
Performance Evaluation of Imputation Techniques for Telecommunications Customer Clustering
Article Sidebar
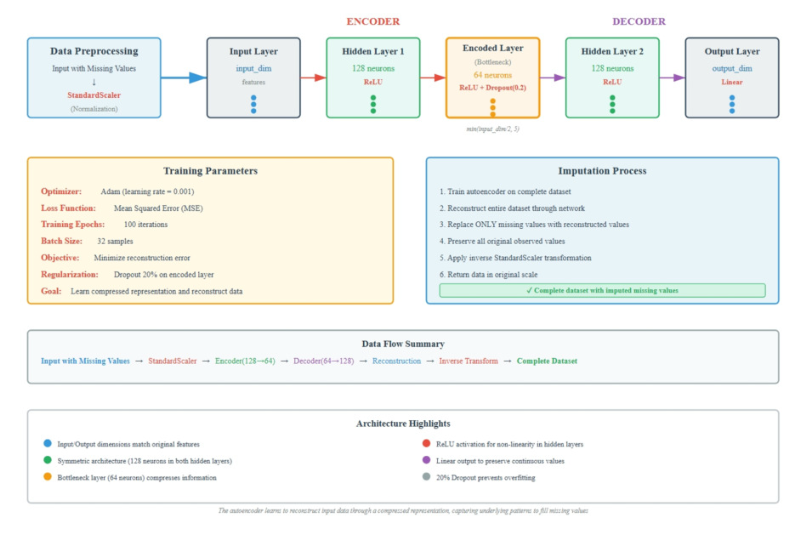
Main Article Content
Abstract
Missing data significantly degrades machine learning model performance in telecommunications customer analytics, leading to unreliable customer segmentation and suboptimal business decision-making. This research systematically compares seven imputation techniques across three missing mechanisms (MCAR, MAR, MNAR) and four missing rates (5%, 10%, 20%, 30%) using the Telco Customer Churn Dataset (7,043 records). Methods evaluated include traditional approaches (mean/mode, forward ll, regression), machine learning techniques (KNN, Random Forest, MICE), and deep learning (Autoencoder). We assessed model performance using normalized MAE and RMSE, and evaluated downstream effects through clustering algorithms. Results demonstrate Random Forest imputation's superior performance with MAE of 0.1568 and RMSE of 0.2123, achieving 53.7% lower error rates compared to mean/mode imputation. Statistical analysis confirmed significant performance differences (Friedman test: χ2 = 55.85, p <0.001). Interestingly, clustering performance did not directly correlate with imputation accuracy; the Autoencoder achieved the highest silhouette score (0.1510) despite moderate reconstruction accuracy. Machine learning approaches maintained robust performance across all missing data mechanisms, whereas traditional methods degraded under MNAR conditions. These findings provide evidence-based guidelines for selecting appropriate imputation techniques in telecommunications analytics, enabling improved customer segmentation and business outcomes.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
Y. Chen, Y. Lv and F. -Y. Wang, “Traffic Flow Imputation Using Parallel Data and Generative Adversarial Networks,” in IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 4, pp. 1624-1630, April 2020.
X. Miao, Y. Wu, L. Chen, Y. Gao and J. Yin, “An Experimental Survey of Missing Data Imputation Algorithms,” in IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 7, pp. 6630-6650, 1 July 2023.
X. Xu, W. Chong, S. Li, A. Arabo and J. Xiao, “MIAEC: Missing Data Imputation Based on the Evidence Chain,” in IEEE Access, vol. 6, pp. 12983-12992, 2018.
R. Wu, S. D. Hamshaw, L. Yang, D. W. Kincaid, R. Etheridge and A. Ghasemkhani, “Data Imputation for Multivariate Time Series Sensor Data With Large Gaps of Missing Data,” in IEEE Sensors Journal, vol. 22, no. 11, pp. 10671-10683, 1 June1, 2022.
