
Power Efficient Strassen’s Algorithm using AVX512 and OpenMP in a Multi-core Architecture
Article Sidebar
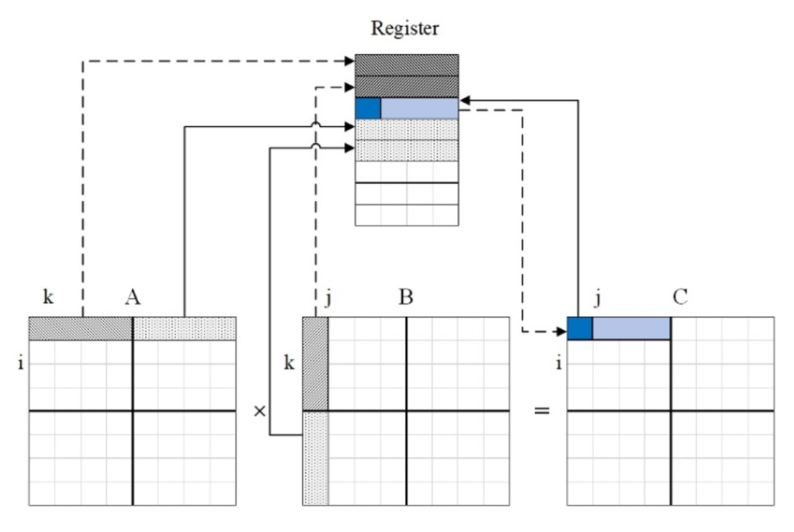
Main Article Content
Abstract
This paper presents an effective implementation of Strassen's algorithm for matrix-matrix multiplication on shared memory multi-core architecture. The proposed algorithm aims to augment the computation speed in terms of GFLOPS performance on average 4.5 and 4.1 times faster than Eigen and OpenBLAS, respectively while reducing the power consumption to as low as possible. Our algorithm relies on using AVX512 intrinsics, loop unrolling factor, and OpenMP directives. A new 2D blocking data allocation pattern is proposed for Strassen's algorithm to provide optimized cache temporal and spatial locality. The proposed implementation reduced not only the amount of main memory but also the burden of unnecessary memory allocation/deallocation and data transferring for each level of recursion in Strassen's algorithm. Moreover, the proposed algorithm consumed, on average, 4.25 and 3.67 times lower energy than the multiplication functions of the Eigen and OpenBLAS libraries, respectively. To measure the computational performance with the awareness of power consumption, GFLOPS per Watt (GFPW) is calculated, which out- performed on average 3.78 and 3.47 times higher than those of Eigen and OpenBLAS libraries, respectively.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
K. Livingston, A. Landwehr, J. Monsalve, S.Zukerman ,B. Meister, G.R. Gao, “Energy Avoiding Matrix Multiply,” International Workshop on Languages and Compilers for Parallel Computing, LCPC 2016: Languages and Compilers for Parallel Computing pp 55-70, vol. 10136, Springer, 2017. https://doi.org/10.1007/978-3-319-52709-3_5.
Y. ByQin, G. Zeng, R. Kurachi, Y.X. Li, Y. Matsubara, and H. Takada, “Energy-Efficient Intra-Task DVFS Scheduling Using Linear Programming Formulation”, IEEE ACCESS, 7 (2019), 30536-30547,
DOI:10.1109/ACCESS.2019.2902353.
T. Jakobs and G. Rünger, "On the Energy Consumption of Load/Store AVX Instructions," 2018 FederatedConference on Computer Science and Information Systems (FedCSIS), Poznan, 2018, pp. 319-327. https://doi.org/10.15439/2018F28.
J. Huang, T. M. Smith, G. M. Henry, and R. A. van de Geijn, “Strassen’s Algorithm Reloaded,” in SC16: International Conference for High Performance Computing, Networking, Storage and Analysis, Article 59, pp.690–701, Salt Lake City, UT, USA, 2016. https://doi.org/10.1109/SC.2016.58.
