
Automated Knowledge Integration from Heterogeneous Data Sources Using Text Analytics: A Case Study of COVID-19
Article Sidebar
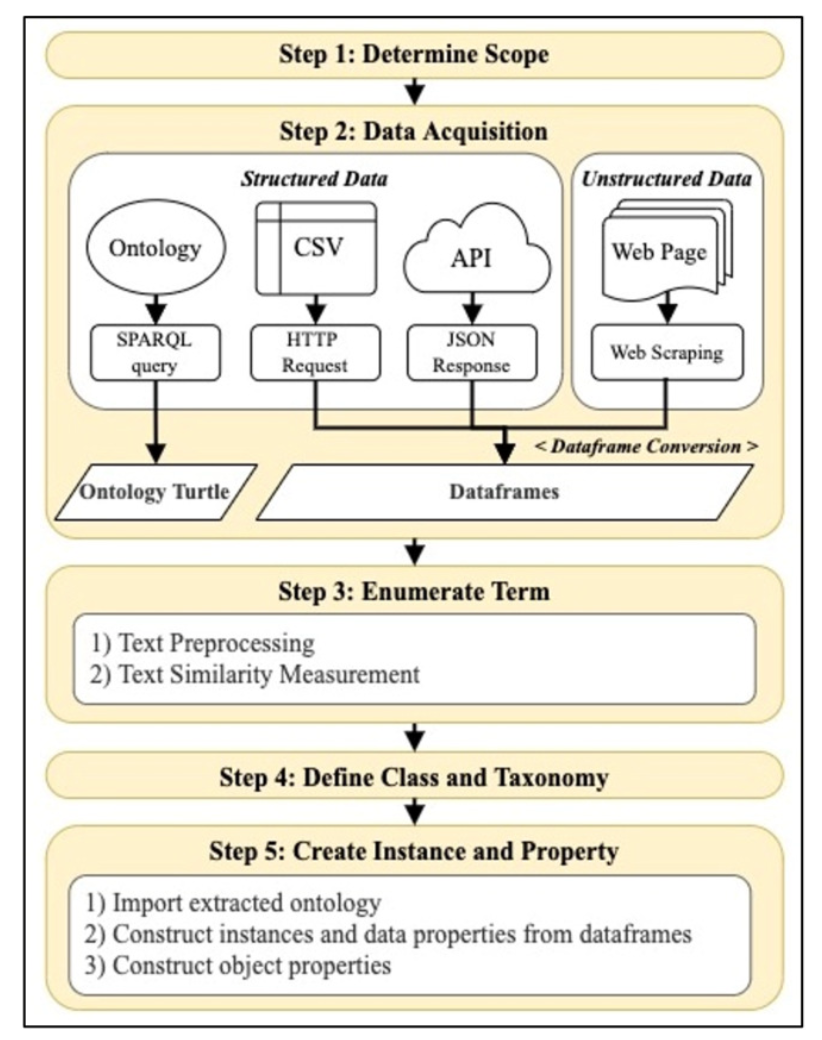
Main Article Content
Abstract
Gathering information from multiple data sources takes a long time to collect, analyze, and classify. Furthermore, if the data sources have different data structures, the merged data structure must support such heterogeneity. In addition, semantic of data must also be considered. This paper proposes automated knowledge integration from heterogeneous data sources using ontology engineering combined with text analytics. Text stemming is used to preprocess data. Part-of-speech (POS) tagging, Universal Dependencies (UD), and text similarity measurement called cosine similarity are used to analyze and integrate data. Our work focuses on five COVID- 19 knowledge scopes: COVID-19, coronaviruses, diseases, pandemics, and vaccines. For evaluation, six ontologies were constructed with six different cosine similarity values ranging from 0.5 to 1.0. Each constructed ontology has COVID-19 related and non-COVID-19 data in a ratio of 70 to 30. The six constructed ontologies were evaluated for consistency with the original data. Using cosine similarity with 0.6, precision, recall, and F1-score are 0.82, 0.71, and 0.76, respectively, and the constructed ontology is optimal, containing the highest amount of relevant COVID-19 information for this case study.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
N. K. Soe, T. T. Yee and E. C. Htoon, “Semantic Layer Construction for Big Data Integration,” 2020 International Conference on Advanced Information Technologies (ICAIT), Yangon, Myanmar, pp. 24-29, 2020.