Y. Liu, T. Dillon, W. Yu, W. Rahayu and F. Mostafa, “Missing Value Imputation for Industrial IoT Sensor Data With Large Gaps,” in IEEE Internet of Things Journal, vol. 7, no. 8, pp. 6855-6867, Aug. 2020.
R. J. A. Little and D. B. Rubin, Statistical Analysis with Missing Data, 3rd ed. Hoboken, NJ, USA: Wiley, 2019.
L. Breiman, “Random forests,” Machine Learning, vol. 45, no. 1, pp. 5–32, 2001.
R. Polikar, “Ensemble based systems in decision making,” in IEEE Circuits and Systems Magazine, vol. 6, no. 3, pp. 21-45, Third Quarter 2006.
Y. Wu, J. Wang, X. Miao, W. Wang and J. Yin, “Differentiable and Scalable Generative Adversarial Models for Data Imputation,” in IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 2, pp. 490-503, Feb. 2024.
J. Venugopalan, N. Chanani, K. Maher and M. D. Wang, “Novel Data Imputation for Multiple Types of Missing Data in Intensive Care Units,” in IEEE Journal of Biomedical and Health Informatics, vol. 23, no. 3, pp. 1243-1250, May 2019.
W. Khan et al., “Mixed Data Imputation Using Generative Adversarial Networks,” in IEEE Access, vol. 10, pp. 124475-124490, 2022.
S. E. Awan et al., “Imputation of missing data with class imbalance using conditional generative adversarial networks,” Neurocomputing, vol. 453, pp. 164–171, 2021.
D. B. Rubin, “Inference and missing data,” Biometrika, vol. 63, no. 3, pp. 581–592, 1976.
S. Van Buuren, Flexible Imputation of Missing Data, 2nd ed. Boca Raton, FL, USA: CRC Press, 2018.
J. L. Schafer, Analysis of Incomplete Multivariate Data. London, U.K.: Chapman & Hall/CRC, 1997.
V. Kumar and W. Reinartz, “Creating enduring customer value,” Journal of Marketing, vol. 80, no. 6, pp. 36–68, 2016.
S. A. Neslin et al., “Defection detection: Measuring and understanding the predictive accuracy of customer churn models,” Journal of Marketing Research, vol. 43, no. 2, pp. 204–211, 2006.
M. Wedel and W. A. Kamakura, Market Segmentation: Conceptual and Methodological Foundations, 2nd ed. Boston, MA, USA: Kluwer, 2000.
Y. Bengio, A. Courville and P. Vincent, “Representation Learning: A Review and New Perspectives,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798-1828, Aug. 2013.
T. G. Dietterich, “Ensemble methods in machine learning,” in Lecture Notes in Computer Science, vol. 1857, pp. 1–15, 2000.
Y. Gong, Z. Li, J. Zhang, W. Liu, Y. Yin and Y. Zheng, “Missing Value Imputation for MultiView Urban Statistical Data via Spatial Correlation Learning,” in IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 1, pp. 686-698, 1 Jan. 2023.
P. Wang, T. Hu, F. Gao, R. Wu, W. Guo and X. Zhu, “A Hybrid Data-Driven Framework for Spatiotemporal Traffic Flow Data Imputation,” in IEEE Internet of Things Journal, vol. 9, no. 17, pp. 16343-16352, 1 Sept.1, 2022.
Y. Zelenkov and A. Suchkova, “Predicting customer churn based on changes in their behavior patterns,” Business Informatics, vol. 17, pp. 7–17, 2023.
A. Chadaga, M. Legg and C. H. B. Liu, “Enhancing customer lifetime value using data science and predictive modeling,” Technium Business and Management, vol. 12, pp. 112-125, 2025.
H. Li, Y. Liao, Z. Tian, Z. Liu, J. Liu and X. Liu, “Bidirectional Stackable Recurrent Generative Adversarial Imputation Network for Specific Emitter Missing Data Imputation,” in IEEE Transactions on Information Forensics and Security, vol. 19, pp. 2967-2980, 2024.
