
Isarn Dialect Speech Synthesis using HMM with syllable-context features
Article Sidebar
Main Article Content
Abstract
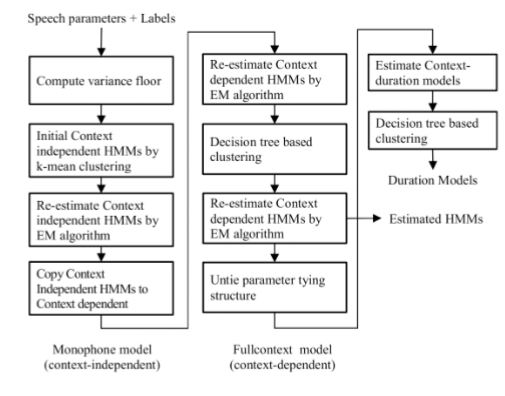
This paper describes the Isarn speech synthesis system, which is a regional dialect spoken in the Northeast of Thailand. In this study, we focus to improve the prosody generation of the system by using the additional context features. In order to develop the system, the speech parameters (Mel-ceptrum and fundamental frequencies of phoneme within different phonetic contexts) were modelled using Hidden Markov Models (HMM). Synthetic speech was generated by converting the input text into context-dependent phonemes. Speech parameters were generated from the trained HMM, according to the context-dependent phonemes, and were then synthesized through a speech vocoder. In this study, systems were trained using three different feature sets: basic contextual features, tonal, and syllable-context features. Objective and subjective tests were conducted to determine the performance of the proposed system. The results indicated that the addition of the syllable-context features significantly improved the naturalness of synthesized speech.
Article Details
References
[2] C. Hamon, E. Mouline, and F. Charpentier, “ A diphone synthesis system based on time-domain prosodic modifications of speech,” in , 1989 International Conference on Acoustics, Speech, and Signal Processing, 1989. ICASSP-89, 1989, pp. 238-241 vol.1.
[3] A. J. Hunt and A. W. Black, “ Unit selection in a concatenative speech synthesis system using a large speech database,” in , 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing, 1996. ICASSP-96. Conference Proceedings, 1996, vol. 1, pp. 373-376 vol. 1.
[4] T. Yoshimura, K. Tokuda, T. Masuko, T. Kobayashi, and T. Kitamura, “ Simultaneous modeling of spectrum, pitch and duration in HMM-based speech synthesis,” Proc EUROSPEECH, vol. 5, pp. 2347-2350, 1999.
[5] K. Tokuda, T. Yoshimura, T. Masuko, T. Kobayashi, and T. Kitamura, “ Speech parameter generation algorithms for HMM-based speech synthesis,” Acoust. Speech Signal Process. IEEE Int. Conf. On , vol. 3, pp. 1315-1318, Jun. 2000.
[6] A. Gutkin, X. Gonzalvo, S. Breuer, and P. Taylor, “ Quantized HMMs for low footprint textospeech synthesis,” in INTERSPEECH 2010, 11th Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September 26-30, 2010, 2010, pp. 837-840.
[7] B. T th and G. Nmeth, “ Optimizing HMM Speech Synthesis for Low-Resource Devices,” J. Adv. Comput. Intell. Intell. Inform. , vol. 16, no. 2, pp. 327-334, Mar. 2012.
[8] T. Nose, J. Yamagishi, T. Masuko, and T. Kobayashi, “ A Style Control Technique for HMM-Based Expressive Speech Synthesis,” IEICE Trans., vol. 90-D, pp. 1406-1413, Sep. 2007.
[9] K. Tokuda, H. Zen, and A. W. Black, “ An HMMbased speech synthesis system applied to English,” in Proceedings of 2002 IEEE Workshop on Speech Synthesis, 2002, 2002, pp. 227-230.
[10] Y. Qian, F. Soong, Y. Chen, and M. Chu, “ An HMM-Based Mandarin Chinese Text-To-Speech
System,” in Chinese Spoken Language Processing, Q. Huo, B. Ma, E.-S. Chng, and H. Li, Eds. Springer Berlin Heidelberg, 2006, pp. 223-232.
[11] S. Chomphan and T. Kobayashi, “ Implementation and evaluation of an HMMbased Thai speech synthesis system,” in INTERSPEECH 2007, 8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium, August 27-31, 2007, 2007, pp. 2849-2852.
[12] H. Ze, A. Senior, and M. Schuster, “ Statistical parametric speech synthesis using deep eural
networks,” in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, 2013, pp. 7962-7966.
[13] Y. Qian, Y. Fan, W. Hu, and F. K. Soong, “ On the training aspects of Deep Neural Network (DNN) for parametric TTS synthesis,” in 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014, pp. 3829-3833.
[14] J. J. Odell, The Use of Context in Large Vocabulary Speech Recognition. 1995.
[15] P. Janyoi and P. Seresangtakul, “ Isarn phoneme transcription using statistical model and transcription rule,” vol. 59, pp. 337-345, 2014.
[16] P. Janyoi and P. Seresangtakul, “ An Isarn dialect HMM-based text-to-speech system,” in 2017 2nd International Conference on Information Technology (INCIT), 2017, pp. 1-6.
[17] C. Haruechaiyasak, S. Kongyoung, and M. Dailey, “ A comparative study on Thai word Segmentation approaches,” in 2008 5th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, 2008, vol. 1, pp. 125-128.
[18] L. Du et al., “ Chinese word segmentation based on conditional random fields with character clustering,” in 2016 International Conference on Asian Language Processing (IALP), 2016, pp. 258-261.
[19] T. P. Nguyen and A. C. Le, “ A hybrid approach to Vietnamese word segmentation,” in 2016 IEEE RIVF International Conference on Computing Communication Technologies, Research, Innovation, and Vision for the Future (RIVF), 2016, pp. 114-119.
[20] N. P. Narendra, K. S. Rao, K. Ghosh, R. R. Vempada, and S. Maity, “ Development of syllable-based text to speech synthesis system in Bengali,” Int. J. Speech Technol., vol. 14, no. 3, pp. 167, Sep. 2011.
[21] S. Luksaneeyanawin, “ A Thai text-to-speech system,” in Proceedings of the Regional Workshop an Computer Processing of Asian Languages (CPAL), Asian Institute of Technology, 1989, pp. 305-315.
[22] A. P. Dempster, N. M. Laird, and D. B. Rubin, “ Maximum Likelihood from Incomplete Data via the EM Algorithm,” 1976.
[23] H. Zen et al., “ Recent development of the HMMbased speech synthesis system (HTS),” 2009.
[24] K. Shinoda and T. Watanabe, “ MDL-based context-dependent subword modeling for speech recognition,” Acoust. Sci. Technol., vol. 21, no. 2, pp. 79-86, Jan. 2001.
[25] A. Stan, J. Yamagishi, S. King, and M. Aylett, “ The Romanian speech synthesis (RSS) corpus: Building a high quality HMM-based speech synthesis system using a high sampling rate,” Speech Commun. , vol. 53, no. 3, pp. 442-450, Mar. 2011.
[26] M. Morise, F. Yokomori, and K. Ozawa, “ WORLD: A Vocoder-Based High-Quality Speech Synthesis System for Real-Time Applications,” IEICE Trans. Inf. Syst., vol. E99.D, no. 7, pp. 1877-1884, Jul. 2016.
[27] W. B. Kleijn and K. K. Pailwal, “ A Robust Algorithm for Pitch Tracking (RAPT),” in Elsevier, 1995, pp. 495-518.
