
A Kernel-Aware Framework for Energy-Efficient FPGA Edge Detection Using XNOR-popcount and Selective Approximate Arithmetic
Article Sidebar
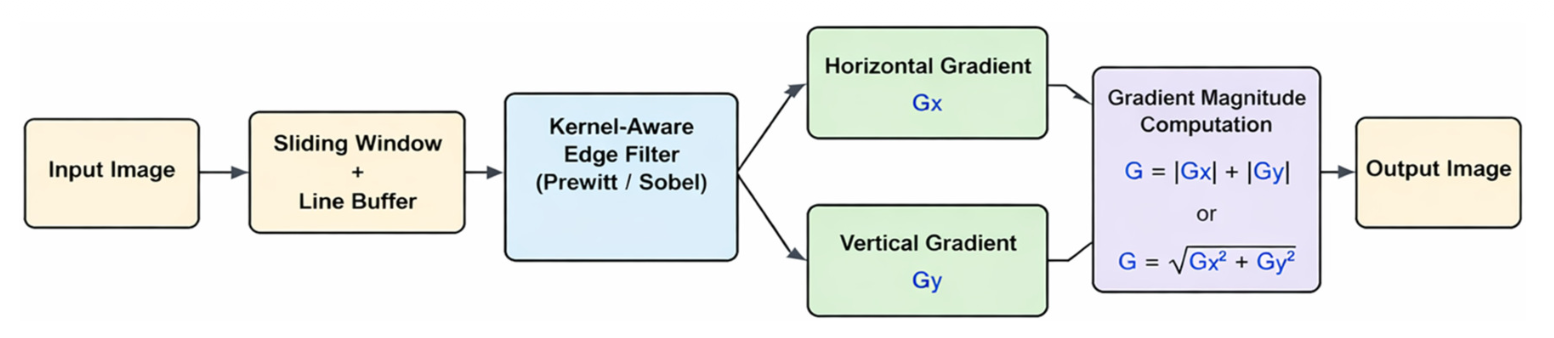
Main Article Content
Abstract
Edge-vision systems on resource-constrained platforms require low-latency and energy-efficient front-end processing. Conventional gradient-based edge operators continue to rely on multiply-accumulate (MAC) operations, which can increase logic utilization, switching activity, and power consumption in eld-programmable gate array (FPGA) implementations. This study introduces a kernel-aware arithmetic-selection framework, supported by synthesized evidence, for energy-efficient FPGA-based edge detection. The framework combines XNORpopcount-based arithmetic mapping with selective approximate computation. Its central design principle is to replace MAC operations with exclusive-NOR-population count (XNORpopcount) when the kernel structure is suitable for binary-friendly arithmetic, and to apply approximation only to the remaining adder-dominated stages when a complete XNOR-popcount mapping is not practical. Under this rule, Prewitt-like operators are mapped to an XNORpopcount datapath over their active nonzero taps. In contrast, Sobel-like operators are realized using a hybrid datapath that combines binary matching, shift-add processing, and approximate accumulation. The resulting framework shows that multiplier removal is the dominant source of hardware savings, while approximate arithmetic provides a controlled secondary optimization. Overall, the proposed approach establishes a structured design methodology for low-power FPGA edge-detection architectures on embedded platforms.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
M. Satyanarayanan, “The Emergence of Edge Computing,” Computer, vol. 50, no. 1, pp. 3039, 2017.
J. Chen and X. Ran, “Deep Learning With Edge Computing: A Review,” in Proceedings of the IEEE, vol. 107, no. 8, pp. 1655-1674, Aug. 2019.
V. Sze, Y. -H. Chen, T. -J. Yang and J. S. Emer, “Efficient Processing of Deep Neural Networks: A Tutorial and Survey,” in Proceedings of the IEEE, vol. 105, no. 12, pp. 2295-2329, Dec. 2017.
M. Horowitz, “1.1 Computing’s Energy Problem (and What We Can Do About It),” Proceedings of the IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), pp. 10-14, 2014.
N. P. Jouppi et al., “In-Datacenter Performance Analysis of a Tensor Processing Unit,” Proceedings of the 44th Annual International Symposium on Computer Architecture (ISCA), pp. 112, 2017.
Y.-H. Chen, T. Krishna, J. S. Emer and V. Sze, “Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks,” IEEE Journal of Solid-State Circuits, vol. 52, no. 1, pp. 127-138, 2017.
S. Han, H. Mao and W. J. Dally, “Deep Compression: Compressing Deep Neural Networks With Pruning, Trained Quantization and Huffman Coding,” Proceedings of the International Conference on Learning Representations (ICLR), 2016.
A. Gholami et al., “SqueezeNext: HardwareAware Neural Network Design,” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, pp. 1719-1728, 2018.