X. Chen, M. Lei, N. Saunier and L. Sun, “LowRank Autoregressive Tensor Completion for Spatiotemporal Traffic Data Imputation,” in IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 8, pp. 12301-12310, Aug. 2022.
M. S. Osman, A. M. Abu-Mahfouz and P. R. Page, “A Survey on Data Imputation Techniques: Water Distribution System as a Use Case,” in IEEE Access, vol. 6, pp. 63279-63291, 2018.
R. C. Pereira, P. H. Abreu and P. P. Rodrigues, “Partial Multiple Imputation With Variational Autoencoders: Tackling Not at Randomness in Healthcare Data,” in IEEE Journal of Biomedical and Health Informatics, vol. 26, no. 8, pp. 4218-4227, Aug. 2022.
X. Zhu, J. Yang, C. Zhang and S. Zhang, “Efficient Utilization of Missing Data in CostSensitive Learning,” in IEEE Transactions on Knowledge and Data Engineering, vol. 33, no. 6, pp. 2425-2436, 1 June 2021.
M. J. Kim and Y. Cho, “Imputation of missing values in well log data using k-nearest neighbor collaborative filtering,” Computers & Geosciences, vol. 193, p. 105712, 2024.
X. Wei, Y. Zhang, S. Wang, X. Zhao, Y. Hu and B. Yin, “Self-Attention Graph Convolution Imputation Network for Spatio-Temporal Traffic Data,” in IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 12, pp. 19549-19562, Dec. 2024.
N. Abiri, B. Linse, P. Ed´en and M. B.O. Ohlsson, “Establishing strong imputation performance of a denoising autoencoder,” Neurocomputing, vol. 365, pp. 137–146, 2019.
R. C. Pereira, P. H. Abreu and P. P. Rodrigues, “Siamese autoencoder architecture for the imputation of data missing not at random,” Journal of Computational Science, vol. 78, p. 102269, 2024.
X. Lai, X. Wu, and L. Zhang, “Autoencoderbased multi-task learning for imputation and classification,” Applied Soft Computing, vol. 98, p. 106838, 2021.
R. Shahbazian and S. Greco, “Generative Adversarial Networks Assist Missing Data Imputation: A Comprehensive Survey and Evaluation,” in IEEE Access, vol. 11, pp. 88908-88928, 2023.
S. E. Awan et al., “Imputation of missing data with class imbalance using conditional generative adversarial networks,” Neurocomputing, vol. 453, pp. 164–171, 2021.
Z. Guo, Y. Wan and H. Ye, “A data imputation method for multivariate time series based on GAN,” Neurocomputing, vol. 360, pp. 185–197, 2019.
J. Zhao, C. Rong, C. Lin and X. Dang, “Multivariate time series data imputation using attention-based mechanism,” Neurocomputing, vol. 542, p. 126238, 2023.
D. Liu, Y. Wang, C. Liu, K. Wang, X. Yuan and C. Yang, “Blackout Missing Data Recovery in Industrial Time Series Based on Masked-Former Hierarchical Imputation Framework,” in IEEE Transactions on Automation Science and Engineering, vol. 21, no. 2, pp. 1138-1150, April 2024.
N. Karmitsa, S. Taheri, A. Bagirov and P. M¨akinen, “Missing Value Imputation via Clusterwise Linear Regression,” in IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 4, pp. 1889-1901, 1 April 2022.
A. A. Harder, G. R. Olbricht, G. Ekuma, D. B. Hier and T. Obafemi-Ajayi, “Multiple Imputation for Robust Cluster Analysis to Address Missingness in Medical Data,” in IEEE Access, vol. 12, pp. 42974-42991, 2024.
