
Achieving Anatomization Constraints in Dynamic Datasets
Article Sidebar
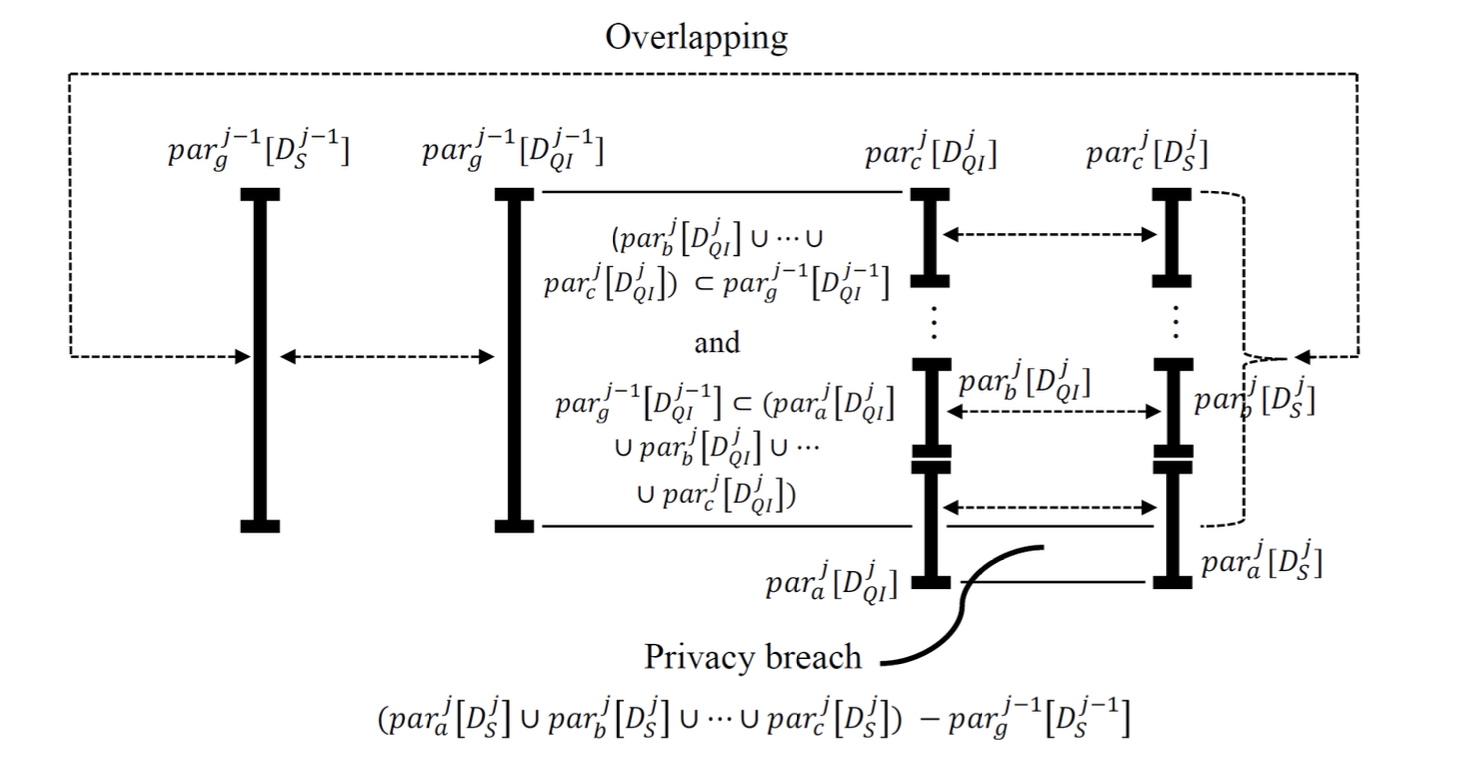
Main Article Content
Abstract
Anatomy is one of the well-known privacy preservation models that are proposed to address privacy violation issues in released datasets. Unfortunately, we found that Anatomy is often sufficient to address privacy violation issues in datasets that are focused on performing a time of data releases. Thus, if datasets are dynamic (i.e., the data is updated when new data becomes available) and they are independently released, Anatomy can be insucient. That is, released datasets are satised by Anatomy constraints, they still have privacy violation issues from data comparison attacks such as iFRCA, iMRCA, iMRcMLA, dFLCA, dMLCA, dMLcMRA, SVM, and partition changing such that they are presented in this work. To address these privacy violation issues in released datasets, a new privacy preservation model is proposed in this work. Furthermore, we show that the proposed model is higher secure in terms of privacy preservation than Anatomy with extensive experiments.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
J.W. Byun, Y. Sohn, E. Bertino and N. Li, “Secure anonymization for incremental datasets,” Secure Data Management. SDM 2006. Lecture Notes in Computer Science, vol. 4165, pp. 48–63, 2006.
C. Dwork, K. Kenthapadi, F. McSherry, I. Mironov and M. Naor, “Our data, ourselves: Privacy via distributed noise generation,” Annual International Conference on the Theory and Applications of Cryptographic Techniques - Advances in Cryptology (EUROCRYPT 2006), vol. 4004, pp. 486–503, 2006.
G. Fung, “A comprehensive overview of basic clustering algorithms,” 2001.
X. He, Y. Xiao, Y. Li, Q. Wang, W. Wang and B. Shi, “Permutation anonymization: Improving anatomy for privacy preservation in data publication,” New Frontiers in Applied Data Mining. PAKDD 2011. Lecture Notes in Computer Science, vol.7104, pp. 111–123, 2012.
