
LLM-Driven Annotation: A Scalable Framework for Automated Multi-Label Coffee Flavor Classification
Article Sidebar
Main Article Content
Abstract
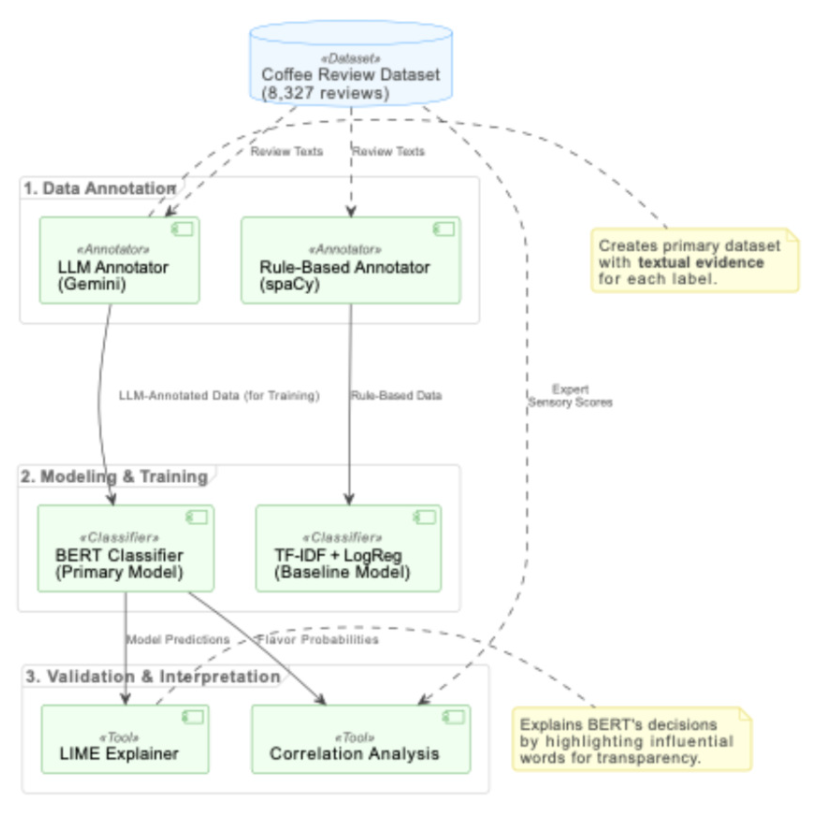
The subjective and unstructured nature of coffee tasting notes creates a significant data annotation bottleneck, limiting the application of computational methods in sensory science. This study introduces a novel end-to-end framework for automating multi-label coffee flavor classification, integrating LLM-driven annotation with transformer-based classification and local interpretability analysis. Google's Gemini-1.5-Flash was employed to perform evidence-based annotation on 8,327 expert evaluations authored by certified Q Graders, generating a high-quality training dataset across 17 flavor categories. Critically, the Q Grader provenance of the source texts enables a reverse-mapping validation framework: statistically significant and directionally coherent correlations between LLM-derived labels and expert quantitative scores (Floral r = 0.32, Roasted r = −0.25, all p <0.001) provide implicit ground truth without requiring separate annotation effort. Reliability analysis revealed substantial consistency for concrete physical descriptors (mean κ = 0.68) but notably lower agreement for abstract sensory concepts such as Mouthfeel (κ = 0.10), identifying two distinct reliability regimes that define the framework's operational boundaries. A ne-tuned BERT model trained on these annotations outperformed a TF- IDF baseline, achieving a Micro F1-score of 0.9164 versus 0.8763 and a Hamming Loss of 0.0640 versus 0.0969. To address severe class imbalance (up to 125×), Focal Loss (γ = 2.0) combined with per-class threshold optimization successfully recovered detection of rare defect categories, improving Macro-F1 from 0.656 to 0.719. Local interpretability analysis via LIME further confirmed that model predictions align with domain-expert sensory reasoning. These results demonstrate that an LLM-driven annotation pipeline offers a scalable, transparent, and effective solution to the data bottleneck in sensory science, establishing a robust methodological foundation for interpretable classification across other sensory-driven domains.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
T. R. Lingle, The Coffee Cupper’s Handbook: Systematic Guide to the Sensory Evaluation of Coffee’s Flavor, ser. Handbook Series. Specialty Coffee Association of America, 2011.
