
The Local Power Set in Transaction Scanning for Efficient Frequent Item sets Mining
Article Sidebar
Main Article Content
Abstract
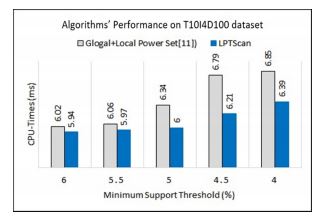
Discovering frequent item sets has been known among researchers as the most computationally expensive task in association rules mining. As a result of a technique used in the traditional algorithm, Apriori, generating new candidate (k+1)-item sets by performing self-join operation over elements of the frequent (k)-item sets which needs to scan dataset multiple times. Although, many modern algorithms have been proposed to the problems, most of them encounter with wasting the times to manipulate other data structures in memory. In this paper, we propose an algorithm utilizing concept of local power set enumeration and hash table. The proposed is not only able to escape self-join operation but also able to reduce CPU-times in computation when compared to the related algorithm that also applied concept of power set. To get better performance, we also modify the algorithm to two new versions applying an intersection-set operation in the phase of removing useless item sets from the dataset, instead of checking item elements of transactions one by one. Many experiments are conducted to evaluate performance of all our proposed. The results expressed that all modified versions of the algorithms provide better performance in term of reducing computational CPU-time and take less amount of scanning.
Article Details
References
A Rajak, MK Gupta, Association Rule Mining: Applications in Various Areas. Proceedings of International Conference on Data Management, 2008.
G. Serban, I. G. Czibula, and A. Campan, "A Programming Interface For Medical diagnosis Prediction", Studia Universitatis, "Babes-Bolyai", Informatica, LI(1), pp. 21- 30, 2006.
D. Gamberger, N. Lavrac, and V. Jovanoski, High confidence association rules for medical diagnosis, In Proceedings of IDAMAP99, pp. 42-51,1999.
N. Gupta, N. Mangal, K. Tiwari and P. Mitra, Mining Quantitative Association Rules in Protein Sequences, In Proceedings of Australasian Conference on Knowledge Discovery and Data Mining – AUSDM, 2006
D. Malerba, F. Esposito and F.A. Lisi, Mining spatial association rules in census data, In Proceedings of Joint Conf. on "New Techniques and Technologies for Statistcs and Exchange of Technology and Know-how”, 2001.
G. Saporta, Data mining and official statistics, In Proceedings of Quinta Conferenza Nationale di Statistica, ISTAT, Roma, 15 Nov. 2000.
R. S. Chen, R. C. Wu and J. Y. Chen, Data Mining Application in Customer Relationship Management Of Credit Card Business, In Proceedings of 29th Annual International Computer Software and Applications Conference (COMPSAC'05), Volume 2, pp. 39-40,2005.
H. S. Song, J. K. Kim and S. H. Kim, “Mining the change of customer behavior in an internet shopping mall,” Expert Systems with Applications, 2001.
R. Agrawal, T. Imielinski and A. Swami, “Mining Association Rules between Sets of Items in Large Databases,” ACM SIGMOD International Conference on Management of Data, pp.. 207-216, 1993.
R Agrawal, R Srikant, Fast Algorithm for Mining Association Rules, International Conference on Very large databases, Santiago, pp.. 487-499, 1994
S. Girja and B. Latita, “A New Improved Apriori Algorithm For Association rule mining,” International Journal of Engineering Research & Technology (IJERT), Vol. 2 (6), June 2013.
B. Liu, W. Hsu, Y. Ma, Mining association rules with multiple minimum supports Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD-99), San Diego, CA, USA (1999)
N. Pasquier, Y. Bastide, R. Taouil, and L. Lakhal, Discovering frequent closed itemsets for association rules. In Proc. 7th Int. Conf. Database Theory (ICDT'99), Jerusalem, Israel, pp.. 398–416, 1999.
A. Savasere, E. Omiecinski and S. Navathe, An Efficient Algorithm for Mining Association Rules in Large Database, International Conference on Very Large Data Bases. Zurich, Switzerland, pp.. 432-443, 1995.
J. Han, J. Pei, and Y. Yin, “Mining frequent patterns without candidate generation,” ACM SIGMOD International Conference on Management of Data, pp.1-12, 2000.
J. Pavón, S. Viana & S. Gómez, Matrix Apriori: Speeding up the Search for Frequent Patterns, In Proceedings of the 24th IASTED international Conference on Database and Applications, Innsbruck, Austria, pp.75-82, 2006.
Yıldız, B., Ergenç, B. Comparison of Two Association Rule Mining Algorithms without Candidate Generation, In the 10th IASTED International Conference on Artificial Intelligence and Appliations , Innsbruck, Austia, pp.450-457, 2010,.
L. Ming-Yen L, L. Pei-Yu and H. Sue-Chen, Apriori-based frequent item set mining algorithms on MapReduce, in CUIMC’12, Kuala Lumpur, Malaysia, February 20-22, 2012.
C. Hemant, Y. Deepak Kumar and et, al., MapReduce Based Frequent Item set Mining Algorithm on Stream Data, in Global Conference on Communication Technologies, pp. 598-603, 2015.
K. Varun, D. Rajanish, Kaal-a Real Time Stream Mining Algorithm, 43rd Hawaii International Conference on System Sciences – 2010.
S. Singh, R. Garg, and P. K Mishra, Review of Apriori Based Algorithms on MapReduce Framework. In Proceedings of International Conference on Communication and Computing (ICC - 2014), Elsevier Science and Technology Publications, 593–604, 2014.
