
TIDCB: Text Image Dangerous-Scene Convolutional Baseline
Article Sidebar
Main Article Content
Abstract
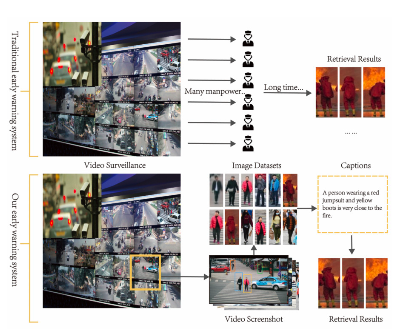
The automatic management of public area safety is one of the most challenging issues in our society. For instance, the timely evacuation of the public during incidents such as fires or large-scale shootings is paramount. However, detecting pedestrian behavior indicative of danger promptly from extensive video surveillance data may not always be feasible. This may result in untimely warnings being provided, resulting in signicant loss of life. Although existing research has proposed text-based person search, it has primarily focused on pedestrian search by matching images of pedestrian body parts to text, lacking the search for pedestrians in dangerous scenarios. To address this gap, this paper proposes an innovative warning framework that further searches for individuals in hazardous situations based on textual descriptions, aiming to prevent or mitigate crisis events. We have constructed a new public safety dataset named CHUK-PEDES-DANGER, one of the first pedestrian datasets that includes dangerous scenes. Additionally, we introduce a novel framework for public automatic evacuation. This framework leverages a multimodal deep learning architecture that combines the image model ResNet-50 with the text model RoBERTa to produce our Text-Image Dangerous-Scene Convolutional Baseline (TIDCB) model, which addresses the classification problem from text to image and image to text by matching images of pedestrian body parts and environments to text. We propose a novel loss function, cross-modal projection matching-triplet (CMPM-Triplet). After conducting extensive experiments, we have validated that our method significantly improves accuracy. Our model outperforms TIPCB with a matching rate of 76.93%, an improvement of 4.78% compared to TIPCB, and demonstrates significant advantages in handling complex scenarios.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao and S. C. Hoi, “Deep learning for person reidentification: A survey and outlook,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no.6, pp. 2872-2893, 2021.
Y. Chen, G. Zhang, Y. Lu, Z. Wang and Y. Zheng, “Tipcb: A simple but effective partbased convolutional baseline for text-based person search,” Neurocomputing, vol. 494, pp. 171-181, 2022.
S. Li, T. Xiao, H. Li, B. Zhou, D. Yue and X. Wang, “Person search with natural language description,” Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1970-1979, 2017.
X. Han, S. He, L. Zhang and T. Xiang, “Text-based person search with limited data,” arXiv preprint, 2021. [Online]. Available:https://doi.org/10.48550/arXiv.2110.10807.
S. Choi and S. Yi,(2022,Septemper 27). “Seven Killed and One Seriously Injured in a Fire at Hyundai Outlet Daejeon Store: Decision Expected on the Application of the Serious Accidents Punishment Act,” https://www.khan.co.kr/national/incident/article/202209261810001.
W. Ngamkham,(2023,Octorber 3 ). “Two dead in shopping mall shooting,” https://www.bangkokpost.com/thailand/general/2656821/two-dead-in-shopping-mall-shooting.
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint,2019. [Online]. Available: https://doi.org/10.48550/arXiv.1907.11692.
H. Yang, P. Liu, S. Li,H. Liu and H. Wang, “A real-time framework for dangerous behavior detection based on deep learning,” Proceedings of the 2022 4th International Conference on Robotics, Intelligent Control and Artificial Intelligence, pp. 1200-1206, 2022.
M. Ravanbakhsh, M. Nabi, E. Sangineto, L. Marcenaro, C. Regazzoni and N. Sebe, “Abnormal event detection in videos using generative adversarial nets,” 2017 IEEE international conference on image processing (ICIP), pp. 1577-1581, 2017.
