
Detecting Upcoming Patent Keywords by Predicting Keyword Trends Using Patent Keyword Network
Article Sidebar
Main Article Content
Abstract
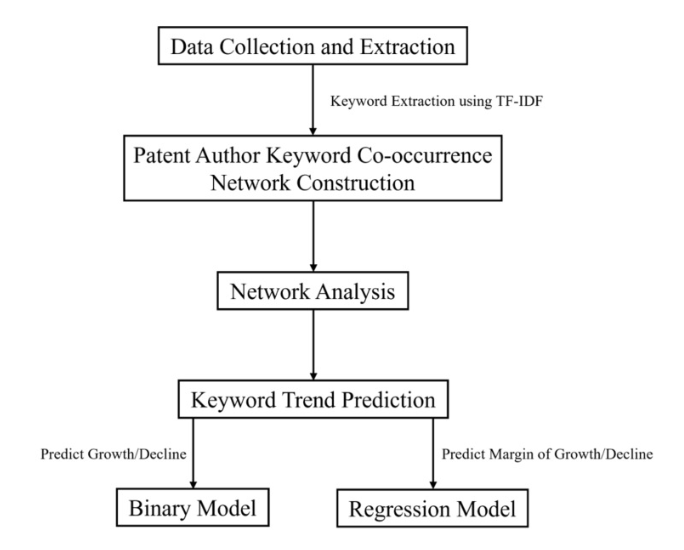
In this ever-changing technological landscape, the ability to quickly predict technological trends becomes crucial for any company or institute engaged in informed decision-making and strategic planning. Data for predicting technological trends can come from various sources such as patent data, which is easily accessible to the public due to the nature of patents. This research is aimed at patent analysis, focusing on combining the keyword- based method, social network analysis (SNA) method, and neural network prediction to propose a feasible keyword trend prediction method based on patent analysis by targeting upcoming keyword trends. More specifically, we utilize Long Short-Term Memory (LSTM) to predict changes in keyword frequency using keyword centralities as input. To assess the effectiveness of the proposed method, we constructed the input dataset using the USPTO patent database in the Information and Communication Technology (ICT) field. We then experimented to compare the proposed method with the benchmark method. Furthermore, to counteract the unbalanced nature of patent data, the SMOGN method is introduced. The results demonstrate its potential for application in broader contexts.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
F. Madani and C. Weber, “The evolution of patent mining: Applying bibliometrics analysis and keyword network analysis,” World Patent Information, vol. 46, pp. 32-48, September 2016.
C. Sternitzke, A. Bartkowski and R. Schramm, “Visualizing patent statistics by means of social network analysis tools,” World Patent Information, vol. 30, no. 2, pp. 115-131, June 2008.
T.-S. Cho and H.-Y.Shih, “Patent citation network analysis of core and emerging technologies in Taiwan: 1997–2008,” Scientometrics, vol. 89, pp. 795-811, July 2011.
A. F. de Paulo and G. S. Porto, “Evolution of collaborative networks of solar energy applied technologies,” Journal of Cleaner Production, vol. 204, pp. 310-320, December 2018.
S. Lee, J. Choi and Y. W. Sawng, “Foresight of promising technologies for healthcare-IoT convergence service by patent analysis,” NIScPR Online Periodicals Repository, vol. 78, no. 8, pp. 489-494, August 2019.
R. Kumari, J. Y. Jeong, B. H. Lee, K. N. Choi and K. Choi, “Topic modelling and social network analysis of publications and patents in humanoid robot technology,” Journal of Information Science, vol. 47, no. 5, pp. 658-676, December 2019.
C. Balili, A. Segev and U. Lee, “Tracking and predicting the evolution of research topics in scientific literature,” 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, pp. 1694-1697, 2017.
W. Lu, S. Huang, J. Yang, Y. Bu, Q. Cheng and Y. Huang, “Detecting research topic trends by author-defined keyword frequency,” Information Processing & Management, vol. 58, no.4:102594, 2021.
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735-1780, 1997.
W. Lou and J. Qiu, “Semantic information retrieval research based on co-occurrence analysis,” Online Information Review, vol. 38, no. 1, pp. 4-23, 2014.
