
The Challenges and Approaches during the Detection of Cyberbullying Text for Low-resource Language: A Literature Review
Article Sidebar
Main Article Content
Abstract
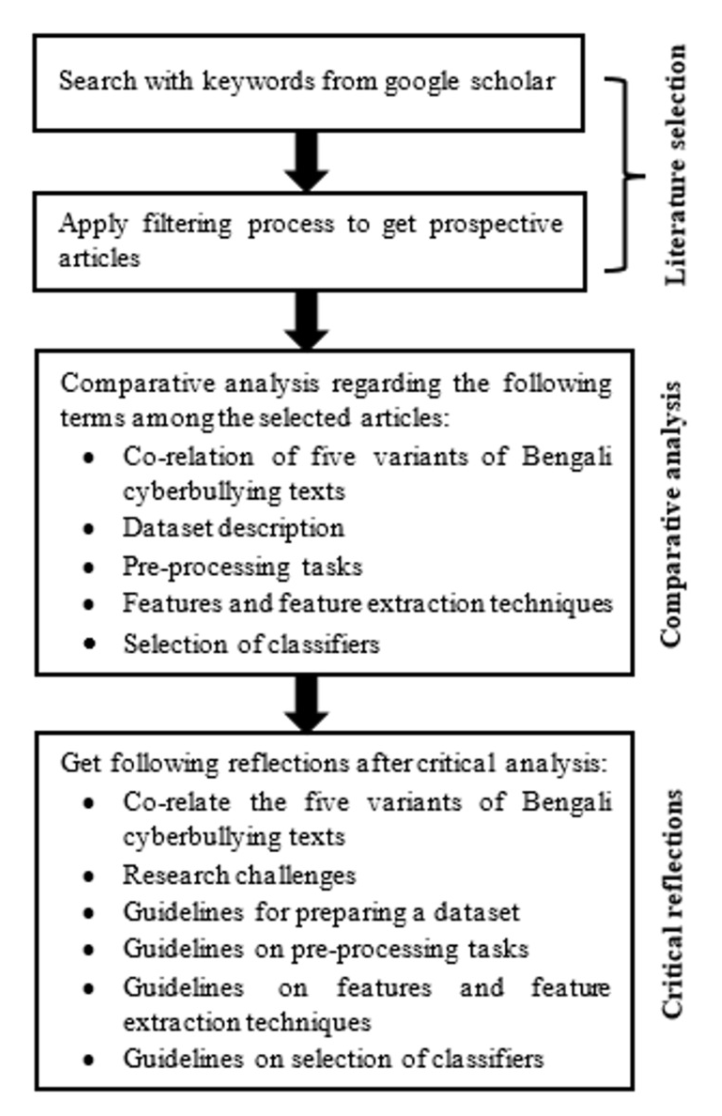
Objective: The primary intent of this paper is to review related studies that are more corresponding to the detection offive variants of cyberbullying text, such as abusive, hateful, aggressive, bully, and toxic comment or texts of Bengali language as a sample of low-resource language, to gain a comprehensive understanding of the challenges and state-of-the-art approaches used to identify these types of text.
Materials: We have searched the associated articles on cyberbullying text detection in the Bengali language published from 2017 to July 2021 since there was no research being detected before the year 2017 on this domain-specific paradigm. After that, we scrutinize the different levels of aspects by inspecting the title, abstract, and entire text to enlist the subsequent research in this review study.
Results: After applying different levels of filtering, from the initial search results, 28 domain-centric papers are considered out of 2,745 documents. At first, we deeply analyze the context of each study and then narrate a clear comparative review in case of research challenges and approaches, as well as providing the direction for the future work on the road to the detection of cyberbullying text for the Bengali language.
Conclusion: In this paper, we discuss five variants of cyberbullying text, such as abusive text, hateful speech, aggressive text, bully text, and toxic comments over the web, and their detection process by studying existing literature in this domain. We present advice on dataset preparation, pre-process and feature extraction tasks, and classifier selection that may aid in comprehensive research for better detection.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
M. Jahan, I. Ahamed, M. R. Bishwas, and S. Shatabda, “Abusive comments detection in bangla-english code-mixed and transliterated text,” in 2019 2nd International Conference on Innovation in Engineering and Technology (ICIET). IEEE, 2019, pp. 1–6.
