
Persons facial image synthesis from audio with Generative Adversarial Networks
Article Sidebar
Main Article Content
Abstract
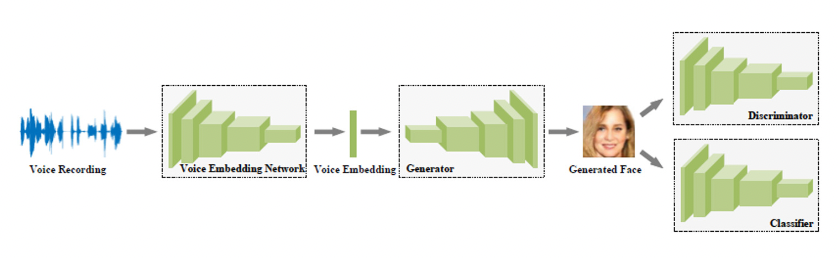
This paper proposes to build a framework with Generative Adversarial Network (GANs) to synthesize a person's facial image from audio input. Image and speech are the two main sources of information exchange between two entities. In some data intensive applications, a large amount of audio has to be translated into an understandable image format, with automated system, without human interference. This paper provides an end-to-end model for intelligible image reconstruction from an audio signal. The model uses a GAN architecture, which generates image features using audio waveforms for image synthesis. The model was created to produce facial images from audio of individual identities of a synthesized image of the speakers, based on the training dataset. The images of labelled persons are generated using excitation signals and the method obtained results with an accuracy of 96.88% for ungrouped data and 93.91% for grouped data.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
Tae-Hyun and Dekel, Tali and Kim, Changil and Mosseri, Inbar and Freeman, William T. and Rubinstein, Michael and Matusik, Wojciech, “Speech2Face: Learning the Face Behind a Voice,” In Proceedings of the IEEE conference on computer vision and pattern recognition, June 2019.
Tali Dekel, Changil Kim Inbar Mosseri, William T. Freeman Michael, “Speech2face: Learning the face behind a voice”, IEEE conference on computer vision and pattern recognition, 2019.
Pavaskar S., Budihal S., “Real-Time Vehicle Type Categorization and Character Extraction from the License Plates,” Cognitive Informatics and Soft Computing. Advances in Intelligent Systems and Computing, vol. 768, 2019.
Arsha Nagrani, Samuel Albanie, and Andrew Zisserman, “Seeing voices and hearing faces Cross-modal biometric matching, ” IEEE conference on computer vision and pattern recognition, pp. 8427-8436, 2018.
Arsha Nagrani, Samuel Albanie, and Andrew Zisserman, “Learnable pins: Cross-modal embeddings for person identity”, computer science bibliography, 2018.
Yongyi Lu, Yu-Wing Tai, and Chi-Keung Tang, “Conditional C-GAN for attribute guided face image generation”, 2017.
Mohamad Hasan Bahari, ML McLaren, DA Van Leeuwen, et al. “Age estimation from telephone speech using i-vectors”, 2012.
Yandong Wen, Mahmoud Al Ismail, Weiyang Liu, Bhiksha Raj, and Rita Singh, “Disjoint mapping network for cross-modal matching of voices and faces,” 2018.
Jianmin Bao, Dong Chen, Fang Wen, Houqiang Li, and Gang Hua, “Towards open-set identity preserving face synthesis,” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6713-6722, 2018.
Suneeta V. B., Purushottam P., Prashantkumar K., Sachin S., Supreet M., “Facial Expression Recognition Using Supervised Learning,” Computational Vision and Bio-Inspired Computing. ICCVBIC 2019. Advances in Intelligent Systems and Computing, vol. 1108, 2020.
Amir Jamaludin, Joon Son Chung, and Andrew Zisserman, “You said that?: Synthesising talking faces from audio:,” International Journal of Computer Vision, pages 01-13, 2019.
Rita Singh, “Reconstruction of the human persona in 3D and its reverse,” In Profiling Humans from their Voice, chapter 10. springer nature Press, 2020.
Rui Huang, Shu Zhang, Tianyu Li, and Ran He, “Beyond face rotation: Global and local perception GAN for photo realistic and identity preserving frontal view synthesis,” In Proceedings of the IEEE International Conference on Computer Vision, pp. 2439-2448, 2017.
Thies J., Elgharib M., Tewari A., Theobalt C., Niener M., “Neural Voice Puppetry: Audio Driven Facial Reenactment,” Computer Vision (ECCV), Lecture Notes in Computer Science, vol. 12361, 2020.
Zhang, Richard, Phillip Isola, and Alexei A. Efros, “Colourful image colorization” In European conference on computer vision, pp. 649-666, 2016.
Willcox, Stacey, “Artificial Synaesthesia: An exploration of machine learning image synthesis for soundscape audio visualisation,” 2020.
Hang Zhou, Yu Liu, Ziwei Liu, Ping Luo, and Xiaogang Wang, “Talking face generation by adversarially disentangled audio-visual representation,” 2018.
Yandong Wen, Rita Singh, and Bhiksha Raj, “Face Reconstruction from Voice using Generative Adversarial Networks,” 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), 2019.
Adrian Bulat and Georgios Tzimiropoulos, “How far are we from solving the 2D 3D face alignment problem and a dataset of 230,000 3D facial landmarks,” In International Conference on Computer Vision, 2017.
Arsha Nagrani, Samuel Albanie, and Andrew Zisserman, “Seeing voices and hearing faces: Cross-modal biometric matching,” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8427-8436, 2018.
