 93, p. 103807, 2023.
P. Zhang et al., “VinVL: Revisiting Visual Representations in Vision-Language Models,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, pp. 5575-5584, 2021.
Z. Liu, F. Chen, J. Xu, W. Pei and G. Lu, “Image-Text Retrieval With Cross-Modal Semantic Importance Consistency,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 5, pp. 2465-2476, May 2023.
P. Park, S. Jang, Y. Cho and Y. Kim, “SAM: Cross-modal semantic alignments module for image-text retrieval,” Multimedia Tools and Applications, vol. 83, pp. 12363-12377, 2023.
W. Chen, “Res-ViT: A vehicle re-identification method based on residual attention and Vision Transformer,” SPIE Proc., vol. 52, pp. 214-226, 2025.
Z. Wang and X. Zhang, “Vehicle ReIdentification Method Based on Efficient Self-Attention CNN-Transformer and MultiTask Learning Optimization,” Sensors, vol. 31, pp. 2223-2236, 2025.
L. Ding et al., “Text-to-Image Vehicle ReIdentification: Multi-Scale Multi-View CrossModal Alignment Network and a Unified Benchmark,” in IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 7, pp. 76737686, July 2024.
Q. Wang and D. Zhang, “Vehicle reidentification based on dimensional decoupling and non-local relationship network,” PLOS ONE, vol. 19, pp. 675-689, 2024.
X. Liu and W. Chen, “Vehicle re-identification with multiple discriminative features,” Scientific Reports, vol. 13, pp. 1223-1235, 2024.
A. Guo, “Research on CLIP2TV-VIR Algorithm for Vehicle Video Retrieval,” M.S. thesis, Shenyang University, 2024.
X. Luo, “Research on Vehicle Re-Identification Methods Based on Video Images,” M.S. thesis, Chang’an University, 2024.
Y. Han, “Research and System Implementation of Vehicle Retrieval Algorithms for Surveillance Video,” M.S. thesis, Beijing University of Posts and Telecommunications, 2023.
X. Luo, “Research and Application of Vehicle Re-Identification Methods Based on Video Images,” M.S. thesis, Chang’an University, 2024.
M. Cui, “Research on Efficient Retrieval Methods for Large-scale Complex Vehicle Images,” M.S. thesis, Guilin University of Electronic Technology, 2022.
K. Q. Weinberger and L. K. Saul, “Distance metric learning for large margin nearest neighbor classification,” Journal of Machine Learning Research, vol. 10, pp. 207–244, Feb. 2009.
O. Rippel, M. Paluri, P. Dollar and L. Bourdev, “Metric learning with adaptive density discrimination,” ICLR, pp. 1–15, 2016.
A. Hermans, L. Beyer and B. Leibe, “In defense of the triplet loss for person re-identification,” arXiv preprint arXiv:1703.07737, 2017.
A. van den Oord, Y. Li and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
Y. Xie and J. Qu, “A Study on Bilingual Deep Learning PIS Neural Network Model Based on Graph-Text Modal Fusion,” ECTI-CIT Transactions, vol. 19, no. 1, pp. 13–23, Jan. 2025.