C. L. Nixon, “Current perspectives: the impact of cyberbullying on adolescent health,” Adolescent health, medicine and therapeutics, vol. 5, p. 143, 2014.
S. Hinduja and J. W. Patchin, “Bullying, cyberbullying, and suicide,” Archives of suicide research, vol. 14, no. 3, pp. 206– 221, 2010.
J. Culpeper, Impoliteness: Using language to cause offence. Cambridge University Press, 2011, vol. 28.
N. Banik and M. H. H. Rahman, “Toxicity detection on Bengali social media comments using supervised models,” in 2019 2nd International Conference on Innovation in Engineering and Technology (ICIET). IEEE, 2019, pp. 1– 5.
L. Dhanya and K. Balakrishnan, “Hate speech detection in asian languages: A survey,” in 2021 International Conference on Communication, Control and Information Sciences (ICCISc), vol. 1. IEEE, 2021, pp. 1–5.
P. Tulkarm, “Approaches to cyberbullying detection on social networks: A survey,” Journal of Theoretical and Applied Information Technology, vol. 99, no. 13, 2021.
E. W. Pamungkas, V. Basile, and V. Patti, “Towards multidomain and multilingual abusive language detection: a survey,” Personal and Ubiquitous Computing, pp. 1–27, 2021.
P. Fortuna and S. Nunes, “A survey on automatic detection of hate speech in text,” ACM Comput. Surv., vol. 51, no. 4, jul 2018. [Online]. Available: https://doi.org/10.1145/3232676
A. Balayn, J. Yang, Z. Szlavik, and A. Bozzon, “Automatic identification of harmful, aggressive, abusive, and offensive language on the web: A survey of technical biases informed by psychology literature,” Trans. Soc. Comput., vol. 4, no. 3, oct 2021. [Online]. Available: https://doi.org/10.1145/3479158
M. T. Ahmed, M. Rahman, S. Nur, A. Islam, and D. Das, “Deployment of machine learning and deep learning algorithms in detecting cyberbullying in bangla and romanized bangla text: A comparative study,” in 2021 International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT). IEEE, 2021, pp. 1–10.
S. Sazzed, “Abusive content detection in transliterated bengali-english social media corpus,” in Proceedings of the Fifth Workshop on Computational Approaches to Linguistic Code-Switching, 2021, pp. 125–130.
T. Ranasinghe and M. Zampieri, “Multilingual offensive language identification for low-resource languages,” arXiv preprint arXiv:2105.05996, 2021.
A. K. Das, A. Al Asif, A. Paul, and M. N. Hossain, “Bangla hate speech detection on social media using attention-based recurrent neural network,” Journal of Intelligent Systems, vol. 30, no. 1, pp. 578–591, 2021.
N. Romim, M. Ahmed, H. Talukder, and M. S. Islam, “Hate speech detection in the bengali language: A dataset and its baseline evaluation,” in Proceedings of International Joint Conference on Advances in Computational Intelligence. Springer, 2021, pp. 457–468.
T. Islam, N. Ahmed, and S. Latif, “An evolutionary approach to comparative analysis of detecting bangla abusive text,” Bulletin of Electrical Engineering and Informatics, vol. 10, no. 4, pp. 2163–2169, 2021.
R. Kumar, B. Lahiri, and A. K. Ojha, “Aggressive and offensive language identification in hindi, bangla, and english: A comparative study,” SN Computer Science, vol. 2, no. 1, pp. 1–20, 2021.
M. R. Karim, B. R. Chakravarthi, J. P. McCrae, and M. Cochez, “Classification benchmarks for under-resourced bengali language based on multichannel convolutional-lstm network,” in 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA). IEEE, 2020, pp. 390–399.
J. Risch and R. Krestel, “Bagging bert models for robust aggression identification,” in Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, 2020, pp. 55– 61.
K. Kumari and J. P. Singh, “Ai_ml_nit_patna@ trac-2: Deep learning approach for multi-lingual aggression identification,” in Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, 2020, pp. 113–119.
A. Baruah, K. Das, F. Barbhuiya, and K. Dey, “Aggression identification in english, hindi and bangla text using bert, roberta and svm,” in Proceedings of the second workshop on trolling, aggression and cyberbullying, 2020, pp. 76–82.
