
Privacy-Enhancing Data Aggregation for Big Data Analytics
Article Sidebar
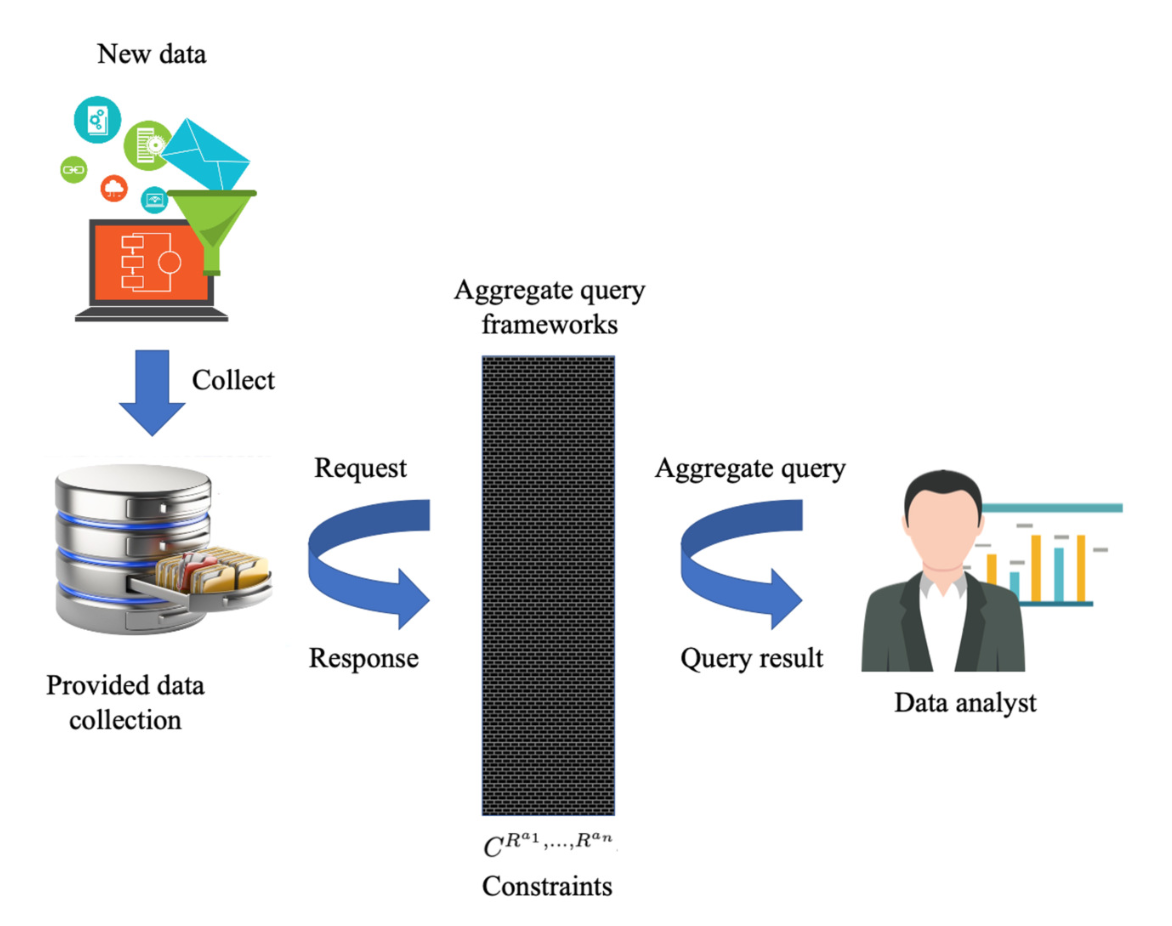
Main Article Content
Abstract
Data utility and data privacy are serious issues that must be considered when datasets are utilized in big data analytics such that they are traded off. That is, the datasets have high data utility and often have high risks in terms of privacy violation issues. To balance the data utility and the data privacy in datasets when they are provided to utilize in big data analytics, several privacy preservation models have been proposed, e.g., k-Anonymity, l-Diversity, t-Closeness, Anatomy, k-Likeness, and (lp1, . . . , lpn)-Privacy. Unfortunately, these privacy preservation models are highly complex data models and still have data utility issues that must be addressed. To rid these vulnerabilities of these models, a new privacy preservation model is proposed in this work. It is based on aggregate query answers that can guarantee the confidence of the range and the number of values that can be re-identified. Furthermore, we show that the proposed model is more effcient and effective in big data analytics by using extensive experiments.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
D. Agrawal, P. Bernstein, E. Bertino, S. Davidson, U. Dayal, M. Franklin, J. Gehrke, L. Haas, A. Halevy, J. Han, et al. Challenges and opportunities with big data 2011-1. 2011.