V.S. Iyengar, “Transforming data to satisfy privacy constraints,” KDD ’02: Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 279–288, 2002.
M.A. Kadampur and S. D.V.L.N, “A noise addition scheme in decision tree for privacy preserving data mining,” Journal of computing, vol.2, no. 1, pp.137-144, 2010.
S. Kim and Y.D. Chung, “An anonymization protocol for continuous and dynamic privacy- preserving data collection,” Future Generation Computer Systems, vol.93, pp. 1065–1073, 2019.
R. Kohavi, “Scaling up the accuracy of naive- bayes classifiers: A decision-tree hybrid, Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, pp. 202–207, 1996.
B. Korte and L. Lov ́asz, “Mathematical structures underlying greedy algorithms,” Fundamentals of Computation Theory. FCT 1981. Lec- ture Notes in Computer Science, vol. 117, pp. 205–209, 1981.
N. Li, T. Li and S. Venkatasubramanian, “t- Closeness: Privacy Beyond k-Anonymity and l Diversity,” 2007 IEEE 23rd International Conference on Data Engineering, pp. 106-115, 2007.
A. Machanavajjhala, D. Kifer, J. Gehrke and M. Venkitasubramaniam, “L-diversity: Privacy beyond k-anonymity,” ACM Transactions on Knowledge Discovery from Data, vol.1, no.1, pp. 3–es, 2007.
K. Mivule,: Utilizing noise addition for data privacy, an overview (2013)
N. Riyana, S. Riyana, S. Nanthachumphu, S. Sit- tisung and D. Duangban, “Privacy violation issues in re-publication of modification datasets,” Intelligent Computing and Optimization. ICO 2020. Advances in Intelligent Systems and Computing, pp. 938–953, 2021.
S. Riyana, “(lp1,. . .,lpn)-privacy: privacy preservation models for numerical quasi-identifiers and multiple sensitive attributes,” Journal of Ambient Intelligence and Humanized Computing, pp. 1–17, 2021.
S. Riyana, N. Harnsamut, U. Sadjapong, S. Nan- thachumphu and N. Riyana, “Privacy preservation for continuous decremental data publish- ing,” Image Processing and Capsule Networks. ICIPCN 2020. Advances in Intelligent Systems and Computing, vol. 1200, pp. 233–243, 2021.
S. Riyana, N. Ito, T. Chaiya, U. Sriwichai, N. Dussadee, T. Chaichana, R. Assawarachan, T. Maneechukate, S. Tantikul and N. Riyana, “Pri- vacy threats and privacy preservation techniques for farmer data collections based on data shuffling,” ECTI Transactions on Computer and Information Technology (ECTI-CIT), vol.16, no.3, pp. 289–301, 2022.
S. Riyana, S. Nanthachumphu and N. Riyana, “Achieving privacy preservation constraints in missing-value datasets,” SN Computer Science, vol.1, no.4, pp.227, 2020.
S. Riyana and J. Natwichai, “Privacy preservation for recommendation databases,” Service Oriented Computing and Applications, vol.12, no.(3–4), pp.259–273, 2018.
S. Riyana and N. Riyana, “A privacy preservation model for RFID data-collections is highly secure and more ecient than LKC-privacy,” IAIT2021: The 12th International Conference on Advances in Information Technology, no.15, pp. 1–11, 2021.
S. Riyana and N. Riyana, “Achieving anonymization constraints in high-dimensional data publishing based on local and global data suppressions,” SN Computer Science, vol.3, no.1, pp. 1–12, 2022.
S. Riyana, N.Riyana and S. Nanthachum- phu, “An e↵ective and ecient heuristic pri- vacy preservation algorithm for decremental anonymization datasets,” in Chen, J.IZ., Tavares, J.M.R.S., Shakya, S., Iliyasu, A.M. (eds) Image Processing and Capsule Networks. ICIPCN 2020. Advances in Intelligent Systems and Computing, vol.1200 , pp. 244–257, 2021.
S. Riyana, N. Riyana and S. Nanthachumphu, “Privacy preservation techniques for sequential data releasing,” IAIT2021: The 12th International Conference on Advances in Information Technology, no. 24, 2021.
S. Riyana, N. Riyana and W. Sujinda, “An anatomization model for farmer data collections,” SN Computer Science, vol.2 ,no.5, pp.1–11, 2021.
S. Riyana, K. Sasujit, N. Homdoung, T. Chaichana and T. Punsaensri, “E↵ective privacy preservation models,” ECTI Transactions on Computer and Information Technology (ECTI- CIT), vol.17, no.1, pp. 1–13, 2023.
P. Samarati and L. Sweeney, “Protecting privacy when disclosing information: k-anonymity and its enforcement through generalization and sup- pression,” 19 pages, 1998.
L. Sweeney, “k-anonymity: A model for protecting privacy,” International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, vol.10, no.5, pp. 557–570, 2002.
R.C.W. Wong, J. Li, A.W.C. Fu and K. Wang, “(↵, k)-anonymity: An enhanced k-anonymity model for privacy preserving data publishing,” KDD ’06: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 754–759, 2006.
X. Xiaokui and Y. Tao, “Anatomy: Simple and e↵ective privacy preservation,” Proceedings of the 32nd International Conference on Very Large Data Bases, VLDB ’06, pp. 139–150, 2006.
Yong Wang and J. Hodges, “Document clustering with semantic analysis,” Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS’06), vol.3, pp. 54c–54c, 2006.
X. Zhang, C. Liu, S. Nepal and J. Chen, “An efficient quasi-identifier index-based approach for privacy preservation over incremental data sets on cloud,” Journal of Computer and System Sciences, vol.79, no.5, pp. 542–555, 2013.
