
A Study on Bilingual Deep Learning PIS Neural Network Model Based on Graph-Text Modal Fusion
Article Sidebar
Main Article Content
Abstract
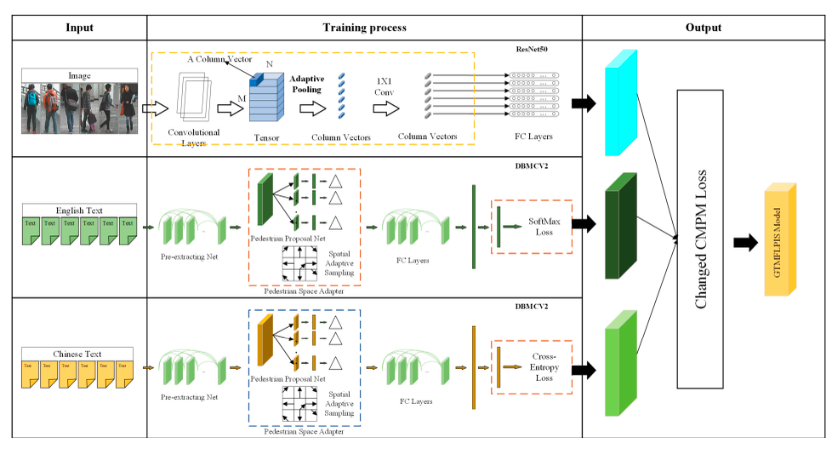
This research investigates a multilingual cross-modal pedestrian information search (PIS) technique based on graph-text modal fusion. Initially, we used a combination of replacement neural networks to improve the English Language-Based Pedestrian Information Search model with Graph-Text Modal Fusion (GTMFLPIS) performance. In addition, existing research lacks GTMFLPIS models for other languages. Therefore, we propose to train GTMFLPIS models for Chinese. The Chinese GTMFLPIS model was trained using our previously constructed Chinese CUHK-PEDES dataset. The Rank1 of the Chinese RN50_PMML12V2 model reached 0.5989. In addition, we found that a single model could not adapt to the limitations of multiple languages. Therefore, we propose a novel architecture to implement a single-model multilingual cross-modal GTMFLPIS model in this research. We propose RN50_DBMCV2 and ENB7_DBM-CV2, both of which have improved performance over the existing ones. We constructed a bilingual dataset using our Chinese CUHK-PEDES dataset and existing English CUHK-PEDES dataset to test our novel multilingual cross-modal GTMFLPIS model. In addition, we found that the loss function significantly impacts the model during our experiments. Therefore, we optimized the performance of the existing loss functions for cross-modal GTMFLPIS models. Our proposed CCMPM loss function improves the performance of the model by 2%. The experimental results of this research show that our proposed model has advantages in improving the accuracy of PIS.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
S. Yang et al., “Towards unified text-based person retrieval: A large-scale multi-attribute and language search benchmark,” Proceedings of the 31st ACM International Conference on Multimedia, pp. 4492-4501, 2023.
Y. Zhao et al., “Learning deep part-aware embedding for person retrieval,” Pattern Recognition, vol. 116, no. 107938, 2021.
S. Kakouros, T. Stafylakis, L. Moˇssner and L. Burget, “Speech-based emotion recognition with self-supervised models using attentive channel-wise correlations and label smoothing,” ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
X. Zang, G. Li and W. Gao, “Multidirection and Multiscale Pyramid in Transformer for Video-Based Pedestrian Retrieval,” in IEEE Transactions on Industrial Informatics, vol. 18, no. 12, pp. 8776-8785, Dec. 2022.
P. Kaur, H. S. Pannu and A. K. Malhi, “Comparative analysis on cross-modal information retrieval: A review,” Computer Science Review, vol. 39, no. 100336, 2021.
Z. Yuan et al., “Remote sensing cross-modal text-image retrieval based on global and local information,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1-16, 2022.