S. Mishra, S. Prasad, and S. Mishra, “Multilingual joint finetuning of transformer models for identifying trolling, aggression and cyberbullying at trac 2020,” in Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, 2020, pp. 120–125.
D. Gordeev and O. Lykova, “Bert of all trades, master of some,” in Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, 2020, pp. 93–98.
A. Koufakou, V. Basile, and V. Patti, “Florunito@ trac-2: Retrofitting word embeddings on an abusive lexicon for aggressive language detection,” in Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, 2020, pp. 106–112.
N. S. Samghabadi, P. Patwa, P. Srinivas, P. Mukherjee, A. Das, and T. Solorio, “Aggression and misogyny detection using bert: A multi-task approach,” in Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, 2020, pp. 126–131.
A. Datta, S. Si, U. Chakraborty, and S. K. Naskar, “Spyder: Aggression detection on multilingual tweets,” in Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, 2020, pp. 87–92.
T. Ranasinghe and M. Zampieri, “Multilingual offensive language identification with cross-lingual embeddings,” arXiv preprint arXiv:2010.05324, 2020.
P. Chakraborty and M. H. Seddiqui, “Threat and abusive language detection on social media in bengali language,” in 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT). IEEE, 2019, pp. 1–6.
A. M. Ishmam and S. Sharmin, “Hateful speech detection in public facebook pages for the bengali language,” in 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA). IEEE, 2019, pp. 555–560.
E. A. Emon, S. Rahman, J. Banarjee, A. K. Das, and T. Mittra, “A deep learning approach to detect abusive bengali text,” in 2019 7th International Conference on Smart Computing & Communications (ICSCC). IEEE, 2019, pp. 1–5.
S. Ahammed, M. Rahman, M. H. Niloy, and S. M. H. Chowdhury, “Implementation of machine learning to detect hate speech in bangla language,” in 2019 8th International Conference System Modeling and Advancement in Research Trends (SMART). IEEE, 2019, pp. 317–320.
A. Jubaer, A. Sayem, and M. A. Rahman, “Bangla toxic comment classification (machine learning and deep learning approach),” in 2019 8th international conference system modeling and advancement in research trends (SMART). IEEE, 2019, pp. 62–66.
M. G. Hussain, T. Al Mahmud, and W. Akthar, “An approach to detect abusive bangla text,” in 2018 International Conference on Innovation in Engineering and Technology (ICIET). IEEE, 2018, pp. 1–5.
M. A. Awal, M. S. Rahman, and J. Rabbi, “Detecting abusive comments in discussion threads using naïve bayes,” in 2018 International Conference on Innovations in Science, Engineering and Technology (ICISET). IEEE, 2018, pp. 163–167.
S. Akhter et al., “Social media bullying detection using machine learning on bangla text,” in 2018 10th International Conference on Electrical and Computer Engineering (ICECE). IEEE, 2018, pp. 385–388.
S. C. Eshan and M. S. Hasan, “An application of machine learning to detect abusive bengali text,” in 2017 20th International Conference of Computer and Information Technology (ICCIT). IEEE, 2017, pp. 1–6.
S. Bhattacharya, S. Singh, R. Kumar, A. Bansal, A. Bhagat, Y. Dawer, B. Lahiri, and A. K. Ojha, “Developing a multilingual annotated corpus of misogyny and aggression,” arXiv preprint arXiv:2003.07428, 2020.
R. Kumar, A. N. Reganti, A. Bhatia, and T. Maheshwari, “Aggression-annotated corpus of hindi-english code-mixed data,” arXiv preprint arXiv:1803.09402, 2018.
N. Ashraf, A. Zubiaga, and A. Gelbukh, “Abusive language detection in youtube comments leveraging replies as conversational context,” PeerJ Computer Science, vol. 7, p. e742, 2021.
M. P. Akhter, Z. Jiangbin, I. R. Naqvi, M. AbdelMajeed, and T. Zia, “Abusive language detection from social media comments using conventional machine learning and deep learning approaches,” Multimedia Systems, pp. 1–16, 2021.
Z. Waseem, T. Davidson, D. Warmsley, and I. Weber, “Understanding abuse: A typology of abusive language detection subtasks,” arXiv preprint arXiv:1705.09899, 2017.