J.Y. Huang, C.D. Yu, R.A. van de Geijn, A. Robert, “Strassen's Algorithm Reloaded on GPUs,” ACM Transactions on Mathematical Software, 46 (1) (2020), Article Number 1, DOI:10.1145/3372419.
V. Arrigoni, F. Maggioli, A. Massini, and E. Rodolà, “Efficiently Parallelizable Strassen-Based Multiplication of a Matrix by its Transpose,” 50th International Conference on Parallel Processing: ICPP 2021, ACM, Code 172277, Virtual (Online), 9-12 August 2021. DOI:10.1145/3472456.3473519.
Y. Tang and W. Gao, “Processor-Aware Cache-Oblivious Algorithms,” 50th International Conference on Parallel Processing: ICPP 2021, ACM, Code 172277, Virtual (Online), 9-12 August 2021. DOI:10.1145/3472456.3472506.
V.B.Kreyndelin and E.E.Grigorieva, “Fast matrix multiplication algorithm for a bank of digital filters,” 2021 Systems of Signal Synchronization, Generating and Processing in Telecommunications, SYNCHROINFO 2021, Article number 9488350, Svetlogorsk, Kaliningrad Region, 30 June-2 July 2021, DOI:10.1109/SYNCHROINFO51390.2021.9 0.2021.9488350.
H.Kang, H.C.Kwon, and D.Kim, “HPMaX: heterogeneous parallel matrix multiplication using CPUs and GPUs,” Computing, 102(12), pp. 2607-26311, December 2020. DOI: 10.1007/s00607-020-00846-1.
A. J. Kawu, A. Yahaya Umar and S. I. Bala, "Performance of one-level recursion parallel Strassen's algorithm on dual core processor," 2017 IEEE 3rd International Conference on Electro-Technology for National Development (NIGERCON), Owerri, pp. 587-591, 2017. https://doi.org/10.1109/NIGERCON.2017.8281929.
L. Chen, P. Wu, Z. Chen, R. Ge and Z. Zong, "Energy Efficient Parallel Matrix-Matrix Multiplication for DVFS-enabled Clusters," 2012 41st International Conference on Parallel Processing Workshops, Pittsburgh, PA, pp. 239-245, 2012. https://doi.org/10.1109/ICPPW.2012.36.
H. Zamani, Y. Liu, D. Tripathy, B. Laxmi, and C. Zizhong, “GreenMM: energy efficient GPU matrix multiplication through undervolting,” In Proceedings of the ACM International Conference on Supercomputing, New York, USA, pp. 308–318, 2019, https://doi.org/10.1145/3330345.3330373.
K. Kashif Nizam, H. Mikael, N. Tapio, Jukka K. Nurminen, and Zhonghong Ou, “RAPL in Action:Experiences in Using RAPL for Power Measurements,” ACM Transactions on Modeling and Performance Evaluation of Computing Systems, Vol. 3, No.2, Article 9, April 2018, page-26, https://doi.org/10.1145/3177754.
E. Rotem, A. Naveh, A. Ananthakrishnan, E. Weissmann, and D. Rajwan, “Power Management architecture of the intel microarchitecture Code-Named sandy bridge,” IEEE Micro, vol. 32, no. 2, pp. 20–27, March 2012. https://doi.org/10.1109/MM.2012.12.
T. Jakobs, M. Hofmann, and G. Runger, “Reducing the power consumption of matrix multiplications by vectorization,” In Proceedings of the 19th IEEE International Conference on Computational Science and Engineering (CSE 2016), pages 1–8, August 2016. https://doi.org/10.1109/CSE-EUC-DCABES.2016.187.
J. Haj-Yahya, A. Mendelson, Y. Ben-asher and A. Chattopadhyay, (2018), “Compiler-Directed Energy Efficiency,” Springer, pages 107-133, https://doi.org/10.1007/978-981-10-8554-3_4.
K. Momcilo, K. Jelena, P. Miroslav, and K. Vlado, “Instructions energy consumption on a heterogeneous multicore platform,” Proceedings of the Fifth European Conference on the Engineering of Computer-Based Systems ECBS’17, Article No.: 10, pages 1–10, August 2017. https://doi.org/10.1145/3123779.3123795.