T. H. Davenport, P. Barth and R. Bean, How’big data’is different, 2012.
Z. Zheng, J. Zhu and M. R. Lyu, “Servicegenerated big data and big data-as-a-service: an overview,” in 2013 IEEE international congress on Big Data, pp. 403–410, 2013.
S. Sagiroglu and D. Sinanc, “Big data: A review,” in 2013 international conference on collaboration technologies and systems (CTS), pp. 42–47, 2013.
X. Wu, X. Zhu, G.-Q. Wu and W. Ding, “Data mining with big data,” IEEE transactions on knowledge and data engineering, vol. 26, no. 1, pp. 97– 107, 2013.
M. Chen, S. Mao and Y. Liu, “Big data: A survey,” Mobile networks and applications, vol. 19, no. 2, pp. 171–209, 2014.
A. Mohamed, M. K. Najafabadi, Y. B. Wah, E. A. K. Zaman and R. Maskat, “The state of the art and taxonomy of big data analytics: view from new big data framework,” Artificial Intelligence Review, vol. 53, no. 2, pp. 989–1037, 2020.
Y. Cui, S. Kara and K. C. Chan, “Manufacturing big data ecosystem: A systematic literature review,” Robotics and computer-integrated Manufacturing, vol. 62, no. 0101861, 2020.
W. Haoxiang, et al. “Big data analysis and perturbation using data mining algorithm, Journal of Soft Computing Paradigm (JSCP), vol. 3, no. 1, pp. 19–28, 2021.
J. Wang, C. Xu, J. Zhang and R. Zhong, “Big data analytics for intelligent manufacturing systems: A review,” Journal of Manufacturing Systems, vol. 62, pp. 738–752, 2022.
M. Naeem, et al. “Trends and future perspective challenges in big data,” in Advances in intelligent data analysis and applications, pp. 309– 325. Springer, 2022.
B. K. Chan, “Data analysis using r programming,” in Biostatistics for Human Genetic Epidemiology, pp. 47–122. Springer, 2018.
E. Kaya, M. Agca, F. Adiguzel and M. Cetin, “Spatial data analysis with r programming for environment,” Human and ecological risk assessment: An International Journal, vol. 25, no. 6, pp. 1521– 1530, 2019.
J. Nandimath, E. Banerjee, A. Patil, P. Kakade, S. Vaidya and D. Chaturvedi, “Big data analysis using apache hadoop,” in 2013 IEEE 14th International Conference on Information Reuse & Integration (IRI), pp. 700–703, 2013.
O. Azeroual and R. Fabre, “Processing big data with apache hadoop in the current challenging era of covid-19,” Big Data and Cognitive Computing, vol. 5, no.1:12, 2021.
E. Nazari, M. H. Shahriari and H. Tabesh, “Big data analysis in healthcare: apache hadoop, apache spark and apache flink,” Frontiers in Health Informatics, vol. 8, no. 1:14, 2019.
M. Hofmann and R. Klinkenberg, “RapidMiner: Data mining use cases and business analytics applications,” CRC Press, 2016.
V. Kotu and B. Deshpande, “Predictive anaytics and data mining: concepts and practice with rapidminer,” Morgan Kaufmann, 2014.
A. Boranbayev, G. Shuitenov and S. Boranbayev, “The method of analysis of data from social networks using rapidminer, in Science and Information Conference, pp. 667–673. Springer, 2020.
M. Copeland, J. Soh, A. Puca, M. Manning and D. Gollob, “Microsoft azure,” New York, NY, USA:: Apress, pp. 3–26, 2015.
Ro. Barga, V. Fontama, W. H. Tok and L. Cabrera-Cordon, “Predictive analytics with Microsoft Azure machine learning,” Springer, 2015.