T. Mandl, S. Modha, P. Majumder, D. Patel, M. Dave, C. Mandlia, and A. Patel, “Overview of the hasoc track at fire 2019: Hate speech and offensive content identification in indo-european languages,” in Proceedings of the 11th forum for information retrieval evaluation, 2019, pp. 14–17.
R. Nayak and R. Joshi, “Contextual hate speech detection in code mixed text using transformer based
approaches,” arXiv preprint arXiv:2110.09338, 2021.
A. Rodriguez, C. Argueta, and Y.-L. Chen, “Automatic detection of hate speech on facebook using sentiment and emotion analysis,” in 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). IEEE, 2019, pp. 169–174.
R. Kumar, A. K. Ojha, S. Malmasi, and M. Zampieri, “Evaluating aggression identification in social media,” in Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, 2020, pp. 1–5.
K. Lorenz, M. Latzke, and E. Salzen, On aggression. Routledge, 2021.
K. Kumari, J. P. Singh, Y. K. Dwivedi, and N. P. Rana, “Bilingual cyber-aggression detection on social media using lstm autoencoder,” Soft Computing, pp. 1–14, 2021.
A. Shrivastava, R. Pupale, and P. Singh, “Enhancing aggression detection using gpt-2 based data balancing technique,” in 2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS). IEEE, 2021, pp. 1345–1350.
F. S. Ansari, M. Barhamgi, A. Khelifi, and D. Benslimane, “An approach to detect cyberbullying on social media,” in International Conference on Model and Data Engineering. Springer, 2021, pp. 53–66.
S. Bharti, A. K. Yadav, M. Kumar, and D. Yadav, “Cyberbullying detection from tweets using deep learning,” Kybernetes, 2021.
S. Thanigaivel, S. Harshan, M. Syed Shahul Hameed, and K. Umadevi, “Detection and prevention of cyberbullying using ensemble classifier,” in International Virtual Conference on Industry 4.0. Springer, 2021, pp. 323–333.
A. Bozyiğit, S. Utku, and E. Nasibov, “Cyberbullying detection: Utilizing social media features,” Expert Systems with Applications, vol. 179, p. 115001, 2021.
N. Lu, G. Wu, Z. Zhang, Y. Zheng, Y. Ren, and K.-K. R. Choo, “Cyberbullying detection in social media text based on character-level convolutional neural network with shortcuts,” Concurrency and Computation: Practice and Experience, vol. 32, no. 23, p. e5627, 2020.
P. Fortuna, J. Soler, and L. Wanner, “Toxic, hateful, offensive or abusive? what are we really classifying? an empirical analysis of hate speech datasets,” in Proceedings of the 12th language resources and evaluation conference, 2020, pp. 6786– 6794.
R. Beniwal and A. Maurya, “Toxic comment classification using hybrid deep learning model,” in Sustainable Communication Networks and Application. Springer, 2021, pp. 461– 473.
A. G. d’Sa, I. Illina, and D. Fohr, “Bert and fasttext embeddings for automatic detection of toxic speech,” in 2020 International Multi-Conference on:“Organization of Knowledge and Advanced Technologies”(OCTA). IEEE, 2020, pp. 1–5.
B. Van Aken, J. Risch, R. Krestel, and A. Löser, “Challenges for toxic comment classification: An in-depth error analysis,” arXiv preprint arXiv:1809.07572, 2018.
Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin, “A neural probabilistic language model,” Journal of machine learning research, vol. 3, no. Feb, pp. 1137–1155, 2003.
R. Collobert and J. Weston, “A unified architecture for natural language processing: Deep neural networks with multitask learning,” in Proceedings of the 25th international conference on Machine learning, 2008, pp. 160–167.
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013.
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems, 2013, pp. 3111–3119.
T. Mikolov, W.-t. Yih, and G. Zweig, “Linguistic regularities in continuous space word representations,” in Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies, 2013, pp. 746–751.
Y. Goldberg and O. Levy, “word2vec explained: deriving mikolov et al.’s negative-sampling word-embedding method,” arXiv preprint arXiv:1402.3722, 2014.
K. W. Church, “Word2vec,” Natural Language Engineering, vol. 23, no. 1, pp. 155–162, 2017.
X. Rong, “word2vec parameter learning explained,” arXiv preprint arXiv:1411.2738, 2014.
J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543.
