
Observation-Based Hybrid Classification Algorithms for Customer Segmentation
Article Sidebar
Main Article Content
Abstract
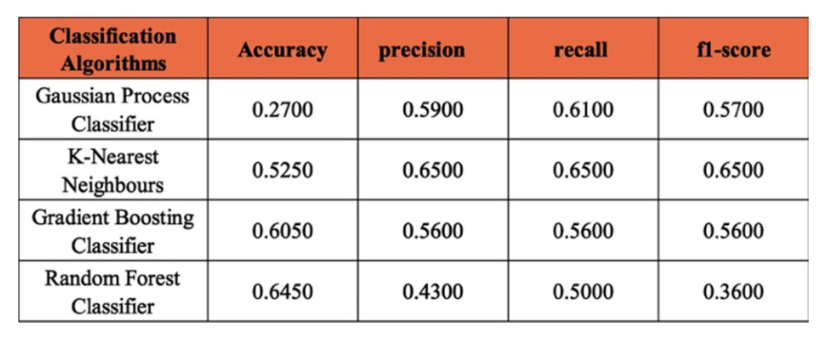
The customer segmentation model aims to cluster customers based on their specific characteristics. Relying solely on a simple classification algorithm may not yield optimal results. Our research proposes an Observation- Based Hybrid Classification (OBHC) algorithm to enhance the customer segmentation model by utilizing customer segmentation data from a public source. Observation-based clustering methods differ from simple classification or clustering models by being a hybrid system specifically engineered to boost the performance of predictive models. Furthermore, the focus is on evaluating metric values after clustering to demonstrate performance improvement. The experiments demonstrate signicant performance improvements across various classification algorithms. The most notable enhancement observed with the proposed algorithm is up to 43.86% on average accuracy score, 24.25% on average precision score, 20.25% on average recall score, and 32% on average F1-score, as shown in the experiment section. This research contributes by introducing a novel process for data scientists to tackle customer segmentation challenges, identifying higher performing segments that meet business needs, and providing executives with the exibility to adopt them. The research underscores the significance of employing hybrid models to classify customers better, providing valuable insights for advancing business development and improving customer service.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
V. Miˇskovic, “Machine Learning of Hybrid Classification Models for Decision Support,” in Proceedings of Sinteza 2014 - Impact of the Internet on Business Activities in Serbia and Worldwide, Belgrade, Serbia, pp. 318-323, 2014.
S. R. Gaddam, V. V. Phoha and K. S. Balagani, “K-Means+ID3: A novel method for supervised anomaly detection by cascading K-Means clustering and ID3 decision tree learning methods,” IEEE Transactions on Knowledge and Data Engineering, vol. 19, no. 3, pp. 345–354, Mar. 2007.
T-T. Wong, N. Y. Yang and G-H. Chen, “Hybrid Classification Algorithms Based on Instance Filtering,” Information Sciences, vol. 520, pp. 445-455, 2020.
J. Xiao, Y. Tian, L. Xie and J. Huang, “A Hybrid Classification Framework Based on Clustering,” IEEE Transactions on Industrial Informatics, vol. 16, no. 7, pp. 4757-4768, Jul. 2020.
L. Zhang, F. Lu, A. Liu, P. Guo and C. Liu, “Application of K-Means Clustering Algorithm for Classification of NBA Guards,” International Journal of Science and Engineering Applications, vol. 5, no. 1, pp. 1-6, 2016.
A. Deligiannis, C. Argyriou and D. Kourtesis, “Predicting the optimal date and time to send personalized marketing messages to repeat buyers,” International Journal of Advanced Computer Science and Applications, vol. 11, no. 4, 2020.
K. Tabianan, S. Velu and V. Ravi, “K-Means Clustering Approach for Intelligent Customer Segmentation Using Customer Purchase Behavior Data,” Sustainability, vol. 14, no. 12, p. 7243, 2022.
P. Coelho, M. Vilares, D. Ball, S. Coelho and M. Vilares, “Service Personalization and Loyalty,” Journal of Services Marketing, vol. 20, no. 7, pp. 462-472, 2006.
K. Kanokngamwitroj and C. Srisa-An, “Personalized Learning Management System using a Machine Learning Technique,” TEM Journal, vol. 11, no. 4, pp. 1626-1633, 2022.
J. Erman, M. Arlitt and A. Mahanti, “Traffic Classification Using Clustering Algorithms,” in Proceedings of the 2006 SIGCOMM Workshop on Mining Network Data, MineNet’06, Pisa, Italy, pp. 281-286, 2006.
I. Lewaa, “Customer Segmentation Using Machine Learning Model: An Application of RFM Analysis,” Journal of Data Science and Intelligent Systems, vol. 2, no. 1, pp. 1-16, Sep. 2023.
X. Li and Y. S. Lee, “Customer Segmentation Marketing Strategy Based on Big Data Analysis and Clustering Algorithm,” Journal of Cases on Information Technology, vol. 26, no. 1, pp. 1-16, 2024.
H. Altartouri, H. Tamimi, and Y. Ashhab, “The impact of pre-clustering on classification of heterogeneous protein data,” Network Modeling Analysis in Health Informatics and Bioinformatics, vol. 11, no. 1, p. 3, 2022.
J. Wu and Z. Lin, “Research on customer segmentation model by clustering,” in Proceedings of the 2005 International Conference on Management Science and Engineering, Zhang Jia Jie, China, pp. 316-318, 2005.
A. Alghamdi, “A Hybrid Method for Customer Segmentation in Saudi Arabia Restaurants Using Clustering, Neural Networks, and Optimization Learning Techniques,” Arabian Journal for Science and Engineering, vol. 48, pp. 2031-2039, 2022.
N. Gautam and N. Kumar, “Customer segmentation using k-means clustering for developing sustainable marketing strategies,” Business Informatics, vol. 16, no. 1, pp. 72–82, 2022.
A. Hiziroglu, “Soft computing applications in customer segmentation: State-of-art review and critique,” Expert Systems with Applications, vol. 40, no. 16, pp. 6491–6507, 2013.
M. Mosa, N. Agami, G. Elkhayat, and M. Kholief, “A novel hybrid segmentation approach for decision support: A case study in banking,” The Computer Journal, vol. 66, no. 5, pp. 1228–1240, 2023.