L. C. Freeman, “Centrality in social networks: Conceptual clarification, Social network: critical concepts in sociology. Londres: Routledge, vol. 1, pp. 238-263, 2002.
P. Bonacich, “Technique for analyzing overlapping memberships,” Sociological methodology, vol. 4, pp. 176-185, 1972.
M. E. J. Newman, “A measure of betweenness centrality based on random walks,” Social networks, vol. 27, no. 1, pp. 39-54, January 2005.
A. N. Langville and C. D. Meyer, “A survey of eigenvector methods for web information retrieval,” SIAM review, vol. 47, no. 1, pp. 135-161, 2005.
United States Patent and Trademark Office. (n.d.). Bulk Data Storage System (BDSS) Version 2.0.0. Retrieved January 12, 2022, from https://bulkdata.uspto.gov/
United States Patent and Trademark Office. (n.d.-b). Classification Resources. Retrieved May 4, 2022, from https://www.uspto.gov/web/patents/ classification/cpc/html/cpc.html
J. E. Ramos, “Using TF-IDF to Determine Word Relevance in Document Queries,” in Proceedings of the first instructional conference on machine learning, vol. 242, no. 1, pp. 29-48, December 2003.
A. J. C. Trappey, C. V. Trappey and C. Y. Wu, “Automatic patent document summarization for collaborative knowledge systems and services,” Journal of Systems Science and Systems Engineering, vol. 18, pp. 71-94, 2009.
A. Landherr, B. Friedl and J. Heidemann, A critical review of centrality measures in social networks,” Business & Information Systems Engineering, vol. 2, pp. 371-385, October 2010.
E. J. Yates and L. C. Dixon, “PageRank as a method to rank biomedical literature by importance,” Source code for biology and medicine, vol. 10, no. 1, pp. 1-9, 2015.
P. Branco, L. Torgo and R. P. Ribeiro, “SMOGN: a Pre-processing Approach for Imbalanced Regression,” Proceedings of Machine Learning Research, vol. 74, pp. 36-50, 2017.
Mean Squared Error, The Concise Encyclopedia of Statistics, New York, Springer, 2008, pp. 337–339.
T. Gneiting and A. E. Raftery, “Strictly Proper Scoring Rules, Prediction, and Estimation,” Journal of the American statistical Association, vol. 102, no. 477, pp. 359-378, 2007.
L. Torgo, R. P. Ribeiro, B. Pfahringer and P. Branco, “SMOTE for regression,” in Progress in Artificial Intelligence, pp. 378-389, September 2013.
F. Pedregosa el at. , “Scikit-learn: Machine Learning in Python,” Journal of Machine Learn-
ing Research, vol. 12, pp. 2825–2830, 2011.
A. Hagberg, P. J. Swart and D. A. Schult, “Exploring network structure, dynamics, and function using NetworkX,” SCIPY 08, no. LAUR-08-05495; LA-UR-08-5495). Los Alamos National Lab.(LANL), Los Alamos, United States, 2008.
N. Kunz, (2020). SMOGN: Synthetic Minority Over-Sampling Technique for Regression with Gaussian Noise (Version v0.1.2). Retrieved from https://pypi.org/project/smogn/
T. Chai and R. R. Draxler, “Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature,” Geoscientific model development, vol. 7, no. 3, pp. 1247-1250, 2014
C. Lewis-Beck and M. Lewis-Beck, “Applied regression: An introduction,” Sage publications, vol. 22, 2015.
J. R. Taylor and W. Thompson, “An introduction to error analysis: the study of uncertainties in physical measurements, University science books, vol. 2, pp. 193-200, Mill Valley, CA, 1982.
C. Goutte and E. Gaussier, “A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation,” Advances in Information Retrieval, Springer, Berlin, Heidelberg, pp. 345–359, 2005.
M. D. Zeiler, “Adadelta: an adaptive learning rate method,” arXiv preprint, arXiv:1212.5701, 2012.
F. Chollet, “Keras,” GitHub. Retrieved 2015, from https://github.com/fchollet/keras.
J. Choi and Y.-S. Hwang, “Patent keyword network analysis for improving technology development efficiency,” Technological Forecasting and Social Change, vol. 83, pp. 170-182, March 2014.