A. Joulin, E. Grave, P. Bojanowski, and T. Mikolov, “Bag of tricks for efficient text classification,” arXiv preprint arXiv:1607.01759, 2016.
E. Grave, P. Bojanowski, P. Gupta, A. Joulin, and T. Mikolov, “Learning word vectors for 157 languages,” arXiv preprint arXiv:1802.06893, 2018.
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
C. Cortes and V. Vapnik, “Support-vector networks,” Machine learning, vol. 20, no. 3, pp. 273–297, 1995.
M. A. Hearst, S. T. Dumais, E. Osuna, J. Platt, and B. Scholkopf, “Support vector machines,” IEEE Intelligent Systems and their applications, vol. 13, no. 4, pp. 18–28, 1998.
S.-i. Amari and S. Wu, “Improving support vector machine classifiers by modifying kernel functions,” Neural Networks, vol. 12, no. 6, pp. 783–789, 1999.
S. Tong and D. Koller, “Support vector machine active learning with applications to text classification,” Journal of machine learning research, vol. 2, no. Nov, pp. 45–66, 2001.
D. D. Lewis, “Naive (bayes) at forty: The independence assumption in information retrieval,” in European conference on machine learning. Springer, 1998, pp. 4–15. [75] A. McCallum, K. Nigam et al., “A comparison of event models for naive bayes text classification,” in AAAI-98 workshop on learning for text categorization, vol. 752, no. 1. Citeseer, 1998, pp. 41–48.
I. Rish et al., “An empirical study of the naive bayes classifier,” in IJCAI 2001 workshop on empirical methods in artificial intelligence, vol. 3, no. 22, 2001, pp. 41–46.
K. P. Murphy et al., “Naive bayes classifiers,” University of British Columbia, vol. 18, no. 60, pp. 1–8, 2006.
L. Breiman, “Random forests,” Machine learning, vol. 45, no. 1, pp. 5–32, 2001.
V. Svetnik, A. Liaw, C. Tong, J. C. Culberson, R. P. Sheridan, and B. P. Feuston, “Random forest: a classification and regression tool for compound classification and qsar modeling,” Journal of chemical information and computer sciences, vol. 43, no. 6, pp. 1947–1958, 2003.
A. Cutler, D. R. Cutler, and J. R. Stevens, “Random forests,” in Ensemble machine learning. Springer, 2012, pp. 157–175.
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
A. Graves, “Long short-term memory,” in Supervised sequence labelling with recurrent neural networks. Springer, 2012, pp. 37–45.
K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio, “Learning phrase representations using rnn encoder-decoder for statistical machine translation,” arXiv preprint arXiv:1406.1078, 2014.
S. Albawi, T. A. Mohammed, and S. Al-Zawi, “Understanding of a convolutional neural network,” in 2017 International Conference on Engineering and Technology (ICET). Ieee, 2017, pp. 1–6.
P. Kim, “Convolutional neural network,” in MATLAB deep learning. Springer, 2017, pp. 121–147.
N. Kalchbrenner, E. Grefenstette, and P. Blunsom, “A convolutional neural network for modelling sentences,” arXiv preprint arXiv:1404.2188, 2014.
Y. Huang, W. Wang, L. Wang, and T. Tan, “Multi-task deep neural network for multi-label learning,” in 2013 IEEE International conference on image processing. IEEE, 2013, pp. 2897–2900.
V. Ganganwar, “An overview of classification algorithms for imbalanced datasets,” International Journal of Emerging Technology and Advanced Engineering, vol. 2, no. 4, pp. 42–47, 2012.
A. Chanda, D. Das, and C. Mazumdar, “Unraveling the english-bengali code-mixing phenomenon,” in Proceedings of the Second Workshop on Computational Approaches to Code Switching, 2016, pp. 80–89.
U. Barman, A. Das, J. Wagner, and J. Foster, “Code mixing: A challenge for language identification in the language of social media,” in Proceedings of the first workshop on computational approaches to code switching, 2014, pp. 13–23.
K. Dinakar, R. Reichart, and H. Lieberman, “Modeling the detection of textual cyberbullying,” in fifth international AAAI conference on weblogs and social media, 2011.
