
Thai Question-Answering System Using Similarity Search and LLM
Article Sidebar
Main Article Content
Abstract
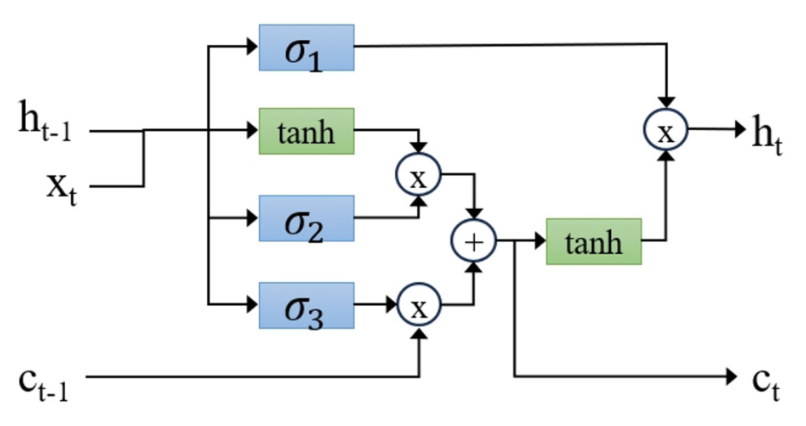
A question-answering (QA) system is essential to an organization where numerous QA pairs respond to customer queries. Choosing the right pair corresponding to the query is a complex task. Although the QA system from a commercial product like ChatGPT provides an excellent solution, it is costly, and the fine-tuned Large Language Model (LLM) cannot be downloaded for private use at the local site. In addition, the cost of using such LLM may significantly increase when the number of users grows. We propose a Thai QA system that can swiftly respond and correctly match the user query to the reference answer in the QA dataset. The proposed system encodes both QA pairs and a query into individual embeddings and finds a couple of QA pairs that are most related to the query by using the fast similarity search called Faiss (Facebook AI Similarity Search.) Afterward, the relevant QA pairs and the query are fed to the fine-tuned LLM (WangchanBERTa - pretraining multilingual transformer-based) to choose the single best match QA pair. The fine-tuned WangchanBERTa can retrieve the correct answer and respond to the query naturally. The experiment conducted on the Thai Wiki QA dataset indicates the superior ROUGE values, precision, recall, F1-score, and runtime of the proposed system against other strategies.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
S. K. Dwivedi and V. Singh, “Research and Reviews in Question Answering System,” Procedia Technology, vol. 10, pp.417-424, 2013.
H. Chung, Y. Song, K.S. Han, D.S. Yoon, J. Y. Lee and H. C. Rim, “A Practical QA System in Restricted Domains,” Workshop on Question Answering in Restricted Domains, pp. 39-45, 2004.
X. Hao, X. Chang and K. Liu, “A Rule-based Chinese Question Answering System for Reading Comprehension Tests,” The 3rd International Conference on International Information Hiding and Multimedia Signal Processing (IIH-MSP 2007), pp. 325-329, 2007.
A. Mishra, N. Mishra and A. Agrawal, “Contextaware Restricted Geographical Domain Question Answering System,” Proceedings of IEEE International Conference on Computational Intelligence and Communication Networks (CICN), pp. 548-553, 2010.
L. Han, Z. T. Yu, Y. X. Qiu, X. Y. Meng, J. Y. Guo and S. T. Si, “Research on Passage Retrieval Using Domain Knowledge in Chinese Question Answering System,” International Conference on Machine Learning and Cybernetics, pp. 2603-2606, 2008.
K. Zhang and J. Zhao, “A Chinese QuestionAnswering System with Question Classification and Answer Clustering,” Proceedings of IEEE International Conference on Fuzzy Systems and Knowledge Discovery, pp. 2692-2696, 2010.
H. Cui, M. Y. Kan and T. S. Chua, “Soft Pattern Matching Models for Definitional Question Answering,” ACM Transactions on Information Systems, vol. 25, no. 2, pp. 1-30, 2007.