H. David Money, H. Sarah L, “Digital Design and Computer Architecture,” 2007 by Elsevier.
H. David, C. Fallin & E. Gorbatov, U. Hanebutte and O. Mutlu, “Memory power management via dynamic voltage/frequency scaling,” Proceedings of the 8th ACM International Conference on Autonomic Computing, ICAC 2011 and Co-located Workshops, pages 31-40, 2011. https://doi.org/10.1145/1998582.1998590.
B. Nik-Mohammad, M. Arjmandi, K. Raahemifar, M. Fathy, A. Akbari, “Reduction of Power Consumption in Cloud Data Centers via Dynamic Migration of Virtual Machines,” International Journal of Information and Education Technology, Vol. 6. pages 286-290. 2016. https://doi.org/10.7763/IJIET.2016.V6.701.
M. Bharathwaj, S. Dharun, B. Akilesh, Mrs. M. Hema, “Reduction of Power Consumption Using Virtual Machine Consolidation in Cloud,” International Journal of Scientific Research and Review, Volume 7, Issue 3, 2018, pages 246-249. https://doi.org/10.1007/s11771-017-3645-z.
Zhou, Z., Hu, Zg., Yu, Jy. et al. “Energy-efficient virtual machine consolidation algorithm in cloud data centers,” J. Cent. South Univ. 24, pages 2331–2341, 2017. https://doi.org/10.1007/s11771-017-3645-z.
V.A Korthikanti and G.Agha, “Energy-Performance Trade-off Analysis of Parallel Algorithms,” Sustainable Computing: Informatics and Systems, Volume 1, Issue 3, pp. 167-176, September 2011. https://doi.org/10.1016/j.suscom.2011.05.004.
J. Thiyagalingam, “Alternative array storage layouts for regular scientific programs,” PhD Thesis, 2005, https://www.doc.ic.ac.uk/~phjk/PhDThesesLocalCopies/JeyanPhD.pdf.
Intel Corporation. "Intel® Architecture Instruction Set Extensions and Future Features," [Online].Available:https://software.intel.com/content/dam/develop/external/us/en/documents-tps/architecture-instruction-set-extensions-programming-reference.pdf
Intel Corporation. "Intel® Power Gadget," [Online]. Available: https://software.intel.com/content/www/us/en/develop/articles/intel-power-gadget.html.
A. J. Kawu, A. Yahaya Umar and S. I. Bala, "Performance of one-level recursion parallel Strassen’s algorithm on dual core processor," 2017 IEEE 3rd International Conference on Electro-Technology for National Development (NIGERCON), Owerri, pp. 587-591, 2017. https://doi.org/10.1109/NIGERCON.2017.8281929.
Barbara M. Chapman, Gabriele Jost, Ruud van der Pas, “Using OpenMP: Portable Shared Memory Parallel Programming,” pp. 57, United States of America, MIT Press, 2008.
S.Maleki, Y.Gao, M.J.Garzar´n, T.Wong and D.A. Padua, "An Evaluation of Vectorizing Compilers," 2011 International Conference on Parallel Architectures and Compilation Techniques, Galveston, TX, 2011, pp.372-382, https://doi.org/10.1109/PACT.2011.68.
N. Z. Oo and P. Chaikan, "The Effect of Loop Unrolling in Energy Efficient Strassen's Algorithm on Shared Memory Architecture," 2021 36th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), 2021, pages 1-4, doi: 10.1109/ITC-CSCC52171.2021.9501472.
N. Z. Oo and P. Chaikan, "An effective implementation of Strassen's algorithm using AVX intrinsics for a multicore architecture" Songklanakarin Journal of Science and Technology, 2020, Vol. 42 Issue 6, p1368-1376.
Eigen [Online]. https://eigen.tuxfamily.org/Eigenindex.php?title=Main_Page
OpenBLAS [Online]. https://osdn.net/projects/sfnet_openblas/downloads/v0.3.13/OpenBLAS%200.3.13%20version.tar.gz/
Intel Corporation. "Intel® VTune™ Profiler Performance Analysis Cookbook," [Online]. Available:https://www.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top.html.