M. J. Denny and A. Spirling, “Text preprocessing for unsupervised learning: Why it matters, when it misleads, and what to do about it,” Political Analysis, vol. 26, no. 2, pp. 168–189, 2018.
A. K. Uysal and S. Gunal, “The impact of preprocessing on text classification,” Information processing & management, vol. 50, no. 1, pp. 104–112, 2014.
S. Vijayarani, M. J. Ilamathi, M. Nithya et al., “Preprocessing techniques for text mining-an overview,” International Journal of Computer Science & Communication Networks, vol. 5, no. 1, pp. 7–16, 2015.
G. Guibon, M. Ochs, and P. Bellot, “From emojis to sentiment analysis,” in WACAI 2016, 2016.
M. Shiha and S. Ayvaz, “The effects of emoji in sentiment analysis,” Int. J. Comput. Electr. Eng.(IJCEE.), vol. 9, no. 1, pp. 360–369, 2017.
R. Sadia, M. A. Rahman, and M. H. Seddiqui, “N-gram statistical stemmer for bangla corpus,” CoRR, vol. abs/1912.11612, 2019. [Online]. Available: http://arxiv.org/abs/1912.11612
M. H. Seddiqui, A. A. M. Maruf, and A. N. Chy, “Recursive suffix stripping to augment bangla stemmer,” in International Conference Advanced Information and Communication Technology (ICAICT), 2016.
T. Mikolov, M. Karafiát, L. Burget, J. Cernockỳ, and S. Khudanpur, “Recurrent neural network based language model.” In Interspeech, vol. 2, no. 3. Makuhari, 2010, pp. 1045–1048.
S. Deerwester, S. T. Dumais, G. W. Furnas, T. K. Landauer, and R. Harshman, “Indexing by latent semantic analysis,” Journal of the American society for information science, vol. 41, no. 6, pp. 391–407, 1990.
A. Mnih and K. Kavukcuoglu, “Learning word embeddings efficiently with noise-contrastive estimation,” in Advances in neural information processing systems, 2013, pp. 2265–2273.
P. Bojanowski, E. Grave, A. Joulin, and T. Mikolov, “Enriching word vectors with subword information,” Transactions of the Association for Computational Linguistics, vol. 5, pp. 135– 146, 2017.
T. Mikolov, E. Grave, P. Bojanowski, C. Puhrsch, and A. Joulin, “Advances in pre-training distributed word representations,” arXiv preprint arXiv:1712.09405, 2017.
M. Rahman, M. Seddiqui et al., “Comparison of classical machine learning approaches on bangla textual emotion analysis,” arXiv preprint arXiv:1907.07826, 2019.
N. Banik, M. H. H. Rahman, S. Chakraborty, H. Seddiqui, and M. A. Azim, “Survey on text-based sentiment analysis of bengali language,” in 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT). IEEE, 2019, pp. 1–6.
S. Karamizadeh, S. M. Abdullah, M. Halimi, J. Shayan, and M. javad Rajabi, “Advantage and drawback of support vector machine functionality,” in 2014 international conference on computer, communications, and control technology (I4CT). IEEE, 2014, pp. 63–65.
J. Cervantes, X. Li, W. Yu, and K. Li, “Support vector machine classification for large data sets via minimum enclosing ball clustering,” Neurocomputing, vol. 71, no. 4-6, pp. 611–619, 2008.
C.-C. Chang and C.-J. Lin, “Libsvm: a library for support vector machines,” ACM transactions on intelligent systems and technology (TIST), vol. 2, no. 3, pp. 1–27, 2011.
B. McCann, J. Bradbury, C. Xiong, and R. Socher, “Learned in translation: Contextualized word vectors,” Advances in neural information processing systems, vol. 30, 2017.
M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” arXiv preprint arXiv:1802.05365, 2018.
J. Howard and S. Ruder, “Universal language model fine-tuning for text classification,” arXiv preprint arXiv:1801.06146, 2018.
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding with unsupervised learning,” 2018.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,” arXiv preprint arXiv:1910.01108, 2019.
A. Conneau, K. Khandelwal, N. Goyal, V. Chaudhary, G. Wenzek, F. Guzmán, E. Grave, M. Ott, L. Zettlemoyer, and V. Stoyanov, “Unsupervised cross-lingual representation learning at scale,” arXiv preprint arXiv:1911.02116, 2019.