L. Zhao, Z. Chen, Z. Yang, Y. Hu and M. S. Obaidat, “Local Similarity Imputation Based on Fast Clustering for Incomplete Data in CyberPhysical Systems,” in IEEE Systems Journal, vol. 12, no. 2, pp. 1610-1620, June 2018.
A. Tharwat and W. Schenck, “Active Learning for Handling Missing Data,” in IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 2, pp. 3273-3287, Feb. 2025.
“Telco Customer Churn Dataset,” Kaggle, 2023. [Online]. Available: https: //www.kaggle.com/datasets/jethwaaatmik/ telco-customer-churn-dataset
J. Yoon, J. Jordon, and M. van der Schaar, “GAIN: Missing data imputation using generative adversarial nets,” in Proceedings of the 35th International Conference on Machine Learning, vol. 80, pp. 5689–5698, 2018.
A. Naz´abal, P. M. Olmos, Z. Ghahramani and I. Valera, “Handling incomplete heterogeneous data using VAEs,” Pattern Recognition, vol. 107, p. 107501, 2020.
D. F. Heitjan and S. Basu, “Distinguishing “missing at random” and “missing completely at random”,” The American Statistician, vol. 50, no. 3, pp. 207–213, 1996.
Y. He , A. M. Zaslavsky, D. P. Harrington, P. Catalano and M. B. Landrum , “Multiple imputation in a large-scale complex survey,” Stat. Methods Med. Res., vol. 19, no. 6, pp. 653–670, 2010.
K. Potdar, T. S. Pardawala and C. D. Pai, “A comparative study of categorical variable encoding techniques,” International Journal of Computer Applications, vol. 175, no. 4, pp. 7–9, 2017.
J. T. Hancock and T. M. Khoshgoftaar, “CatBoost for big data,” Journal of Big Data, vol. 7, no. 1, pp. 1–45, 2020. 191
P. Cerda, G. Varoquaux and B. K´egl, “Similarity encoding for learning with dirty categorical variables,” Machine Learning, vol. 107, no. 8, pp. 1477–1494, 2018.
F. Pargent, F. Pfisterer, J. Thomas and B. Bischl , “Regularized target encoding outperforms traditional methods,” Computational Statistics, vol. 37, no. 5, pp. 2671–2692, 2022.
G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, 2006.
X. Glorot, A. Bordes, and Y. Bengio, “Deep sparse rectifier neural networks,” in Proceedings of the 14th International Conference on Arti cial Intelligence and Statistics (AISTATS), vol. 15, pp. 315–323, 2011.
N. Srivastava, G. Hintonm, A. Krizhevsky, I. Sutskever and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,” Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929–1958, 2014.
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
P. Vincent et al., “Stacked denoising autoencoders,” Journal of Machine Learning Research, vol. 11, pp. 3371–3408, 2010.
P. Baldi and K. Hornik, “Neural networks and principal component analysis,” Neural Networks, vol. 2, no. 1, pp. 53–58, 1989.
F. Tang and H. Ishwaran, “Random forest missing data algorithms,” Stat. Anal. Data Min., vol. 10, no. 6, pp. 363–377, 2017.
J. Josse and F. Husson, “missMDA: A package for handling missing values,” Journal of Statistical Software, vol. 70, no. 1, pp. 1–31, 2016.
T. Cali´nski and J. Harabasz, “A dendrite method for cluster analysis,” Communications in Statistics, vol. 3, no. 1, pp. 1–27, 1974.
L. van der Maaten and G. Hinton, “Visualizing data using t-SNE,” Journal of Machine Learning Research, vol. 9, pp. 2579–2605, 2008.
U. von Luxburg, “Clustering stability: An overview,” Foundations and Trends in Machine Learning, vol. 2, no. 3, pp. 235–274, 2010.
Y. Zhang, “Machine learning-based prediction of telecom customer churn,” Journal of Science and Technology, vol. 18, no. 2, pp. 116–123, 2025.