A. G. Howard et al., “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” arXiv Preprint arXiv:1704.04861, 2017.
V.-K. Pham, L. Le and T.-K. Tran Thi, “XNORPopcount, an Alternative Solution to the Accumulation Multiplication Method for Approximate Computations, to Improve Latency and Power Efficiency,” Journal of Technical Education Science, vol. 20, no. 1, pp. 12-20, 2025.
V.-K. Pham and L. Le, “An Energy-Efficient Hardware Module for Edge Detection Using XNOR-Popcount in Resource-Constrained Devices,” Indonesian Journal of Electrical Engineering and Computer Science, vol. 41, no. 1, pp. 73-82, 2026.
B.-L. Pham, V.-K. Pham, M.-P. Doan Thi and T.-T. Nguyen, “Real-Time, Energy-Efficient Sobel Edge Detection on FPGA Using Approximate Carry-Lookahead Adders,” Proceedings of the 28th International Conference on Mechatronics Technology (ICMT), pp. 357-362, 2025.
M. Rastegari, V. Ordonez, J. Redmon and A. Farhadi, “XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks,” Proceedings of the European Conference on Computer Vision (ECCV), Lecture Notes in Computer Science, vol. 9908, pp. 525-542, 2016.
M. Courbariaux, I. Hubara, D. Soudry, R. ElYaniv and Y. Bengio, “Binarized Neural Networks: Training Deep Neural Networks With Weights and Activations Constrained to +1 or -1,” arXiv Preprint arXiv:1602.02830, 2016.
S. Zhu, L. H. K. Duong and W. Liu, “XOR-Net: An Efficient Computation Pipeline for Binary Neural Network Inference on Edge Devices,” Proceedings of the International Conference on Parallel and Distributed Systems (ICPADS), pp. 124-131, 2020.
M. Rastegari, V. Ordonez, J. Redmon and A. Farhadi, “Enabling AI at the Edge With XNORNetworks,” Communications of the ACM, vol. 63, no. 12, pp. 83-90, 2020.
S. Rasoulinezhad, S. Fox, H. Zhou, L. Wang, D. Boland and P. H. W. Leong, “MajorityNets: BNNs Utilising Approximate Popcount for Improved Efficiency,” Proceedings of the International Conference on Field-Programmable Technology (ICFPT), pp. 339-342, 2019.
F. Conti, P. D. Schiavone and L. Benini, “XNOR Neural Engine: A Hardware Accelerator IP for 21.6-fJ/op Binary Neural Network Inference,” in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 37, no. 11, pp. 2940-2951, Nov. 2018.
Y. Liu et al., “Richer Convolutional Features for Edge Detection,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 8, pp. 1939-1946, 1 Aug. 2019.
W. Luo, Y. Li, R. Urtasun and R. Zemel, “Understanding the Effective Receptive Field in Deep Convolutional Neural Networks,” Advances in Neural Information Processing Systems, pp. 4905-4913, 2016.
J. Han and M. Orshansky, “Approximate Computing: An Emerging Paradigm for EnergyEfficient Design,” Proceedings of the 18th IEEE European Test Symposium (ETS), pp. 1-6, 2013.
L. B. Soares, M. M. A. da Rosa, C. M. Diniz, E. A. C. da Costa and S. Bampi, “Exploring Power-Performance-Quality tradeoff of Approximate Adders for Energy Efficient Sobel Filtering,” Proceedings of the IEEE 9th Latin American Symposium on Circuits and Systems (LASCAS), pp. 1-4, 2018.
Y. Chung and Y. Kim, “Comparison of Approximate Computing With Sobel Edge Detection,” IEIE Transactions on Smart Processing and Computing, vol. 10, no. 4, pp. 355-361, 2021.
A. B. Kahng and S. Kang, “AccuracyConfigurable Adder for Approximate Arithmetic Designs,” Proceedings of the 49th Annual Design Automation Conference (DAC), pp. 820825, 2012.
J. Schiel and A. Bainbridge-Smith, “Efficient Edge Detection on Low-Cost FPGAs,” arXiv Preprint arXiv:1512.00504, 2015.
N. Shylashree, M. A. Naik, A. S. Mamatha and V. Sridhar, “Design and Implementation of Image Edge Detection Algorithm on FPGA,” International Journal of Circuits, Systems and Signal Processing, vol. 16, pp. 628-636, 2022.
N. Nausheen, A. Seal, P. Khanna and S. Halder, “A FPGA-Based Implementation of Sobel Edge Detection,” Microprocessors and Microsystems, vol. 56, pp. 84-91, 2018.
AMD Xilinx, Vitis High-Level Synthesis User Guide (UG1399), Version 2023.1, 2023.
AMD Xilinx, Vitis Vision Library User Guide, Version 2023.1, 2023.
AMD, Zynq 7000 SoC Technical Reference Manual (UG585), Version 1.15, 2026.
S. Perri, F. Spagnolo, F. Frustaci and P. Corsonello, “Designing Energy-Efficient Approximate Multipliers,” Journal of Low Power Electronics and Applications, vol. 12, no. 4, Art. 49, 2022.
