
Emotion Classification System for Digital Music with a Cascaded Technique
Article Sidebar
Main Article Content
Abstract
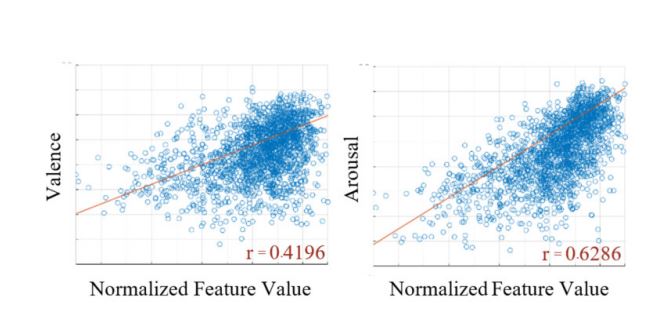
Music selection is difficult without efficient organization based on metadata or tags, and one effective tag scheme is based on the emotion expressed by the music. However, manual annotation is labor intensive and unstable because the perception of music emotion varies from person to person. This paper presents an emotion classification system for digital music with a resolution of eight emotional classes. Russell’s emotion model was adopted as common ground for emotional annotation. The music information retrieval (MIR) toolbox was employed to extract acoustic features from audio files. The classification system utilized a supervised machine learning technique to recognize acoustic features and create predictive models. Four predictive models were proposed and compared. The models were composed by crossmatching two types of neural networks, i.e., Levenberg-Marquardt (LM) and resilient backpropagation (Rprop), with two types of structures: a traditional multiclass model and the cascaded structure of a binary-class model. The performance of each model was evaluated via the MediaEval Database for Emotional Analysis (DEAM) benchmark. The best result was achieved by the model trained with the cascaded Rprop neural network (accuracy of 89.5%). In addition, correlation coefficient analysis showed that timbre features were the most impactful for prediction. Our work offers an opportunity for a competitive advantage in music classification because only a few music providers currently tag music with emotional terms.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
References
Y.-H. Yang and H. Chen, “01 Introduction,” in Music Emotion Recognition, CRC Press, 2011, pp. 1–13.
W. C. Chiang, J. S. Wang, and Y. L. Hsu, “A Music Emotion Recognition Algorithm with Hierarchical SVM Based Classifiers,” in 2014 International Symposium on Computer, Consumer and Control, 2014, pp. 1249–1252.
J. Bai et al., “Music Emotion Recognition by Cognitive Classifcation Medthodologies,” in 2017 IEEE 16th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), 2017, pp. 121–129.
P. M. F. Vale, “The Role of Artist and Genre on Music Emotion Recognition,” Universidade Nova de Lisboa, 2017.
K. Trohidis and G. Kalliris, “Multi-Label Classification of Music Into Emotions,” in 9th International Society for Music Information Retrieval Conference (ISMIR 2008), 2008, pp. 325–330.
S. Nalini, N J and Palanivel, “Emotion Recognition in Music Signal using AANN and SVM,” Int. J. Comput. Appl., vol. 77, no. 2, pp. 7–14, 2013.
J. Wang and S. Xin, “Emotional Classification Based on The Tempo and Mutation Degrees,” in 2013 2nd International Symposium on Instrumentation and Measurement, Sensor Network and Automation (IMSNA), 2013, pp. 444–446.
Y. Deng, Y. Lv, M. Liu, and Q. Lu, “A Regression Approach to Categorical Music Emotion Recognition,” in 2015 IEEE International Conference on Progress in Informatics and Computing (PIC), 2015, pp. 257–261.
B. K. Baniya, C. S. Hong, and J. Lee, “Nearest Multi-Prototype Based Music Mood Classification,” in 2015 IEEE/ACIS 14th International Conference on Computer and Information Science, ICIS 2015 - Proceedings, 2015, pp. 303–306.
S. R. Livingstone and A. R. Brown, “Dynamic Response: Real-Time Adaptation for Music Emotion,” in 2nd Australasian Conference on Interactive Entertainment, 2005, pp. 105–111.
S. R. Livingstone, A. R. Brown, and R. Muhlberger, “Influencing the Perceived Emotions of Music with Intent,” in Proceedings of the Third International Conference on Generative Systems in the Electronic Arts, 2005, pp. 161–170.
S. R. Livingstone and W. F. Thompson, “Multimodal Affective Interaction A Comment on Musical Origins,” Music Percept., vol. 24, no. 1, pp. 89–94, 2006.