A. Berko et al., “Application of Ontologies And Meta-Models for Dynamic Integration of Weakly Structured Data,” 2020 IEEE Third International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, pp. 432-437, 2020.
A. V. Saurkar, K. G. Pathare and S. A. Gode, “An Overview on Web Scraping Techniques and Tools,” 2018 International Journal on Future Revolution in Computer Science & Communication Engineering (ijfrcsce), vol. 4, pp. 363–367, Apr. 2018.
D. M. Thomas and S. Mathur, “Data Analysis by Web Scraping using Python,” 2019 3rd International conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, pp. 450-454, 2019.
M. M. Fouad, T. F. Gharib and A. S. Mashat, “Efficient Twitter Sentiment Analysis System with FeatureSelection and Classifier Ensemble,” 2018 The International Conference on Advanced Machine Learning Technologies and Applications (AMLTA), Cairo, Egypt, Jan. 2018. HLinguistics, Cambridge, MA: MIT Press, pp. 255–308, Jun. 2021.
X. Xue, H. Wang, J. Zhang and Y. Huang, “Matching Transportation Ontologies with Word2Vec and Alignment Extraction Algorithm,” in 2021 Journal of Advanced Transportation, Hindawi, May 2021.
G. Antoniou, P. Groth, F. van Harmelen and R. Hoekstra, A Semantic Web Primer, Third Edition. London, England: The MIT Press, 2012.
C. M. Keet, An Introduction to Ontology Engineering, College Publications, 2018.
N. Rastogi, P. Verma and P. Kumar, “Evaluation of Information Retrieval Performance Metrics using Real Estate Ontology,” 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, pp. 102-106, 2020.
E. R. Swedia, A. B. Mutiara, M. Subali, and Ernastuti, “Deep Learning Long-Short Term Memory (LSTM) for Indonesian Speech Digit Recognition using LPC and MFCC Feature,” in 2018 Third International Conference on Informatics and Computing (ICIC), pp. 1–5, Oct. 2018.
The SPARQLWrapper Development Team, SPARQLWrapper Documentation, 2022. [Online]. Available: https://sparqlwrapper.readthedocs.io/en/latest/
E. Winters et al., disease.sh An open API for disease-related statistics, 2022. [Online]. Available: https://disease.sh/docs/
The urllib3 Development Team, urllib3 Documentation, 2023. [Online]. Available: https://urllib3.readthedocs.io/en/stable/
H. Matthew and I. Montani, spaCy: Industrialstrength Natural Language Processing in Python, 2022. [Online]. Available: https://spacy.io/usage
M. Horridge, “A Practical Guide To Building OWL Ontologies Using Prot ́eg ́e 4 and CO-ODE Tools Edition 1.3,” The University of Manchester, Mar. 2011.
The Apache Jena Project Team, Apache Jena Fuseki, The Apache Software Foundation, 2022. [Online]. Available: https://jena.apache.org/documentation/fuseki2/
The Django Software Foundation, Django, The Django Software Foundation, 2022. [Online]. Available: https://www.djangoproject.com/foundation/
N. Kanya and T. Ravi, “Modelings and techniques in Named Entity Recognition-an Information Extraction task,” IET Chennai 3rd International on Sustainable Energy and Intelligent Systems (SEISCON 2012), Tiruchengode, pp. 15, 2012.
A. I. A. Aldine, M. Harzallah, B. Giuseppe, N. B ́echet and A. Faour, “Redefining Hearst Patterns by using Dependency Relations,” in Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management(IC3K2018), vol.2, pp. 148-155, Jan. 2018.