H. Stone, R. N. Bleibaum and H. A. Thomas, Sensory Evaluation Practices. Academic Press, 2020.
M. M. C. Mahmud, R. A. Shellie and R. Keast, “Unravelling the relationship between aroma compounds and consumer acceptance: Coffee as an example,” Comprehensive Reviews in Food Science and Food Safety, vol. 19, no. 5, pp. 23802420, 2020.
D. R. Seninde and E. Chambers IV, “Coffee Flavor: A Review,” Beverages, vol. 6, no. 3, p. 44, 2020.
A. Alamsyah, S. Widiyanesti, P. Wulansari, E. Nurhazizah, A. S. Dewi, D. Rahadian, D. P. Ramadhani, M. N. Hakim and P. Tyasamesi, “Blockchain traceability model in the coffee industry,” Journal of Open Innovation: Technology, Market, and Complexity, vol. 9, no. 1, p. 100008, 2023.
E. A. Fernandes, G. A. Sarries, Y. T. Mazola, R. C. Lima, G. N. Furlan and M. A. Bacchi, “Machine learning to support geographical origin traceability of Coffea Arabica,” Advances in Artificial Intelligence and Machine Learning, vol. 2, no. 1, pp. 273-287, 2022.
Specialty Coffee Association, “Specialty Coffee Association Flavor Wheel,” 2015. [Online]. Available: https://sca.coffee/research/ flavor-wheel
NotBadCoffee, “World Coffee Guide: Flavor Wheel,” 2024. [Online]. Available: https://notbadcoffee.com/flavor-wheel-en/. [Accessed: Jun. 17, 2024].
World Coffee Research, “World Coffee Research Sensory Lexicon,” 2016. [Online]. Available: https://worldcoffeeresearch.org/work/ sensory-lexicon/
S. Suwonsichon, “The Importance of Sensory Lexicons for Research and Development of Food Products,” Foods, vol. 8, no. 1, p. 27, 2019.
M. Spencer, E. Sage, M. Velez and J.-X. Guinard, “Using Single Free Sorting and Multivariate Exploratory Methods to Design a New Coffee Taster’s Flavor Wheel,” Journal of Food Science, vol. 81, no. 12, pp. S2997-S3005, Nov. 2016.
Z. Li, Q. Su, S. Si and J. Yu, “Leveraging BERT and TFIDF Features for Short Text Clustering via Alignment-Promoting Co-Training,” in Proc. 2024 Conf. Empirical Methods in Natural Language Processing, pp. 14897-14913, Nov. 2024.
L. Cai, Y. Song, T. Liu and K. Zhang, “A Hybrid BERT Model That Incorporates Label Semantics via Adjustive Attention for Multi-Label Text Classification,” in IEEE Access, vol. 8, pp. 152183-152192, 2020.
J. Devlin, M.-W. Chang, K. Lee and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of NAACL-HLT 2019, pp. 4171-4186, 2019.
F. Hayakawa, Y. Kazami, H. Wakayama, R. Oboshi, H. Tanaka, G. Maeda, C. Hoshino, H. Iwawaki and T. Miyabayashi, “Sensory lexicon of brewed coffee for Japanese consumers, untrained coffee professionals and trained coffee tasters,” Journal of Sensory Studies, vol. 25, no. 6, pp. 917-939, 2010.
I. Chalkidis, M. Fergadiotis, S. Kotitsas, P. Malakasiotis, N. Aletras and I. Androutsopoulos, “An Empirical Study on Large-Scale MultiLabel Text Classification Including Few and Zero-Shot Labels,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 7503-7515, Nov. 2020.
G. Garrido-Ba˜nuelos, M. Mafata and A. Buica, “Using Latent Semantic Analysis to investigate Wine Sensory Profiles—Application in Swedish Solaris Wines,” Beverages, vol. 10, no. 4, p. 120, 2024.
