
Software Defect Prediction Based on Feature Subset Selection and Ensemble Classification
Article Sidebar
Main Article Content
Abstract
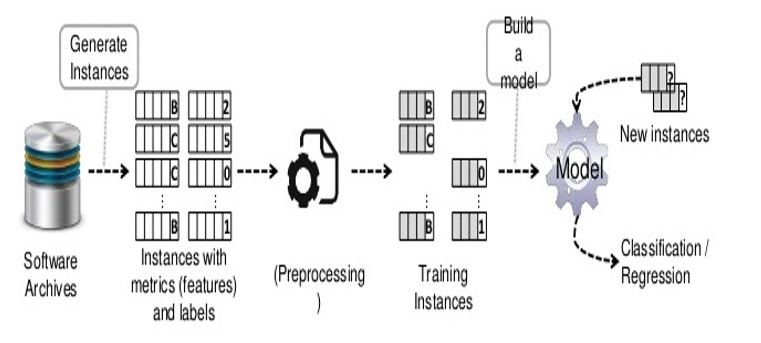
Two primary issues have emerged in the machine learning and data mining community: how to deal with imbalanced data and how to choose appropriate features. These are of particular concern in the software engineering domain, and more specifically the field of software defect prediction. This research highlights a procedure which includes a feature selection technique to single out relevant attributes, and an ensemble technique to handle the class-imbalance issue. In order to determine the advantages of feature selection and ensemble methods we look at two potential scenarios: (1) Ensemble models constructed from the original datasets, without feature selection; (2) Ensemble models constructed from the reduced datasets after feature selection has been applied. Four feature selection techniques are employed: Principal Component Analysis (PCA), Pearson’s correlation, Greedy Stepwise Forward selection, and Information Gain (IG). The aim of this research is to assess the effectiveness of feature selection techniques using ensemble techniques. Five datasets, obtained from the PROMISE software depository, are analyzed; tentative results indicate that ensemble methods can improve the model's performance without the use of feature selection techniques. PCA feature selection and bagging based on K-NN perform better than both bagging based on SVM and boosting based on K-NN and SVM, and feature selection techniques including Pearson’s correlation, Greedy stepwise, and IG weaken the ensemble models’ performance.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
R. Chang, X. Mu., and L. Zhang, “Software defect prediction using non-negative matrix factorization”, Journal of Software, 6(11):2114–2120, 2011.
N. Fenton, and J. Bieman, “Software metrics: a rigorous and practical approach”. Third Edition (3rd. ed.). CRC Press, Inc., USA., 2014
S. Agarwal, and D. Tomar, “A feature selection based model for software defect prediction”, International Journal of Advanced Science and Technology Vol.65 (2014), pp.39-58.
S. Liu, X. Chen, W. Liu, J. Chen, Q. Gu, and D. Chen, “Fecar: A feature selection framework for software defect prediction”. In Computer Software and Applications Conference (COMPSAC), 2014 IEEE 38th Annual, pages 426–435. IEEE.
K. Gao, T.M Khoshgoftaar, H. Wang, and N. Seliya, “Choosing software
metrics for defect prediction: an investigation on feature selection techniques”. Software: Practice and Experience, 41(5):579–606, 2011.
S. Lessmann, B. Baesens, C. Mues, and S. Pietsch, S, “Benchmarking classification models for software defect prediction: A proposed framework and novel findings”, IEEE Transactions on Software Engineering, 34(4):485–496, 2008
M. Jureczko, and L. Madeyski, “Towards identifying software project clusters with regard to defect prediction”, In Proceedings of the 6th International Conference on Predictive Models in Software Engineering, page 9. ACM, 2010
G. Czibula, Z. Marian, and I. G. Czibula, “Software defect prediction using relational association rule mining”, Information Sciences, 264:260–278, 2014.
K. O. Elish, and M. O. Elish, “Predicting defect-prone software modules using support vector machines”, Journal of Systems and Software, 81(5):649–660, 20087.
A. Okutan, A. and O. T. Yıldız, “Software defect prediction using bayesian networks”, Empirical Software Engineering, 19(1):154–181, 2014.
P. Knab, M. Pinzger, and A. Bernstein, “Predicting defect densities in source code files with decision tree learners”, In Proceedings of the 2006 international workshop on Mining software repositories, pages 119–125. ACM, 2006.
T. Menzies, J. Greenwald, and A. Frank, “Data mining static code attributes to learn defect predictors”, IEEE
transactions on software engineering, 33(1), 2007.
Q. Song, Z. Jia, M. Shepperd, S. Ying, and J. Liu, “A general software defect-proneness prediction framework”, IEEE Transactions on Software Engineering, 37(3):356–370, 2011.
B. Ghotra, S. McIntosh, and A. E. Hassan, “Revisiting the impact of classification techniques on the performance of defect prediction models”, In Proceedings of the 37th International Conference on Software Engineering-Volume 1, pages 789–800. IEEE Press, 2015.