S. R. Livingstone, R. Mühlberger, A. R. Brown, and A. Loch, “Controlling Musical Emotionality: An Affective Computational Architecture for Influencing Musical Emotions,” Digit. Creat., vol. 18, no. 1, pp. 43–53, 2007.
“Audioblocks.com.” [Online]. Available: https://www.audioblocks.com/. [Accessed: 08-Mar-2018].
H. H. C. Yi-Hsuan Yang, Yu-Ching Lin, Ya-Fan Su, “A Regression Approach to Music Emotion Recognition,” IEEE Trans. Audio. Speech. Lang. Processing, vol. 16, no. 2, pp. 448–457, 2008.
K. Hevner, “Expression in Music: A Discussion of Experimental Studies and Theories,” Psychol. Rev., vol. 42, no. 2, pp. 186–204, 1935.
Russell James A., “A Circumplex Model of Affect,” J. Pers. Soc. Psychol., vol. 39, no. 6, pp. 1161–1178, 1980.
J. A. Russell, “Culture and The Categorization of Emotions.,” Psychol. Bull., vol. 110, no. 3, pp. 426–450, 1991.
T. Eerola and J. K. Vuoskoski, “A Comparison of The Discrete and Dimensional Models of Emotion in Music,” Psychol. Music, vol. 39, no. 1, pp. 18–49, 2011.
Y. E. Kim et al., “Music Emotion Recognition : a State of The Art Review,” in 11th International Society for Music Information Retrieval Conference (ISMIR 2010), 2010, pp. 255–266.
Y. Yang and H. H. Chen, “Machine Recognition of Music Emotion : A Review,” ACM Trans. Intell. Syst. Technol., vol. 3, no. 40, 2012.
H. Cheng, Y. Yang, Y. Lin, I. Liao, and H. H. Chen, “Automatic Chord Recognition for Music Classification and Retrieval,” in 2008 IEEE International Conference on Multimedia and Expo (ICME) (2008), 2008, vol. 0, pp. 1505–1508.
J. Kim and E. André, “Emotion Recognition Based on Physiological Changes in Music Listening,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 30, no. 12, pp. 2067–2083, 2008.
F. Weninger, F. Eyben, and B. Schuller, “On-line Continuous-Time Music Mood Regression with Deep Recurrent Neural Networks,” ICASSP, IEEE Int. Conf. Acoust. Speech Signal Process. - Proc., vol. 338164, no. 338164, pp. 5412–5416, 2014.
S. Fukayama and M. Goto, “Music Emotion Recognition With Adaptive Aggregation of Gaussian Process Regressors,” Icassp 2016, pp. 71–75, 2016.
M. Malik, S. Adavanne, K. Drossos, T. Virtanen, D. Ticha, and R. Jarina, “Stacked Convolutional and Recurrent Neural Networks for Music Emotion Recognition,” 2017. [Online]. Available: http://arxiv.org/abs/1706.02292.
V. L. Nguyen, D. Kim, V. P. Ho, and Y. Lim, “A New Recognition Method for Visualizing Music Emotion,” vol. 7, no. 3, pp. 1246–1254, 2017.
X. Hu and Y.-H. Yang, “The Mood of Chinese Pop Music: Representation and Recognition,” Int. Rev. Res. Open Distance Learn., pp. 90–103, 2017.
K. Sorussa, A. Choksuriwong, and M. Karnjanadecha, “Acoustic Features for Music Emotion Recognition and System Building,” in Proceedings of the 2017 International Conference on Information Technology - ICIT 2017, 2017, pp. 413–417.
E. Çano and M. Morisio, “MoodyLyrics: A Sentiment Annotated Lyrics Dataset,” in Proceedings of the 2017 International Conference on Intelligent Systems, Metaheuristics & Swarm Intelligence - ISMSI ’17, 2017, pp. 118–124.
E. Çano and M. Morisio, “Music Mood Dataset Creation Based on Last.fm Tags,” in 4th International Conference on Artificial Intelligence and Applications (AIAP 2017), 2017, pp. 15–26.
Y. Chen, Y. Yang, J. Wang, and H. Chen, “The AMG1608 Dataset for Music Emotion Recognition,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 693–697.
X. Hu and Y.-H. Yang, “Cross-dataset and Cross-cultural Music Mood Prediction: A Case on Western and Chinese Pop Songs,” IEEE Trans. Affect. Comput., vol. 8, no. 2, pp. 1–1, 2016.