E. Lekhtman, Y. Ziser and R. Reichart, “‘DILBERT’: Customized Pre-Training for Domain Adaptation with Category Shift, with an Application to Aspect Extraction,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 219-230, Nov. 2021.
S. Rezayi, Z. Liu, Z. Wu, C. Dhakal, B. 381 Ge, C. Zhen, T. Liu and S. Li, “AgriBERT: Knowledge-Infused Agricultural Language Models for Matching Food and Nutrition,” in Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence AI for Good, pp. 5150-5156, Jul. 2022.
I. Malkiel, O. Barkan, A. Caciularu, N. Razin, O. Katz and N. Koenigstein, “Optimizing BERT for Unlabeled Text-Based Items Similarity,” in Findings Assoc. Comput. Linguistics: EMNLP 2020, pp. 1704-1714, 2020.
R. Smith, J. A. Fries, B. Hancock and S. H. Bach, “Language Models in the Loop: Incorporating Prompting into Weak Supervision,” ACM/IMS Journal of Data Science, vol. 1, no. 2, p. 7, Apr. 2024.
M. T. Ribeiro, S. Singh, and C. Guestrin, “‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier,” in Proc. 22nd ACM SIGKDD Int. Conf. Knowledge Discovery and Data Mining, pp. 1135-1144, 2016.
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” in Advances in Neural Information Processing Systems 30 (NIPS 2017), pp. 4768-4777, 2017.
A. Cartolano, A. Cuzzocrea and G. Pilato, “Analyzing and assessing explainable AI models for smart agriculture environments,” Multimedia Tools and Applications, vol. 83, no. 12, pp. 37225-37246, Jan. 2024.
K. Sermmany, P. Wanjantuk and W. Leelapatra, “Utilizing Explainable Artificial Intelligence (XAI) to Identify Determinants of Coffee Quality,” in Proc. 2024 21st Int. Joint Conf. Computer Science and Software Engineering (JCSSE), pp. 696-703, Jun. 2024.
CoffeeReview, “The Coffee Review Database,” 2024. [Online]. Available: https://www.coffeereview.com. [Accessed: Jun. 17, 2024].
M. Honnibal, I. Montani, S. Van Landeghem and A. Boyd, “spaCy: Industrial-strength Natural Language Processing in Python,” 2020.
S. Bird, E. Klein and E. Loper, Natural Language Processing with Python. O’Reilly Media, Inc., 2009. [Online]. Available: https://www. nltk.org/book/
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. K¨opf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai and S. Chintala, “PyTorch: An imperative style, high-performance deep learning library,” 2019. [Online]. Available: https://arxiv.org/abs/ 1912.01703
T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y. Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest and A. M. Rush, “Huggingface’s transformers: State-of-the-art natural language processing,” 2020.
[Online]. Available: https://arxiv.org/abs/ 1910.03771
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825-2830, Nov. 2011.
G. Tsoumakas, I. Katakis, and I. Vlahavas, “Mining Multi-label Data,” Boston, MA, USA: Springer US, 2010, pp. 667-685.
[Online]. Available: https://doi.org/10.1007/ 978-0-387-09823-4_34
B. Efron and R. J. Tibshirani, An Introduction to the Bootstrap, 1st ed. Chapman and Hall/CRC, 1994.
T. -Y. Lin, P. Goyal, R. Girshick, K. He and P. Doll´ar, “Focal Loss for Dense Object Detection,” 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, pp. 29993007, 2017.
N. Pangakis and S. Wolken, “Knowledge distillation in automated annotation: Supervised text classification with LLM-generated training labels,” in Proceedings of the Sixth Workshop on Natural Language Processing and Computational Social Science (NLP+CSS 2024), Mexico City, Mexico, pp. 113-131, Jun. 2024.
M. Alizadeh, M. Kubli, Z. Samei, S. Dehghani, M. Zahedivafa, J. D. Bermeo, M. Korobeynikova and F. Gilardi, “Open-source LLMs for text annotation: a practical guide for model setting and fine-tuning,” Journal of Computational Social Science, vol. 8, no. 1, p. 17, 2025.