K. Punitha, and B. Latha, “Sampling imbalance dataset for software defect prediction using hybrid neuro-fuzzy systems with naive bayes classifier”, Tehnicki vjesnik/Technical Gazette, 23(6), 2016.
M. C. Prasad, L. Florence, and A. Arya, “A study on software metrics based software defect prediction using data mining and machine learning techniques”, International Journal of Database Theory and Application, 8(3):179–190, 2015.
J. Petric´, D. Bowes, T. Hall, B. Christianson, and N. Baddoo, “Building an ensemble for software defect prediction based on diversity selection”, In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, page 46. ACM, 2016.
S. Wang, and X. Yao, “Using class imbalance learning for software defect prediction”, IEEE Transactions on Reliability, 62(2):434–443, 2013.
A. A. Saifan, and N. Alsmadi, “Source Code-Based Defect Prediction Using Deep Learning and Transfer Learning”, Journal of Intelligent Data Analysis, 23(6), 2019.
R. Ozakinci, and A. Tarhan, “The role of process in early software defect prediction: Methods, attributes and metrics”, In International Conference on Software Process Improvement and Capability Determination, pages 287–300. Springer, 2016.
H. Wang, T. M. Khoshgoftaar, and A. Napolitano, “Software measurement data reduction using ensemble techniques”, Neurocomputing, 92:124–132, 2012.
A. A. Saifan, H. Alsghaier, K. Alkhateeb, “Evaluating the Understandability of Android Applications”, International Journal of Software Innovation (IJSI) 6 (1), 44-57, 2017.
A. A. Saifan, A. Alrabadi, “Evaluating Maintainability of Android Applications”, The 8th International Conference on Information Technology ICIT 2017. Amman, Jordan, 2017.
F. Hanandeh, A. A. Saifan, M. Akour, N. Al-Hussein, K. Shatnawi, “Evaluating Maintainability of Open Source Software: A Case Study”, International journal of open source software and processes. Volume 8 issue 1, 2017.
J. Nam, “Survey on software defect prediction”, Department of Computer Science and Engineering, The Hong Kong University of Science and Technology, Tech. Rep, 2014.
G. Forman, “An extensive empirical study of feature selection metrics for text classification”, Journal of machine learning research, 3(Mar):1289–1305, 2003.
P. Gupta, and T. Dallas, “Feature selection and activity recognition system using a single triaxial accelerometer”, IEEE Transactions on Biomedical Engineering, 61(6):1780–1786, 2014.
Q. A. Al-Radaideh, E. M. Al-Shawakfa, and M. I. Al-Najjar, “Mining student data using decision trees”, In International Arab Conference on Information Technology (ACIT’2006), Yarmouk University,2006.
G. Chandrashekar, and F. Sahin, “A survey on feature selection methods”, Computers & Electrical Engineering, 40(1):16–28, 2014.
L. C. Molina, L. Belanche, and A. Nebot, “Feature selection algorithms: A survey and experimental evaluation”, In Data Mining, 2002. ICDM 2003. Proceedings. 2002 IEEE International Conference on, pages 306–313. IEEE.
M. Galar, A. Fernandez, E. Barrenechea, H. Bustince, and F. Herrera, “A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches”, IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(4):463–484, 2012.
H. I. Elshazly, A. M. Elkorany, A. E. Hassanien, and A. T. Azar, “Ensemble classifiers for biomedical data: performance evaluation”, In Computer Engineering & Systems (ICCES), 2013 8th International Conference on, pages 184–189. IEEE, 2013.
S. Kotsiantis, K. Patriarcheas, and M. Xenos, “A combinational incremental ensemble of classifiers as a technique for predicting students performance in distance education”, Knowledge- Based Systems, 23(6):529–535, 2010
M. Scholz, and R. Klinkenberg, “An ensemble classifier for drifting concepts”, In Proceedings of the Second International Workshop on Knowledge Discovery in Data Streams, pages 53–64. Porto, Portugal, 2005.
M. Woz´niak, M. Gran˜a, and E. Corchado, “A survey of multiple classifier systems as hybrid systems”, Information Fusion, 16:3–17, 2014.
T. M. Khoshgoftaar, K. Gao, and N. Seliya, “Attribute selection and imbalanced data: Problems in software defect prediction”, In Tools with Artificial Intelligence (ICTAI), 2010 22nd IEEE International Conference on, volume 1, pages 137–144. IEEE, 2010.
T. M. Khoshgoftaar, K. Gao, and A. Napolitano, “An empirical study of feature ranking techniques for software quality prediction”, International Journal of Software Engineering and Knowledge Engineering, 22(02):161–183, 2012.
J. Murillo-Morera, C. Castro-Herrera, J. Arroyo, and R. Fuentes-Ferna´ndez, “An automated defect prediction framework using genetic algorithms: A validation of empirical studies”, Inteligencia Artificial, 19(57):114–137, 2016.