B. Gupta, P. Mittal and T. Mufti, “A review on amazon web service (aws), microsoft azure & google cloud platform (gcp) services,” in Proceedings of the 2nd International Conference on ICT for Digital, Smart, and Sustainable Development, ICIDSSD 2020, 27-28 February 2020, Jamia Hamdard, New Delhi, India, 2021.
A. K. Sandhu, “Big data with cloud computing: Discussions and challenges,” Big Data Mining and Analytics, vol. 5, no. 1, pp. 32–40, 2021.
Y. Gahi, M. Guennoun and H. T. Mouftah, “Big data analytics: Security and privacy challenges,” in 2016 IEEE Symposium on Computers and Communication (ISCC), pp. 952–957, 2016.
T. Wang, Z. Zheng, M. H. Rehmani, S. Yao and Z. Huo, “Privacy Preservation in Big Data From the Communication Perspective—A Survey,” in IEEE Communications Surveys & Tutorials, vol. 21, no. 1, pp. 753-778, Firstquarter 2019.
Q. Zhang, L. T. Yang and Z. Chen, “Privacy Preserving Deep Computation Model on Cloud for Big Data Feature Learning,” in IEEE Transactions on Computers, vol. 65, no. 5, pp. 1351-1362, 1 May 2016.
D. S. Terzi, R. Terzi and S. Sagiroglu, “A survey on security and privacy issues in big data,” in 2015 10th International Conference for Internet Technology and Secured Transactions (ICITST), pp. 202–207, 2015.
O. Tene and J. Polonetsky, “Big data for all: Privacy and user control in the age of analytics,” Northwestern Journal of Technology and Intellectual Property, vol. 11, no. 5, pp. 240-273, 2012.
Z. Lv and L. Qiao, “Analysis of health-care big data,” Future Generation Computer Systems, vol. 109, pp. 103–110, 2020.
H.-N. Dai, H. Wang, G. Xu, J. Wan and M. Imran, “Big data analytics for manufacturing internet of things: opportunities, challenges and enabling technologies,” Enterprise Information Systems, vol. 14, no. 9-10, pp. 1279–1303, 2020.
A. D. Dwivedi, G. Srivastava, S. Dhar and R. Singh, “A decentralized privacy-preserving healthcare blockchain for iot,” Sensors, vol. 19, no. 2:326, 2019.
E. Bertino and E. Ferrari, “Big data security and privacy,” in A comprehensive guide through the Italian database research over the last 25 years, pp. 425–439. Springer, 2018.
W. N. Price and I. G. Cohen, “Privacy in the age of medical big data,” Nature medicine, vol. 25, no. 1, pp. 37– 43, 2019.
L. Sweeney, “k-anonymity: A model for protecting privacy,” International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, vol. 10, no.5, pp. 557–570, oct 2002.
A. Machanava jjhala, J. Gehrke, D. Kifer, and M. Venkitasubramaniam, “L-diversity: privacy beyond k-anonymity,” in 22nd International Conference on Data Engineering (ICDE’06), pp. 24–24, 2006.
N. Li, T. Li and S. Venkatasubramanian, “tCloseness: Privacy Beyond k-Anonymity and lDiversity,” 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, pp. 106-115, 2007.
S. Riyana, N. Harnsamut, T. Soontornphand and J. Natwichai, “(k, e)-Anonymous for Ordinal Data,” 2015 18th International Conference on Network-Based Information Systems, Taipei, Taiwan, pp. 489-493, 2015.
S. Riyana, N. Riyana and S. Nanthachumphu, “ Enhanced (k, e)-anonymous for categorical data,” in Proceedings of the 6th International Conference on Software and Computer Applications, pp. 62–67, 2017.
S. Riyana, S. Nanthachumphu and N. Riyana, “Achieving privacy preservation constraints in missing-value datasets,” SN Computer Science, vol. 1, no. 4, pp. 1–10, 2020.
S. Riyana, N. Riyana and S. Nanthachumphu, “An effective and efficient heuristic privacy preservation algorithm for decremental anonymization datasets,” in International Conference on Image Processing and Capsule Networks, pp. 244–257. Springer, Cham, 2020.