C. Unger, L. Bu ̈hmann, J. Lehmann, N. AC. Ngonga, D. Gerber and P. Cimiano, “Templatebased Question Answering Over RDF Data,” Proceedings of the ACM 21st International Conference on World Wide Web, pp. 639-648, 2012.
E. Prud’hommeaux and A. Seaborne, “SPARQL Query Language for RDF,” 2008. Retrieved from http://www.w3.org/TR/rdf-sparql-query
W. Jitkrittum, C. Haruechaiyasak and T. Theeramunkong, “QAST: Question Answering System for Thai Wikipedia,” Proceedings of the 2009 Workshop on Knowledge and Reasoning for Answering Questions, pp. 11-14, 2009.
H. Decha and K. Patanukhom, “Development of Thai Question-Answering System,” Proceedings of the 3rd International Conference on Communication and Information Processing, pp. 124-128, 2017.
W. Rueangkhajorn and J. H. Chan, “Question Answering Model in Thai by Using Squad Thai Wikipedia Dataset,” TechRxiv, 2021. https://doi.org/10.36227/techrxiv.17195000.v1
W. Rueangkhajorn, “thai-xlm-roberta-base-squad2,” 2021. Retrieved from https://huggingface.co/wicharnkeisei/thaixlm-roberta-base-squad2
T. Noraset, L. Lowphansirikul and S. Tuarob, “WabiQA: A Wikipedia-Based Thai QuestionAnswering System,” Information Processing & Management, vol. 58, no. 1, pp. 102431, 2021.
S.ChotiratandP.Meesad,“AutomaticQuestion and Answer Generation from Thai Sentences,” Lecture Notes in Networks and Systems, vol. 453, pp. 163-172, 2022.
T. Lapchaicharoenkit and P. Vateekeul, “Machine Reading Comprehension Using MultiPassage BERT with Dice Loss on Thai Corpus,” ECTI Transactions on Computer and Information Technology (ECTI-CIT), vol. 16, no. 2, pp. 125-134, 2022.
P. Wongpraomas, C. Soomlek, W. Sirisangtragul and P. Seresangtakul, “Thai QuestionAnswering System Using Pattern-Matching Approach,” International Conference on Technology Innovation and Its Applications, pp. 1-5, 2022.
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Kuttler, M. Lewis, W. Yih, T. Rockta ̈schel, S. Riedel and D. Kiela, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” ArXiv, pp. 119, 2020.
Q. Le and T. Mikolov, “Distributed Representations of Sentences and Documents,” Proceedings of the 31st International Conference on Machine Learning, in Proceedings of Machine Learning Research, vol. 32, no. 2, pp. 1188-1196, 2014.
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embeddings Using Siamese BERTNetworks,” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pp. 3982-3992, 2019.
S. Hochreiter and J. Schmidhuber, “Long ShortTerm Memory,” Neural Computing, vol. 9, no. 8, pp. 1735-1780, 1997.
L. Lowphansirikul, C. Polpanumas, N. Jantrakulchai and S. Nutanong, “WangchanBERTa: Pretraining Transformer-based Thai Language Models,” ArXiv, pp. 1-24, 2021.
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer and V. Stoyanov, “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” ArXiv, pp. 1-13, 2019.
P. He, X. Liu, J. Gao and W. Chen, “DeBERTa: Decoding-enhanced BERT with Disentangled Attention,” ArXiv, pp. 1-23, 2021.
J. Johnson, M. Douze and H. Jegou, “Billionscale Similarity Search with GPUs,” IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535-547, 2019.
C. Y. Lin, “ROUGE: A Package for Automatic Evaluation of Summaries,” Proceedings of the Workshop on Text Summarization Branches Out, pp. 74-81, 2004.
K. Trakultaweekoon, S. Thaiprayoon, P. Palingoon and A. Rugchatjaroen, “The First Wikipedia Questions and Factoid Answers Corpus in the Thai Language,” International Joint Symposium on Artificial Intelligence and Natural Language Processing, pp. 1-4, 2019.
OpenAI. ChatGPT (Mar 14 version) [Large language model], 2023. https://chat.openai.com/chat