R. Vivanco, Y. Kamei, A. Monden, K. Matsumoto, and D. Jin, “Using search-based metric selection and oversampling to predict fault prone modules”, In Electrical and Computer Engineering (CCECE), 2010 23rd Canadian Conference on, pages 1–6. IEEE.
L. Jia, “A hybrid feature selection method for software defect prediction”, IOP Conf. Ser. Mater. Sci. Eng. 394(3), 032035 (2018).
I. Arora, and A. Saha, “Software Defect Prediction Using ELM and KELM Based Feature Selection Models”, Proceedings of International Conference on Sustainable Computing in Science, Technology and Management (SUSCOM), Amity University Rajasthan, Jaipur - India, February 26-28, 2019.
W. Tao, L. Weihua, S. Haobin, and L. Zun, “Software defect prediction based on classifiers ensemble”, JOURNAL OF INFORMATION &COMPUTATIONAL SCIENCE, 8(16):4241– 4254, 2011.
V. Jayaraj, and N.S. Raman, “Software defect prediction using boosting techniques”, International Journal of Computer Applications, 65(13), 2013.
R. S. Wahono, and N.S. Herman, “Genetic feature selection for software defect prediction”, Advanced Science Letters, 20(1):239–244, 2014.
I. H. Laradji, M. Alshayeb, and L. Ghouti, “Software defect prediction using ensemble learning on selected features”, Information and Software Technology, 58:388–402, 2015.
A. Abdou and N. Darwish, “Early Prediction of Software Defect using Ensemble Learning: A Comparative Study”, International Journal of Computer Applications 179(46):29-40, June 2018.
A. Alsaeedi, and M. K Khan, “Software Defect Prediction Using Supervised Machine Learning and Ensemble Techniques: A Comparative Study”, Journal of Software Engineering and Applications, 12, 85- 100.https://doi.org/10.4236/jsea, 2019.
J. S. Shirabad, and T.J. Menzies, “The promise repository of software engineering databases”, School of Information Technology and Engineering, University of Ottawa, Canada, 24, 2005.
I. H. Witten, E. Frank, M .A. Hall, and C. J. Pal, “Data Mining: Practical machine learning tools and techniques”, Fourth Edition, Morgan Kaufmann, (Fourth Edition), 2017.
A. W. Moore, “Support vector machines”, Tutorial. School of Computer Science of the Carnegie Mellon University, 2001, Available at http://www.cs.cmu.edu/˜awm/tutorials. [Accessed August 16, 2009].
J. A. Suykens, and J. Vandewalle, “Least squares support vector machine classifiers”, Neural processing letters, 9(3):293–300, 1999.
G. H. John, and P. Langley, “Estimating continuous distributions in bayesian classifiers”, In Proceedings of the Eleventh conference on Uncertainty in artificial intelligence, pages 338–345. Morgan Kaufmann Publishers Inc, 1995.
L. Breiman, “Bagging predictors”, Machine learning, 24(2):123–140, 1996.
Y. Freund, R. E. Schapire, et al., “Experiments with a new boosting algorithm”, In icml, volume 96, pages 148–156, 1996.
J. Han, J. Pei, and M. Kamber, “Data mining: concepts and techniques”, Third Edition, Elsevier, 2012
U. Waikato, “Weka tool”, http://www.cs.waikato.ac.nz/ml/weka/index.html, accessed June 22, 2020
M. J. Norusˇis, “IBM SPSS statistics 19 statistical procedures companion”, Prentice Hall, 2012.
T. M. Khoshgoftaar, M. Golawala, and J. Van Hulse, “An empirical study of learning from imbalanced data using random forest”, In Tools with Artificial Intelligence, 2007. ICTAI 2007. 19th IEEE International Conference on, volume 2, pages 310–317. IEEE.
N. García-Pedrajas, and D. Ortiz-Boyer, “Boosting k-nearest neighbor classifier by means of input space projection”, Expert Systems with Applications, 36(7), 10570–10582, 2009.
Z. Xu, J. Liu, Z. Yang, G. An, X. Jia, “The Impact of Feature Selection on Defect Prediction Performance: An Empirical Comparison”, In Proceedings of the 2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE), Ottawa, ON, Canada, 23–27 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 309–320.
M. Kondo, C.-P. Bezemer, Y. Kamei, A. E. Hassan, O. Mizuno, “The impact of feature reduction techniques on defect prediction models”,Empir. Softw. Eng., 1–39, 2019.
K. Muthukumaran, A. Rallapalli, N. Murthy, “Impact of feature selection techniques on bug prediction models”, In Proceedings of the 8th India Software Engineering Conference, Bangalore, India, 18–20 February 2015; ACM: New York, NY, USA, 2015; pp. 120–129, 2015.
A. Field, “Discovering statistics using IBM SPSS statistics”, Fourth Edition, Sage, 2013.