N. Riyana, Surapon Riyana, S. Nanthachumphu, S. Sittisung and D. Duangban, “Privacy violation issues in republication of modification datasets,” in International Conference on Intelligent Computing & Optimization, pp. 938–953. Springer, Cham, 2021.
S. Riyana, N. Riyana, and S. Nanthachumphu, “Privacy preservation techniques for sequential data releasing,” in The 12th International Conference on Advances in Information Technology, pp. 1–9, 2021.
S. Riyana and N. Riyana, “A privacy preservation model for rfid data-collections is highly secure and more efficient than lkc-privacy,” in The 12th International Conference on Advances in Information Technology, pp. 1–11, 2021.
S. Riyana, Privacy preservation models for the independent data release of high-dimensional datasets, 2023.
X. Xiao and Y. Tao, “Anatomy: Simple and effective privacy preservation,” VLDB ’06, pp. 139–150. VLDB Endowment, 2006.
S. Riyana, N. Riyana and W. Sujinda, “An anatomization model for farmer data collections,” SN Computer Science, vol. 2, no. 5, pp. 1–11, 2021.
S. Riyana and N. Riyana, “Achieving anonymization constraints in high-dimensional data publishing based on local and global data suppressions,” SN Computer Science, vol. 3, no. 1, pp. 1–12, 2022.
S. Riyana, N. Ito, T. Chaiya, U. Sriwichai, N. Dussadee, T. Chaichana, R. Assawarachan, T. Maneechukate, S. Tantikul and N. Riyana, “Privacy threats and privacy preservation techniques for farmer data collections based on data shuffling,” ECTI Transactions on Computer and Information Technology (ECTI-CIT), vol. 16, no. 3, pp. 289–301, 2022.
N. Ramakrishnan, B. J. Keller, B. J. Mirza, A. Y. Grama and G. Karypis, “Privacy risks in recommender systems,” in IEEE Internet Computing, vol. 5, no. 6, pp. 54-63, Nov.-Dec. 2001.
S. Riyana and J. Natwichai, “Privacy preservation for recommendation databases,” Service Oriented Computing and Applications, vol. 12, no.3, pp. 259– 273, 2018.
S. Riyana, “(lp1, . . . , lpn)-privacy: privacy preservation models for numerical quasiidentifiers and multiple sensitive attributes,” Journal of Ambient Intelligence and Humanized Computing, pp. 1–17, 2021.
S. Riyana, K. Sasujit, N. Homdoung, T. Chaichana and T. Punsaensri, “Effective privacy preservation models for rating datasets,” ECTI Transactions on Computer and Information Technology (ECTI-CIT), vol. 17, no. 1, pp. 1– 13, 2023.
H. Liang and H. Yuan, “On the complexity of tcloseness anonymization and related problems,” in International Conference on Database Systems for Advanced Applications, pp. 331–345. Springer, 2013.
R. C.-W. Wong, J. Li, A. W.-C. Fu and K. Wang, “(α, k)-anonymity: An enhanced k-anonymity model for privacy preserving data publishing,” in Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’06, New York, NY, USA, , pp. 754–759, 2006.
M. Terrovitis, N. Mamoulis and P. Kalnis, “Privacy-preserving anonymization of set-valued data,” Proceedings of the VLDB Endowment, vol. 1, no. 1, pp. 115–125, Aug. 2008.
B. C. M. Fung, M. Cao, B. C. Desai and H. Xu, “Privacy protection for rfid data,” in Proceedings of the 2009 ACM Symposium on Applied Computing, SAC ’09, New York, NY, USA, pp. 1528–1535, 2009.
S. Riyana and N. Riyana, Simple, effective, and efficient privacy preservation models for rating datasets, 2023.
Q. Zhang, N. Koudas, D. Srivastava and T. Yu, “Aggregate query answering on anonymized tables,” in 2007 IEEE 23rd International Conference on Data Engineering, pp. 116–125, April 2007.
R. Kohavi, “Scaling up the accuracy of naivebayes classifiers: A decision-tree hybrid,” in Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, pp. 202–207. AAAI Press, 1996.