J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee and A. Y. Ng, “Multimodal deep learning,” Proceedings of the 28th international conference on machine learning (ICML-11), pp. 689-696, 2011.
N. Srivastava and R. Salakhutdinov, “Learning representations for multimodal data with deep belief nets,” International conference on machine learning workshop, pp. 978-1, 2012.
R. Socher, A. Karpathy, Q. V. Le, C. D. Manning and A. Y. Ng, “Grounded compositional semantics for finding and describing images with sentences,” Transactions of the Association for Computational Linguistics, vol. 2, pp. 207-218, 2014.
F. Feng, X. Wang and R. Li, “Cross-modal retrieval with correspondence autoencoder,” Proceedings of the 22nd ACM international conference on Multimedia, pp. 7-16, 2014.
W. Wang, B. C. Ooi, X. Yang, D. Zhang and Y. Zhuang, “Effective multi-modal retrieval based on stacked auto-encoders,” Proceedings of the VLDB Endowment, vol. 7, no.8, pp. 649-660, 2014.
D. Wang, P. Cui, M. Ou and W. Zhu, “Learning compact hash codes for multimodal representations using orthogonal deep structure,” IEEE Transactions on Multimedia, vol. 17, no.9, pp. 1404-1416, 2015.
H. Zhang, Y. Yang, H. Luan, S. Yang and T.-S. Chua, “Start from scratch: Towards automatically identifying, modeling, and naming visual attributes,” Proceedings of the 22nd ACM international conference on Multimedia, pp. 187-196, 2014.
H. Zhang, X. Shang, H. Luan, M. Wang and T.S. Chua, “Learning from collective intelligence: Feature learning using social images and tags,” ACM transactions on multimedia computing, communications, and applications (TOMM), vol. 13, no.1, pp. 1-23, 2016.
Y. Wei, Y. Zhao, C. Lu, S. Wei, L. Liu, Z. Zhu and S.Yan, “Cross-modal retrieval with CNN visual features: A new baseline,” IEEE transactions on cybernetics, vol. 47, no.2, pp. 449-460, 2016.
Y. Peng, X. Huang and J. Qi, “Cross-media shared representation by hierarchical learning with multiple deep networks,” IJCAI, pp. 3853, 2016.
Y. Peng, J. Qi, X. Huang and Y. Yuan, “CCL: Cross-modal correlation learning with multigrained fusion by hierarchical network,” IEEE Transactions on Multimedia, vol. 20, no.2, pp. 405-420, 2017.
J. Qu and A. Shimazu, “Cross-language information extraction and auto evaluation for OOV term translations,” China Communications, vol. 13, no.12, pp. 277-296, 2016.
Z. Zheng, L. Zheng, M. Garrett, Y. Yang, M. Xu and Y.-D. Shen, “Dual-path convolutional image-text embeddings with instance loss,” ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), vol. 16, no.2, pp. 1-23, 2020.
Y. Zhang and H. Lu, “Deep cross-modal projection learning for image-text matching,” Proceedings of the European conference on computer vision (ECCV), pp. 686-701, 2018.
N. Sarafianos, X. Xu and I. A. Kakadiaris, “Adversarial representation learning for text-toimage matching,” Proceedings of the IEEE/CVF international conference on computer vision, pp. 5814-5824, 2019.
Y. Chen, R. Huang, H. Chang, C. Tan, T. Xue and B. Ma, “Cross-modal knowledge adaptation for language-based person search,” IEEE Transactions on Image Processing, vol. 30, pp. 4057-4069, 2021.
K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition,” Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778, 2016.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
Q. Li and J. Qu, “A novel BNB-NO-BK method for detecting fraudulent crowdfunding projects,” Songklanakarin Journal of Science & Technology, vol. 44, no.5, 2022.
A. Hermans, L. Beyer and B. Leibe, “In defense of the triplet loss for person reidentification,” arXiv preprint, 2017. [Online]. Available: https://doi.org/10.48550/arXiv.1703.07737.