R. Alsaleh, T. Sayed and M. H. Zaki, “Assessing the effect of pedestrians’use of cell phones on their walking behavior: A study based on automated video analysis,” Transportation research record, vol. 2672, no. 35, pp. 46-57, 2018.
D. Jiang and M. Ye, “Cross-modal implicit relation reasoning and aligning for text-to-image person retrieval,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2787-2797, 2023.
Y. Zhao, H. Cheng and C. Huang, “Cross modal pedestrian re-recognition based on attention mechanism,” The Visual Computer, vol. 40, pp. 2405-2418, 2023.
T. Zhou, S. Ruan and S. Canu, “A review: Deep learning for medical image segmentation using multi-modality fusion,”Array, vol. 3-4, no. 100004, 2019.
D. Theckedath and R. R. Sedamkar, “Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks,” SN Computer Science, vol. 1, no. 79, 2020.
M. S. Majib, M. M. Rahman, T. M. S. Sazzad, N. I. Khan and S. K. Dey, “VGG-SCNet: A VGG Net-Based Deep Learning Framework for Brain Tumor Detection on MRI Images,” in IEEE Access, vol. 9, pp. 116942-116952, 2021.
U. Atila, M. U¸car, K. Akyol and E. U¸car, “Plant leaf disease classification using EfficientNet deep learning model,” Ecological Informatics, vol. 61, no. 101182, 2021.
L. C. Passaro et al., “UNIPI-NLE at CheckThat! 2020: Approaching fact checking from a sentence similarity perspective through the lens of transformers,” CEUR Workshop Proceedings, vol. 2696, 2020.
R. A. Frick and I. Vogel, “Fraunhofer SIT at CheckThat!-2022: Ensemble Similarity Estimation for Finding Previously Fact-Checked Claims,” CEUR Workshop Proceedings, vol. 3180, 2022.
H. Dang, K. Lee, S. Henry and O Uzuner, “Ensemble BERT for classifying medication mentioning tweets,” Proceedings of the Fifth Social Media Mining for Health Applications Workshop & Shared Task, pp. 34-41, 2020.
J. Kapoˇci¯ut˙e-Dzikien˙e, A. Salimbajevs and R. Skadi¸nˇs, “Monolingual and cross-lingual intent detection without training data in target languages,” Electronics, vol. 10, no.12:1412, 2021.
J. F. Rodr´ıguez, A. J. Fern´andez-Garc´ıa and E Verd´u, “Semantic Similarity Between Medium-Sized Texts,” Management of Digital EcoSystems, pp. 361-373, 2024.
S. Mishra and S. Mishra, “3Idiots at HASOC 2019: Fine-tuning Transformer Neural Networks for Hate Speech Identification in Indo-European Languages,” CEUR Workshop Proceedings (FIRE 2019), vol. 2517, 2019.
Y. Chen et al., “Tipcb: A simple but effective part-based convolutional baseline for text-based person search,” Neurocomputing, vol. 494, pp. 171-181, 2022.
Y. Zhang and H. Lu, “Deep cross-modal projection learning for image-text matching,” Proceedings of the European conference on computer vision (ECCV), pp. 1-16, 2018.
F. Shen et al., “Pedestrian-specific bipartite-aware similarity learning for text-based person retrieval,” Proceedings of the 31st ACM International Conference on Multimedia, pp. 8922-8931, 2023.
Z. LIU and P. WAN, “Pedestrian reidentification feature extraction method based on attention mechanism,” Journal of Computer Applications, vol. 40, no. 3, p. 672, 2023.
L. Zhang et al., “Cross-modality interactive attention network for multispectral pedestrian detection,” Information Fusion, vol. 50, pp. 20-29, 2019.
Xie and Qu, “A Study on Chinese Language Cross-Modal Pedestrian Image Information Retrieval,” Songklanakarin Journal of Science and Technology (SJST), 2024.