“Free Music Archive.” [Online]. Available: http://freemusicarchive.org/. [Accessed: 07-Nov-2018].
“Jamendo Music.” [Online]. Available: https://www.jamendo.com/. [Accessed: 07-Nov-2018].
R. Bittner, J. Salamon, M. Tierney, M. Mauch, C. Cannam, and J. Bello, “MedleyDB: A Multitrack Dataset for Annotation - Intensive MIR Research,” in International Society for Music Information Retrieval Conference, 2014, no. Ismir, pp. 155–160.
A. Aljanaki, Y. H. Yang, and M. Soleymani, “Developing a Benchmark for Emotional Analysis of Music,” PLoS One, vol. 12, no. 3, pp. 1–22, 2017.
M. Soleymani, A. Aljanaki, and Y.-H. Yang, “DEAM: MediaEval Database for Emotional Analysis in Music,” 2016. [Online]. Available: http://cvml.unige.ch/databases/DEAM/manual.pdf. [Accessed: 08-Mar-2018].
“DEAM Dataset Release Page.” [Online]. Available: http://cvml.unige.ch/databases/DEAM. [Accessed: 01-Jun-2017].
O. Lartillot and P. Toiviainen, “A MATLAB Toolbox for Musical Feature Extraction from Audio,” in Proc. of the 10th Int. Conference on Digital Audio Effects (DAFx-07), 2007, pp. 1–8.
T. Eerola and P. Toiviainen, “MIR in MATLAB: The Midi Toolbox,” in International Society for Music Information Retrieval Conference (ISMIR), 2004, pp. 22–27.
M. Müller and S. Ewert, “MIR Toolbox Release Page.” [Online]. Available: https://www.jyu.fi/hytk/fi/laitokset/mutku/en/research/materials/mirtoolbox. [Accessed: 05-Jul-2017].
D. Moffat, D. Ronan, and J. D. Reiss, “An Evaluation of Audio Feature Extraction Toolboxes,” in Proc. of the 18th Int. Conference on Digital Audio Effects (DAFx-15), 2015, pp. 1–7.
H. Bowen et al., Eds., “The Element of Classical Music,” in The Compleate Classical Music Guide, 1st ed., New york: Dorling Kindersley Limited, 2012, pp. 10–17.
B. P. F. William H. Press, Saul A. Teukolsky, William T. Vetterling, “Chapter 14.5 Linear Correlation,” in Numerical Recipes in C, 2nd ed., Cambridge University Press, 1992, pp. 636–639.
K. Levenberg, “A Method for The Solution of Certain Non Linear Problems In Least Squares,” Q. Appl. Math., vol. 2, pp. 164–168, Jan. 1944.
D. W. Marquardt, “An Algorithm for Least-Squares Estimation of Nonlinear Parameters,” J. Soc. Ind. Appl. Math., vol. 11, no. 2, pp. 431–441, Jun. 1963.
M. T. Hagan and M. B. Menhaj, “Training Feedforward Networks with The Marquardt Algorithm,” IEEE Trans. Neural Networks, vol. 5, no. 6, pp. 989–993, 1994.
M. Riedmiller, M. Riedmiller, and H. Braun, “RPROP - A Fast Adaptive Learning Algorithm,” in PROC. OF ISCIS VII), UNIVERSITAT, 1992.
M. Riedmiller and H. Braun, “A Direct Adaptive Method for Faster Backpropagation Learning: The RPROP Algorithm,” in IEEE International Conference on Neural Networks, 1993, pp. 586–591.
M. H. Beale, M. T. Hagan, and H. B. Demuth, Neural Network ToolboxTM Reference. 3 Apple Hill Drive: Mathwork inc, 2017.
M. H. Beale, M. T. Hagan, and H. B. Demuth, Neural Network ToolboxTM User’s Guide. 3 Apple Hill Drive: Mathwork inc, 2017.
H. Liu, J. Hu, and M. Rauterberg, “Music Playlist Recommendation Based on user Heartbeat and Music Preference,” in 2009 International Conference on Computer Technology and Development (ICCTD 2009), 2009, vol. 1, pp. 545–549.
S.-W. Hsiao, S.-K. Chen, and C.-H. Lee, “Methodology for Stage Lighting Control Based on Music Emotions,” Inf. Sci. (Ny)., vol. 412–413, pp. 14–35, 2017.
